Здравствуйте, гость ( Вход | Регистрация )

  |

 9.10.2015 - 00:59 9.10.2015 - 00:59
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
Здравствуйте, уважаемые! Помогите со следующим вопросом, в постановки задачи использую медицинскую трактовку.
Известно что вероятность выздоровления от некой болезни равна 0,17. Некто применив опытный препарат, добился выздоровления 4-х больных в группе из 10-ти человек. По какому критерию можно проверить гипотезу о реальном действии этого препарата? На самом деле получен эффект, или результат входит в зону статистического разброса? Спасибо. |
 |
 
|


 |
|
|
9.10.2015 - 09:30
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 219 Регистрация: 4.06.2013 Из: Тверь Пользователь №: 24927 |
Биномиальный критерий: значимость 0,074.
Мощность критерия - 0,29. Для достижения мощности 0,8 нужно не менее 30 наблюдений. Сообщение отредактировал anserovtv - 9.10.2015 - 09:31 |
|
|
|

|
|
|
9.10.2015 - 12:18
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Диагностик @ 9.10.2015 - 00:59)  Здравствуйте, уважаемые! Помогите со следующим вопросом, в постановки задачи использую медицинскую трактовку. Известно что вероятность выздоровления от некой болезни равна 0,17. Некто применив опытный препарат, добился выздоровления 4-х больных в группе из 10-ти человек. По какому критерию можно проверить гипотезу о реальном действии этого препарата? На самом деле получен эффект, или результат входит в зону статистического разброса? Спасибо. Всегда полезно начать с бустрепа Код > cumsum(table(replicate(500000, 4-sum(sample(c(1,0), 10, replace=T, prob=c(0.17, 0.83)))))/500000) -5 -4 -3 -2 -1 0 1 2 0.000002 0.000032 0.000310 0.002680 0.016972 0.074242 0.233534 0.526848 3 4 0.844584 1.000000 И тут действительно 0.074242 А вот превышение контроля над опытом будет достигнуто Код cumsum(table(replicate(500000, -sum(sample(d, replace=T))+sum(sample(c(1,0), 10, replace=T, prob=c(0.17, 0.83)))))/500000) -10 -9 -8 -7 -6 -5 -4 -3 0.000012 0.000260 0.002432 0.012868 0.046812 0.127544 0.270548 0.463350 -2 -1 0 1 2 3 4 5 0.662684 0.823728 0.924762 0.974092 0.992732 0.998286 0.999692 0.999962 6 7 0.999994 1.000000 в 0.924762 доле экспериментов "2 группы по 10"  |
|
|
|
|
|
|
9.10.2015 - 16:00
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
Цитата(p2004r @ 9.10.2015 - 17:18) Всегда полезно начать с бустрепа Кому, и для чего? Меня интересуют вполне адекватные критерии. Сообщение отредактировал Диагностик - 9.10.2015 - 16:04 |
|
|
|
|
|
|
9.10.2015 - 16:17
Сообщение
#5
|
|
 Группа: Пользователи Сообщений: 1114 Регистрация: 10.04.2007 Пользователь №: 4040 |
Цитата(Диагностик @ 9.10.2015 - 00:59) Известно что вероятность выздоровления от некой болезни равна 0,17. Есть данные, в группе какой численности получено число 0,17? Ход мыслей таков - я веду к сравнению долей. http://www.apteka.ua/article/14437 Сообщение отредактировал Игорь - 9.10.2015 - 16:28 Ebsignasnan prei wissant Deiws ainat! As gijwans! Sta ast stas arwis!
|
|
|
|
|
|
|
9.10.2015 - 16:31
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
Цитата(Игорь @ 9.10.2015 - 21:17) Есть данные, в группе какой численности получено число 0,17? Считайте что к очень многочисленной. Рассматривается задача не о проверки гипотезы принадлежности двух выборок к одному распределению, а в проверке гипотезы о принадлежности одной выборки к известному распределению. Сообщение отредактировал Диагностик - 9.10.2015 - 16:35 |
|
|
|
|
|
|
9.10.2015 - 17:29
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Диагностик @ 9.10.2015 - 16:00) Кому, и для чего? Меня интересуют вполне адекватные критерии. Для того кто не хочет всякий бред потом публиковать естественно. Ну опубликуйте свое мнение что бутстреп "неадекватный критерий" "в печати", повеселите публику. |
|
|
|
|
|
|
9.10.2015 - 18:21
Сообщение
#8
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
Цитата(p2004r @ 9.10.2015 - 22:29) Ну опубликуйте свое мнение что бутстреп "неадекватный критерий" "в печати", повеселите публику. Вы уже публиковали обратное? Публика веселилась? |
|
|
|
|
|
|
9.10.2015 - 19:39
Сообщение
#9
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
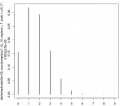
Цитата(Диагностик @ 9.10.2015 - 18:21) Вы уже публиковали обратное? Публика веселилась? Это за меня опубликовали другие люди (и довольно давно, так что пора "вылазить из дупла"  , например Эфрон ( https://en.wikipedia.org/wiki/Bradley_Efron ) . , например Эфрон ( https://en.wikipedia.org/wiki/Bradley_Efron ) .А учебный случай который вы предложили разобрать очень прост (если конечно считать не важным нечеткую формулировку). Вы предлагаете как H0 генсовокупность с матожиданием 0.17 "выздоровления" против состояния "болезнь", из которой была извлечена выборка размером 10. Это собственно и есть Код sample(c(1,0), 10, replace=T, prob=c(0.17, 0.83)) как извлечение одной такой выборки. Извлекая таких выборок много (500000) и подсчитывая сколько "выздоровлений" произошло, мы получаем распределение генсовокупности с матожиданием болезни 0.17 для размера выборки 10. Код plot(table(replicate(500000, sum(sample(c(1,0), 10, replace=T, prob=c(0.17, 0.83)))))/500000) Некто получил 4 случая "выздоровления" из 10 и нам надо посчитать насколько это случайно. И тут задача сводиться к ситуации "какова вероятность получить 4 и более случаев при вероятность выздоровления 0.17" Код > cumsum(rev(table(replicate(500000, sum(sample(c(1,0), 10, replace=T, prob=c(0.17, 0.83)))))/500000)) 9 8 7 6 5 4 3 2 0.000002 0.000012 0.000276 0.002674 0.016582 0.073574 0.233256 0.527852 1 0 0.845112 1.000000 И достижение 4 и более "выздоровевших" происходит с вероятностью 0.073574 Вот с мощностью вопрос. Её по определению считаем из бета ошибок распределения которое заявлено для H1. Код > d <- c(rep(1,4), rep(0, 10-4)) > d [1] 1 1 1 1 0 0 0 0 0 0 > 1 - cumsum(table(replicate(500000, sum(sample(d, replace=T))))/500000) 0 1 2 3 4 5 6 7 0.993854 0.953564 0.833100 0.618356 0.367922 0.166198 0.054828 0.012326 8 9 10 0.001588 0.000110 0.000000 > 1 - cumsum(table(replicate(500000, sum(sample(d, replace=T))))/500000) 0 1 2 3 4 5 6 7 0.993934 0.953680 0.833478 0.619520 0.368914 0.167292 0.055216 0.012122 8 9 10 0.001616 0.000098 0.000000 никак не менее 0.36 мощность получается для подтверждения 4х случаев выздоровления для выборки размером 10. Но для 3 случаев "выздоровления" уже частота обнаружения (мощность) 0.61.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
9.10.2015 - 22:47
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 1114 Регистрация: 10.04.2007 Пользователь №: 4040 |
Цитата(Диагностик @ 9.10.2015 - 16:31) Считайте что к очень многочисленной. Ссылку дайте, я сам посмотрю. Цитата(Диагностик @ 9.10.2015 - 16:31) Рассматривается задача не о проверки гипотезы принадлежности двух выборок к одному распределению, Такая постановка вопроса позволяет использовать непараметрический тест. Вы ссылку на украинский источник посмотрели? Цитата(Диагностик @ 9.10.2015 - 16:31) а в проверке гипотезы о принадлежности одной выборки к известному распределению. А такая - параметрический. Тогда необходимо уточнить - к какому? Какими параметрами описывается данное распределение? Ebsignasnan prei wissant Deiws ainat! As gijwans! Sta ast stas arwis!
|
|
|
|
|
|
|
10.10.2015 - 08:33
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
р2004r, вы так ловко оперируете мощностью критерия что я поражён. К своему сожалению, я до такого ещё не дорос. По моей задаче какое будет решение?
|
|
|
|
|
|
|
10.10.2015 - 08:35
Сообщение
#12
|
|
|
Группа: Пользователи Сообщений: 143 Регистрация: 4.09.2012 Пользователь №: 24146 |
Цитата(Игорь @ 10.10.2015 - 03:47) А такая - параметрический. Тогда необходимо уточнить - к какому? Какими параметрами описывается данное распределение? n=10, р=0,17. |
|
|
|
|
|
|
10.10.2015 - 08:54
Сообщение
#13
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Диагностик @ 10.10.2015 - 08:33) р2004r, вы так ловко оперируете мощностью критерия что я поражён. К своему сожалению, я до такого ещё не дорос. По моей задаче какое будет решение? Если проведенный опыт должен подтвердить именно "минимум 4 из 10", то выборка размером 10 случаев дает вероятность обнаружить это 0.36. Если вопрос состоит "получить случаев выздоровления в выборке размером 10 больше чем в генсовокупности с вероятностью 0.17", то вероятность обнаружить это 0.92. Очевидно, что раз речь идет о подтверждении эксперимента, то оценить точное значение вероятности "выздороветь" стоит не с помощью проверки гипотезы, а с помощью построения доверительного интервала для вероятности выздороветь по единичному опыту "4 из 10". Вот так доверительный интервал будет сужаться при росте размера выборки. Код > quantile(replicate(500000, sum(sample(d, 10, replace=T))), probs=c(0.025, 0.975)) 2.5% 97.5% 1 7 > quantile(replicate(500000, sum(sample(d, 20, replace=T)))/2, probs=c(0.025, 0.975)) 2.5% 97.5% 2 6 > quantile(replicate(500000, sum(sample(d, 30, replace=T)))/3, probs=c(0.025, 0.975)) 2.5% 97.5% 2.333333 5.666667 > quantile(replicate(500000, sum(sample(d, 40, replace=T)))/4, probs=c(0.025, 0.975)) 2.5% 97.5% 2.5 5.5 > quantile(replicate(500000, sum(sample(d, 50, replace=T)))/5, probs=c(0.025, 0.975)) 2.5% 97.5% 2.6 5.4 > quantile(replicate(500000, sum(sample(d, 100, replace=T)))/10, probs=c(0.025, 0.975)) 2.5% 97.5% 3.1 5.0 А если задастся именно уровнем ошибок I рода около 5%, то достигается мощность 80% при размере выборки около 30 (наблюдается не менее 9 "выздоровлений"). Код > cumsum(rev(table(replicate(500000, sum(sample(c(1,0), 30, replace=T, prob=c(0.17, 1-0.17)))))/500000))
16 15 14 13 12 11 10 9 0.000008 0.000038 0.000166 0.000620 0.002326 0.007734 0.022162 0.056192 8 7 6 5 4 3 2 1 0.123548 0.237848 0.401208 0.593662 0.774332 0.904724 0.973418 0.996230 0 1.000000 > 1-cumsum(table(replicate(500000, sum(sample(c(1,0), 30, replace=T, prob=c(0.4, 1-0.4)))))/500000) 1 2 3 4 5 6 7 8 0.999996 0.999956 0.999660 0.998496 0.994272 0.982776 0.956062 0.905318 9 10 11 12 13 14 15 16 0.822962 0.707704 0.568512 0.421056 0.285846 0.175272 0.096544 0.047998 17 18 19 20 21 22 23 24 0.021244 0.008220 0.002742 0.000804 0.000170 0.000036 0.000006 0.000000 Сообщение отредактировал p2004r - 12.10.2015 - 13:32 |
|
|
|
|
|
|