Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум врачей-аспирантов _ Медицинская статистика _ Критерий для анализа сверхмалых выборок
Автор: Vitek_22 25.05.2022 - 12:45
Салют! Столкнулся с проблемой сравнения двух выборок, в каждой из которых по 3 значения. Это результаты иммуноблоттинга (определение концентрации целевого белка в пробе) очень ценных образцов, полученных от трансгенных животных. Но их - образцов, было всего 3 для каждой из групп (2 группы: интактная и подвергнутая воздействию исследуемого фактора). Покопавшись в литературе, нашёл статьи, где есть такие выборки и авторы как ни в чём не бывало используют t-критерий Стьюдента для сравнения средних. Нашёл статьи, где используют U-критерий Манна-Уитни... Скажем так, в биологии 3 образца - это нормально для публикации, если речь идёт об особо ценном и сложнополучаемом биоматериале (к примеру как у меня, когда животные практически не дают потомства). Т.е. представить эти данные можно и не стыдно. Но вот как сравнить, как показать, что эти выборки отличаются статистически значимо, иными словами, что наш исследуемый фактор значимо повлиял на концентрацию целевого белка?
Почитал ещё о таком методе, как ресамплинг или бутстреп, когда объём выборки искусственно увеличивают. Ну, не знаю насколько это правильно... также не нашёл софт и чёткого понимания как это сделать у меня нет.
Работаю в проге Statistica 12
Посоветуйте, как всё же обработать эти данные. Вот пример исходных цифр:
Выборка 1:
221,60112
305,217725
295,251684
Выборка 2:
371,3313
397,452722
437,212724
Автор: Игорь 26.05.2022 - 08:42
В принципе любая непараметрика. Можно посмотреть критерий рандомизации для независимых или для связанных выборок (он же критерий рандомизации компонент Фишера, он же критерий рандомизации Фишера-Питмана). На русском языке в справочнике Руниона хорошо описан.
Автор: Vitek_22 26.05.2022 - 10:41
Игорь, спасибо. А как обосновать использование этого критерия?
В Statistica 12 не нашёл Fisher-Pitman permutation test. Какую программу посоветуете для расчёта?
Автор: 100$ 26.05.2022 - 17:46

Утилитарными соображениями:
- асимптотическое распределение здесь не подойдет, т.к. выборки уж очень малы;
- если допредельное распределение можно вычислить точно, значит, так и надо поступить.
Для вашей цифири асимптотический двусторонний достигнутый уровень значимости критерия Манна - Уитни (нормальная аппроксимация) - р=0,05.
Точный двусторонний - р=0,1.
Нулевая гипотеза на 5%-ном уровне значимости не отвергается.
Из более-чем-тыщестраничной монографии Д.Шескина в свое время вынес рекомендацию, восходящую к кому-то из великих, что если заменить числовые значения выборочных данных их рангами, и на этих рангах проделать двухвыборочный тест Стьюдента, до достигнутый уровень значимости очень похож на таковой, полученный при применении критерия Манна - Уитни. В вашем случае тест Стьюдента с неизвестными неравными дисперсиями дает двустороннее р=,021213.
Нулевая гипотеза отвергается на 5%-ном уровне значимости.
Критерий Лемана - Розенблатта (асимптотический) р=,034.
Критерий Смирнова (асимптотический) р=,04.
Ван дер Вардена (асимптотический) р=,055.
В общем, красота.
Автор: Игорь 31.05.2022 - 07:07
1. Пробная 30-дневная версия StatXact.
2. AtteStat (работает как надстройка 32-разрядной Excel для Windows).
3. В R есть функция twoSamplePermutationTestLocation.
Автор: ИНО 5.06.2022 - 23:55
Вот-только при помощи перестановок Вы никогда не достигните уровня значимости ниже 0,05 при столь малых объемах выборок, независимо от величины различий. Иллюстрация (на R):
group<-factor(c(rep(1,3), rep(2, 3)))
df<-data.frame(x, group)
library(coin)
oneway_test(x~group, data=df, distribution="exact")
wilcox_test(x~group, data=df, distribution="exact", conf.int=T)
# Обратите внимание, что границы 95% доверительного интервала для медианной разности не определены.
#Понизим доверительный уровень:
wilcox_test(x~group, data=df, distribution="exact", conf.int=T, conf.level = 0.9)
# Нижняя границы 90% ДИ определена, верхняя - бесконечность.
# А теперь фокус-покус:
df2<-df
df2$x[4:6]<-df$x[4:6]*100000
#Этим мы увеличили значения всех вариант выборки ?2 в сто тысяч раз, то есть смоделировлан случай, когда и безо всякого статанализа колоссальные различия в параметрах положения распределений очевидны.
# Парадоксально, но уровень значимости точных тестов не поменялся:
oneway_test(x~group, data=df2, distribution="exact")
wilcox_test(x~group, data=df2, distribution="exact")
# А все потому, что тестовая статистика при перестановке может принимать всего лишь 20 значений:
choose(6, 3)
# Так что использование рандомизации для решения данной конкретной задачи - так себе идея.
# А вот бутсреп работает:
library(confintr)
ci_mean_diff(x=df$x[1:3], y=df$x[4:6], type="boot", boot_type="bca", R=99999)
# Более того, даже 99,9% ДИ для разности средних не включает 0:
ci_mean_diff(x=df$x[1:3], y=df$x[4:6], type="boot", boot_type="bca", probs =c(0.0005, 0.9995), R=99999)
# То есть гипотеза о равенстве математических ожиданий откланяется на уровне значимости 0,001, чего, если я правильно понял, и желает ТС.
Насколько это соответсвует истине, не берусь судить, я вообще слабо понимаю идею бутстрепа, в отличие от рандомизации, но обычно BCa хвалят. Но все же я не встречал ни одного сравнительного исследования статистических методов на столь малых выборках. Обычно начинают от 6 - 7. Тестировал ли Эфрон свой BCa на 3 и 3?
Автор: Игорь 9.06.2022 - 13:53
Выборка 1:
221,60112
305,217725
295,251684
Выборка 2:
371,3313
397,452722
437,212724
StatXact и AtteStat проверить не удалось, ибо для первого нужна ОС Windows, а для второго еще и Excel. Поэтому взял StatAnt. В доступной для скачивания версии критерия рандомизации нет, но он есть в используемой в проекте (также и в AtteStat) библиотеке ME.com. Поэтому добавил пару строчек в StatAnt. Результат для предложенных данных:
Часть 2: Статистика двух выборок
Численность первой выборки 3
Численность второй выборки 3
Параметрические критерии
Критерий Стьюдента (положение): t = 3.92672, p = 0.991425
Критерий Пагуровой (положение): t = 3.92672, p = 0.0134883
Парный критерий Стьюдента (положение): t = 7.10564, p = 0.990382
F-критерий Фишера (рассеяние): t = 1.89526, p = 0.345392
Коэффициент корреляции Пирсона: r = 0.730407, p = 0.76067
95% доверительный интервал = [-1; 1]
Непараметрические критерии
Критерий Вилкоксона (положение): t = 6, p = 0.959572
Критерий Муда-Брауна (положение): t = 0, p = 0.0126737
Критерий Ансари-Бредли (рассеяние): t = 6, p = 0.5
Критерий Клотца (рассеяние): t = 1.49241, p = 0.5
Критерий Зигеля-Тьюки (рассеяние): t = 10, p = 0.41363
Permutation tests
Fisher-Pitman permutation test (independent samples): t = 1, p = 0.05
На выбор теста могут оказывать помимо математических соображений еще и социальные.
Автор: ИНО 9.06.2022 - 16:05
Сдается мне, Ваше творение нагло врет, по крайней мере, по некоторым тестам, включая, как ни странно, Стьюдента.
group<-factor(c(rep(1,3), rep(2, 3)))
df<-data.frame(x, group)
Классический Стьюдент:
Two Sample t-test
data: x by group
t = -3.9267, df = 4, p-value = 0.01715
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-218.46228 -37.48854
sample estimates:
mean in group 1 mean in group 2
274.0235 401.9989
Уэлч:
Welch Two Sample t-test
data: x by group
t = -3.9267, df = 3.6509, p-value = 0.02041
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-221.97871 -33.97211
sample estimates:
mean in group 1 mean in group 2
274.0235 401.9989
C Фишером-Питманом тоже несоответствие, однако там может быть нюанс в способе подсчета p. Остальные не проверял. Кстати, часть из них в данной ситуации применять было просто бессмысленно из-за грубого нарушения допущений, например Ансари-Бредли и все парные. И Аттестат, помнится, тоже нагло врал местами, как минимум, с критерием Барнарда (неправильный выбор мешающего параметра) и Лемана-Розенблатта (пропущена сортировка вариант по возрастанию). Но, по крайней, мере Стьюдента и Фишера-Питмана он выдавал так же, как R и прочие широкоизвестные.
Не сочтите за критиканство, это лишь свидетельство что когда один программист работает над б. м. сложным и объемным продуктом, который кроме него не тестирует более никто, то результат закономерно печален.
Автор: 100$ 9.06.2022 - 16:17
У вас ошибочка вышла.
СТЬЮДРАСП(3,92672;4;2)=,01715.
Проще говоря, для рассматриваемого случая корректно будет
p (one-sided)=1-,991425= ,008575
p (two-sided)=2*(1-,991425)= ,01715.
Нулевая гипотеза на 5%-ном уровне отвергается со свистом.
Статистика - это вам не лобио кушать...
P.S. И вообще, Стьюдент и Пагурова здесь равны 3,926626.
P.P.S. Пока писал, ИНО уже обратил на это внимание.
Автор: Игорь 9.06.2022 - 20:08
Спасибо коллегам за подробный разбор. Проверил. Сначала огорчился. Но при анализе ошибок не обнаружил ни в своем посте, ни в постах уважаемых коллег (сделал небольшую поправку в документацию). Грубо говоря - одно и то же. Исправлять нечего. Следовало бы, конечно, пояснить, что такое p в листинге. В AtteStat это сделано, в том числе в руководстве, в StatAnt - нет. Последний проект вообще специфический - он был сделан не для пользователей, а для быстрой отладки расчетных методов студентами, использовался в качестве основы для пары дипломных проектов (продвинутые факторный анализ и разложения временных рядов - результаты в проект не вошли). Про Барнарда и Лемана-Розенблатта не могу согласиться - в текущем виде всё в порядке. Хотя за давностью уже не помню - возможно, какие-то версии и попали в состоянии отладки. Последняя на sourceforge лежит, пока не выгнали.
Впрочем, оба проекта давно (лет 7) не развиваются, не тестируются, известные ошибки не исправляются. Просто никому не нужно.
P.S. Автор отнюдь не наглый. И программы тоже.
Автор: ИНО 9.06.2022 - 22:28
Однак ж... У Вашей новой программы какая-то альтернативная трактовка p, отличная от общепринятой?
Посчитал и понял: StatAnt для Стьюдента выдает 1-p (одностороннее). Понять бы еще зачем. Для конспирации? Особо интересует, почему в случае с Пагуровой прога ведет себя наоборот, то есть, как и положено во всем остальном мире
 Студентов, которым приходится тайну сию объяснять, как-то жалко стало.
Студентов, которым приходится тайну сию объяснять, как-то жалко стало.Версия Аттестата у меня была 13.1. Скачал с этого нехорошего Сорсефоржа версию 13.2. Нехорошего, потому что он сначала подверг обидной дискриминации мой айпишник со словами: "Your request is being denied as it appears to be coming from a location banned by our Terms of Use", поэтому пришлось пользовать прокси. Вдвойне обидно, что все было зря: новая версия не отличается от предыдущей: Леман-Розенблатт без предварительной сортировки выборок по возрастанию все так же показывает погоду на Луне. Барнарда уж проверять не стал. В общем, спасибо за с пользой проведенное время!
P.S. Последние несколько лет единственное, для чего безбоязненно использую Аттестат - транспонирование таблиц. Уж больно оно штатными средствами Экселя муторно делается. Если б Аттестат принимал не только числовые данные, цен б ему не было. А вот для статанализа без предварительных проверок стрёмно - х. з., что он там насчитает. А уж после проверок, если результат сошелся, то уже особого смысла в Аттестате, как легкой кнопочной надстройки Экселя вместо R (кодинг - не мое) особого смысла-то и не остается. Не в обиду будь сказано - просто констатация суровой реальности.
Автор: ИНО 9.06.2022 - 23:21
Почему? У меня Стьюдент получился (почти ручками) (-)3.926721. Нужна поправка какая-то хитрая для малых выборок?
Автор: 100$ 10.06.2022 - 10:08
Ваша правда: я округлил исходные данные. Очень уж лениво было по 4 знака после запятой набивать. Для ранговых методов это несущественно, а параметрика вся исказилась...
Автор: Игорь 10.06.2022 - 13:15
Это результат подстановки значения критерия в обратную функцию распределения. Из-за особенности вычисления нужно смотреть, что именно вычисляется (p, 1-p, 2p и т.п.) и выдавать правильное значение. В AtteStat это сделано. Здесь нет. В-общем это можно сделать в самих функциях распределения, но такого рода промежуточные вычисления используются в других алгоритмах. Резюмируя - считается правильно, выводится не то (не проблема - всё-равно никто не пользуется). Еще один момент - формулировка гипотезы: в общем случае (не для всех тестов) две односторонних и одна двусторонняя. Результат тоже нужно правильно интерпретировать. По идее нужны редизайн приложения и хорошее тестирование. Просто взяться и аккуратно сделать.
Посмотрел, согласился, подправил (пара строчек кода) библиотеку, но исправлять AtteStat не буду - поздно уже. Опять же нет качественно просчитанных примеров для сравнения.
Посмотрел свои записи. Там считается оптимальное значение параметра сначала глобальным поиском, потом уточняется. Не думаю, что в этом месте ошибка, но проверять нужно на хороших данных.
Да согласен абсолютно - давно собирался прикрыть проект, но некоторым он зачем-то нужен. Проверять некому, а это главное. Что-то протестировано неплохо, если кого-то интересовали определенные методы. Создавать новый проект тоже смысла не вижу. Не окупится из-за малой востребованности.
Попутно при нашем обсуждении проблемы пару моментов хотелось упомянуть. Первое - на столь малых выборках будет дикая ошибка второго рода. Достаточно посмотреть функции мощности. Так что результат вычислений можно смело считать чепухой. Интересно, что малые выборки возникают достаточно часто. Например, биохимики мне такие данные приносили, причем в выборке численностью 3-4-5 варианты отличались на 3 порядка. Говорят, что такие данные у них - норма.
Второе (апологетов прошу не обижаться). Если статистику (встроенную) в Excel еще как-то можно посчитать - ну чепуха в документации, да не считаются некоторые распределения - черт с ними, то статистика в Gnumeric и LibreOffice Calc - полный атас. Первый пакет сразу удалил, в статистику во втором сам заходить не буду и другим не посоветую.
Автор: ИНО 10.06.2022 - 14:00
Очевидно, сии подделки экселя прозрачно намекают, что на пути самурая линухоида в статанализе R сам собой разумеется 
Насчет потери мощности на малых выборках, видимо, она особо катастрофична именно перестановочных критериях, если порядок количества возможных уникальных перевыборок равен или меньше 1-альфа. И это в большей степени артефакт метода подсчета p, нежели общая проблема теории статистики. Видимо, надо почитать о возможных методах преодоления. На то, что они существуют, намекают перестановочные тесты в некоторых кнопочных программах, которые в таких случаях выдают что-то, похожее на правду. Например, для рассматриваемой задачи некий "Permutation t test" в PAST выдает p=0,033 (что довольно похоже на p=0,02 двустороннего Уэлча), и я ума не приложу, как он его получает (обычный метод случайной перестановки t-статистики дает все то же p=0,1 +/- сотые, так что в ПАСТе что-то другое). Надо документацию почитать.
Автор: ИНО 11.06.2022 - 15:09
Почитал мануал ПАСТа, относительно "permutation t tes" там сказано:
This is equivalent to using the t statistic. The permutation test is non-parametric with few
assumptions, but the two samples are assumed to be equal in distribution if the null hypothesis is
true. The number of permutations can be set by the user. The power of the test is limited by the
sample size ? significance at the p<0.05 level can only be achieved for n>3 in each sample.
То есть никакого t там в реальности нет, а тупо модуль разности средних. Попробовал повторить это на R:
R<-9999
absdiff<-abs(mean(x[1:3])-mean(x[4:6]))
res<-numeric(R)
for (i in 1:R)
{
perm<-sample(x)
permdiff<-abs(mean(perm[1:3])-mean(perm[4:6]))
if(permdiff>=absdiff) res [i]<-1
}
p<-(sum(res)+1)/(R+1)
p
Получилось уже знакомое p=0,1 с копейками. Откуда они берут p=0,03, тайна сия велика есть.
Автор: 100$ 12.06.2022 - 12:43
А это разовое значение (в смысле, полученное однократно)? Может быть, при повторе расчетов что-то изменится?
Спрашиваю потому, что ваш код из предыдущего поста выдал
- при R=9 999 p=.1028
- при R=99 999 p=.01
- при R=999 999 p=.1029
Поскольку в эксперименте генерируется повторная выборка (т.е. выборка с возвращением), то в строке
perm<-sample(x) желательно уточнить perm<-sample(x,replace=TRUE). Патамушта предельная ошибка повторной и бесповторной выборок вообще-то различаюцца...
Автор: ИНО 13.06.2022 - 19:29
Спрашиваю потому, что ваш код из предыдущего поста выдал
Естественно, "копейки" будут меняться, если set.seed() не задавать. По-хорошему положено для этого p еще и ДИ строить, но это уже для перфекционистов, и на вывод не повлияет. А вывод в данном случае ошибочный.
При классической рандомизации этого не делают: просто случайным образом делят варианты на две выборки, ничего никуда не возвращая. А при replace=TRUE - это уже какой-то гибрид рандомизации с бутстрепом поучится, даже не знаю, бывает ли такой, и какие под ним теоретические основы. Я вообще, сколько не пытался, в теорию бутсрепа не въехал, в конце-концов плюнул, решил, что работает - да и ладно. Но для интереса попробовал свой код с replace=TRUE: получается сильно правдоподобнее, чем просто рандомизация - p=0,027 с копейками, на Уэлча похоже. Но, что интересно, с ПАСТом все равно не совпадает.
Автор: nokh 17.06.2022 - 07:34
Посоветуйте, как всё же обработать эти данные. Вот пример исходных цифр:
Выборка 1:
221,60112
305,217725
295,251684
Выборка 2:
371,3313
397,452722
437,212724
Не знаю почему уважаемые участники форума не поддержали идею критерия Стьюдента и даже посоветовали непараметрику. Непараметрика, конечно, хороша: тот же критерий Манна - Уитни имеет асимптотическую эффективность 3/пи или 95,5%. Но она именно асимптотическая, т.е. в реальности никогда не достигается)) А на сверхмалых выборках потеря в мощности будет просто чудовищной. Поэтому если есть основания предполагать нормальность, ну или хотя бы не отрицать её жёстко, эта дополнительная информация даст большой выигрыш и тогда, оперевшись на параметрику можно показать, что средние в группах отличаются: t(4)=3,92; p=0,017. По представленным 6 цифрам жёстко предполагать ненормальность нет: часто биологические показатели распределены не нормально, а асимметрично и скорее логнормально. Но тогда есть шанс увидеть в данных варьирование на порядок-два, здесь же данные очень компактно группируются, преобразование данных не просится... Короче, я бы посчитал критерием Стьюдента пока, а по мере накопления данных возможно что-то бы пришлось подправить. Напомню, что есть формула критерия Стьюдента даже для сравнения одного единственного наблюдения с выборкой.
По поводу представления средних. Если исходить из нормальности распределения, до можно дать среднее с классическими 95%-ными доверительными интервалами (95% ДИ) : 274,0 [160,6; 387,5] и 402,0 [319,6; 484,4]. Эти ДИ перекрываются (трансгрессируют), что входит в противоречие с идеей наличия различий. А они скорее всего есть, т.к. разность между средними 128,0 имеет 95% ДИ [37,5; 218,5], т.е. не включает ноль, а значит разность ненулевая. Этот 95%-ный ДИ для разности тоже параметрический и вся ситуация говорит о том, что 95% ДИ для средних перекрываются, т.к. рассчитываются изолировано для каждой группы, а ДИ для разности (как и t-критерий Стьюдента) работают с двумя блоками данных одновременно и происходит выигрыш в мощности, который на сверхмалых выборках оказывается решающим.
Можно поиграться и бутстрепом, тогда не будет противоречия ни в ДИ для средних, ни в ДИ для разности:
274,0 [221,6; 305,2] и 402,0 [371,3; 437,2] для процентильного метода, ДИ не перекрываются
Разность 128,0 [75,6; 177,8]
Всё можно посчитать в PAST https://www.nhm.uio.no/english/research/resources/past/

|
Автор: 100$ 17.06.2022 - 12:13
Патамушта уважаемые участники в курсе проблемы Беренса - Фишера.
Поэтому посчитали критерий Уэлча (Welch, 1938), критерий Пагуровой (Пагурова, 1963) и Стьюдента на рангах.
Автор: ИНО 17.06.2022 - 13:17
274,0 [221,6; 305,2] и 402,0 [371,3; 437,2] для процентильного метода, ДИ не перекрываются
Разность 128,0 [75,6; 177,8]
Всё можно посчитать в PAST https://www.nhm.uio.no/english/research/resources/past/
О, новый ПАСТ пермутит по-новому! У меня так:
При том, ни то, ни другое p, я "вручную" повторить не смог. Кстати я так и не понял, в какое ему место заглянуть, чтобы узнать версию своего. Чем Паст хорош - скорость. На своем древнем компе я так и не дождался 999999 псевдовыборок на чистом R, в ПАСТе же оно почти мгновенно происходит. Чем он плох - х. з., что именно считает. Например, методом научного тыка было доказано, что бутсреп-ДИ для разности средних ПАСТ считает вовсе не методом процентилей, как Вы заявляете, а методом basic - наименее ненадежным из существующих.
|
Автор: 100$ 17.06.2022 - 13:26
А что такое метод basic?
Автор: ИНО 17.06.2022 - 17:12
Хороший вопрос! Документация пакета boot (сверяя с которым, я и пришел к вышеозначенному заключению относительно типа ДИ в PAST) лаконично отвечает на него следующее: "The formulae on which the calculations are based can be found in Chapter 5 of Davison and Hinkley (1997)."
Ну и библиографическая ссылка в конце: Davison, A.C. and Hinkley, D.V. (1997) Bootstrap Methods and Their Application, Chapter 5.Cambridge University Press. У меня такой книжки нету.
Но попадались статьи, в которых некий "basic bootstrap CI" нещадно поносили и хвалили BCa. Особо не вникал (учитывая, что, повторяю, саму глубинную идею бутстрепа так и не смог постичь), просто пользовал по возможности BCa. Скажем так, впал в грех слепого следования авторитетам
Немного помоделировал (осбо в это дело не умею, так что, если что не так, тапками не кидайте)
Загрузка "бигдаты" ТС (пожалуй, стоит уже в рабочем пространстве сохранить - как ни крути, классический датасет получился, ирисы Фишера отдыхают) :
y<-c(371.3313, 397.452722, 437.212724)
Генерация 10000 пар выборок из нормальных распределений с похожими параметрами, построение 95% ДИ методом Уэлча и проверка, попадает ли в них истинная разница матожиданий:
res<-rep(0, 10000)
for (i in 1:10000)
{
x_sim<-rnorm(3, mean(x), sd(x))
y_sim<-rnorm(3, mean(y), sd(y))
ci<- t.test(x_sim, y_sim)$conf.int
if(diff>ci[1]&diff<ci[2]) res[i]<-1
}
#Доля попаданий:
sum(res)/10000
Вывод: истинный доверительный уровень на смоделированных данных получился чуть выше номинального, но разница не существенна
Теперь возьмем выборки, каждую из смеси двух нормальных распределений с одинаковыми мю но разными сигмами. Страшненькая формула генератора получена методом тыка, так чтобы стандартные отклонения все еще оставались похожими на оригинал. Если умеете генерировать смеси с заданной дисперсией, замените на свою элегантную:)
res<-rep(0, 10000)
for (i in 1:10000)
{
x_sim<-c(rnorm(2, mean(x), sd(x)*1/3), rnorm(1, mean(x), sd(x)*2/3*2.5))
y_sim<-c(rnorm(2, mean(y), sd(y)*1/3), rnorm(1, mean(y), sd(y)*2/3*2.5))
ci<- t.test(x_sim, y_sim)$conf.int
if(diff>ci[1]&diff<ci[2]) res[i]<-1
}
sum(res)/10000
А здесь уже не все так хорошо: метод Уэлча дает примерно 99% интервал вместо желаемого 95%. И туда уже обычно ноль таки попадает!
Справится ли BCa лучше?
diff<-274-402
res<-rep(0, 1000)
for (i in 1:1000)
{
x_sim<-c(rnorm(2, mean(x), sd(x)*1/3), rnorm(1, mean(x), sd(x)*2/3*2.5))
y_sim<-c(rnorm(2, mean(y), sd(y)*1/3), rnorm(1, mean(y), sd(y)*2/3*2.5))
ci<- ci_mean_diff(x_sim, y_sim, type="boot", boot_type="bca")$interval
if(diff>ci[1]&diff<ci[2]) res[i]<-1
}
sum(res)/1000
Если дождетесь выдачи, сообщите мне. Я не смог, несмотря на то, что урезал количество симуляций до 1000. Можно, конечно, еще и количество псевдовыборок на каждом шаге урезать (параметр R в ci_mean_diff()), но тогда уж совсем как-то неубедительно получится. Философский вопрос: существует ли в мире более медленный язык программирования чем R?
P.S. Таки нашел в Шитиков,Розенберг "Рандомизация и бутстреп:статистический анализ в биологии и экологиис использованием R", что что за бэйзик-интевал такой: это тот же процентильный, но перевернутый относительно среднего. Теоретические основы данной процедуры не понял. Но ,в третий раз повторяю: я и основы бутсрепа вообще плохо понимаю. Но судя по тому, как извращаются с этими интервалами, начиная от переворота в случае бэйзика этого, заканчивая расчетом неких параметров смещения и акселерации в случае BCa, с "восстановлением распределения путем замены одних вариант другими" на самом деле все совсем не так просто, как это иногда преподносят. И интуиция тут работает неважно (моя, по крайней мере).
Автор: 100$ 18.06.2022 - 01:12
При параметре ф-ции t.test(..., var.equal=TRUE)
оценка доверительной вероятности составляет 94,88%, при var.equal=FALSE, да, зашкаливает за 96%.
Эт можно.
С параметром R=999 в ci_mean_diff() при общем числе повторностей=1000 мой комп ковырялся 3,5 мин. Разумеется, при параметре по умолчанию R=9999 ковырялся бы на порядок дольше. Я бы тоже не дождался.
Мой результат
LOW______ UP _____ L________ PROB
-147.78218 -114.44736 33.33482 0.77600
где L- длина полученного интервала (она загуливает совершенно диким образом), PROB=sum(res)/1000 - оценка доверительной вероятности. Она находится в диапазоне ,765 - ,778.
Не хочется превращать мероприятие в форум для программистов, однако для исходных выборок x и y эмпирическая корреляция равна cor(x,y)=.73041, что, конечно, надо учитывать при моделировании системы случайных величин. Конструкция
y_sim<-rnorm(3, mean(y), sd(y))
смотрится просто неприлично.
Автор: ИНО 18.06.2022 - 01:54
Ну что поделать, я не умею толком ни программировать, ни моделировать. Единственное до чего догадался, это если бы мю и сигму один раз затать перед циклом, это б сэкономило несколько секунд. Но то не важно. Львиную долю времени отнимает сi_mean_diff(). Надо поискать, нет ли какого пакета, где бы основную работу по построению бутстреповских ДИ делал бы код си.
У Вас хороший комп. На своем я не дождался и при R=999, покушать успел, вернулся - а воз и ныне там. Но мой комп он очень древний. Однако 999 итераций бутстрепа очень мало для надежной оценки - второй знак после запятой будет играть, если не первый. Так что надо еще пару раз прогнать, чтобы проверить, не превратится ли 0,78 в 0,98. Но ежели нет, то, значит, в данном случае BCa выдает слишком узкий ДИ, а Уэлч (без бутстрепа) - слишком широкий. Причем 0 то входит, то не входит. Если хотите, можете попробовать задать boot_type поочередно "perc", "basic" и "norm" и выбрать, где охват будет ближе к номинальному для данного примера.
Насчет корреляции даже мысли не возникло. По условиям задачи это ж типа две случайные независимые выборки, откуда там ей взяться? Может, случайно вышло просто? Или же ТС (а куда он делся?) что-то не договаривает.
Автор: comisora 18.06.2022 - 17:49
Добрый день.
Предлагаю рассмотреть на жизнеспособность подход из серии "продуктивных методов анализа". Так как данные количественные, минимальное значение концентрации белка 0, а в качестве максимального возьмём самое больше значение из данных обсуждаемого эксперимента. После трансформации данных к диапазону (0, 1), можно выполнить сравнение двух групп через бета-регрессию.
## Создадим данные
a <- c(221.60112, 305.217725, 295.251684)
b <- c(371.3313, 397.452722, 437.212724)
ab <- c(a, b)
n <- length(ab)
g <- rep(c('a', 'b'), time = c(length(a), length(b)))
## Трансформация к диапазону (0; 1)
vec <- scales::rescale_max(ab,
from = c(
1/max(ab)/n,
max(ab)+max(ab)/n
)
)
## Бета-регрессия
fit <- betareg::betareg(vec~g)
emm <- emmeans::emmeans(fit, ~g)
## Средние и ДИ для групп
res <- data.frame(emm, row.names = 'g')[c('emmean', 'asymp.LCL', 'asymp.UCL')]
cev <- apply(res, 2, function(x) scales::rescale_max(x,
to = c(
1/max(ab)/n,
max(ab)+max(ab)/n
),
from = c(0, 1)))
## Разница средних и ДИ
ctr <- data.frame(confint(pairs(emm)))[c('estimate', 'asymp.LCL', 'asymp.UCL')]
rtc <- apply(ctr, 2, function(x) scales::rescale_max(x,
to = c(
1/max(ab)/n,
max(ab)+max(ab)/n
),
from = c(0, 1)))
## Расчёт средних в группах
set.seed(32167)
mean.a <- Hmisc::smean.cl.boot(a, B = 9999)
mean.b <- Hmisc::smean.cl.boot(b, B = 9999)
means <- rbind(cev, mean.a, mean.b)
colnames(means) <- c('mu', 'lwr', 'upr')
## Расчёт разницы средних и ДИ
set.seed(32167)
ci.bca <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'bca')
ci.per <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'perc')
ci.nor <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'norm')
ci.bas <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'basic')
fun_extr <- function(x) { #Для единообразного извлечения
estimate <- x[['estimate']]
interval <- x[['interval']]
result <- c(estimate, interval)
return(result)
}
diffs <- rbind(
beta = rtc,
bca = fun_extr(ci.bca),
perc = fun_extr(ci.per),
norm = fun_extr(ci.nor),
basic = fun_extr(ci.bas)
)
colnames(diffs) <- c('mu', 'lwr', 'upr')
## Выводим результат
summary(fit)
print(means, digits = 5)
print(diffs, digits = 5)
> Call:
betareg::betareg(formula = vec ~ g)
Standardized weighted residuals 2:
Min 1Q Median 3Q Max
-1.7892 -1.0236 0.2118 0.9816 1.5627
Coefficients (mean model with logit link):
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.1480 0.1607 0.921 0.357
gb 1.1632 0.2525 4.606 4.1e-06 ***
Phi coefficients (precision model with identity link):
Estimate Std. Error z value Pr(>|z|)
(phi) 50.91 29.16 1.746 0.0808 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Type of estimator: ML (maximum likelihood)
Log-likelihood: 8.148 on 3 Df
Pseudo R-squared: 0.7817
Number of iterations: 68 (BFGS) + 2 (Fisher scoring)
> mu lwr upr
a 273.88 233.94 313.82
b 401.80 369.21 434.40
mean.a 274.02 221.60 305.22
mean.b 402.00 371.33 437.21
> mu lwr upr
beta -127.92 -179.45 -76.395
bca -127.98 -191.06 -86.850
perc -127.98 -180.40 -78.143
norm -127.98 -180.30 -74.747
basic -127.98 -177.81 -75.553
Судя по результатам, средние и доверительные интервалы, разница средних, которые получены через бета-модель, аналогичны таковым при вычислении через бутстреп. Теперь попробуем повторить анализ для смеси распределений бета-регрессией, разными вариантами бутстрепа. Форма вывода - как у 100$.
##Дополнительные функции #fix
fun_int <- function(x) {
int <- x[['interval']]
return(int)
}
fun_res <- function(data, diff) {
len <- length(data)
res <- vapply(X = 1:n, FUN.VALUE = logical(1),
function(i) {
cond <- diff>data[[i]][1] & diff<data[[i]][2]
return(cond)
}
)
pr <- sum(res)/len
sums <- rowMeans(simplify2array(data))
res <- list(low = sums[1], up = sums[2], l = abs(sums[1]-sums[2]), prob = pr)
return(res)
}
x <- c(221.60112, 305.217725, 295.251684)
y <- c(371.3313, 397.452722, 437.212724)
mu_x <- mean(x)
mu_y <- mean(y)
len_x <- length(x)
sd_x <- sd(x)
sd_y <- sd(y)
len_y <- length(y)
diff <- mu_x-mu_y
len <- len_x+len_y
g <- rep(c('x', 'y'), time = c(len_x, len_y))
idx <- c('asymp.LCL', 'asymp.UCL')
n <- 1000
res <- vector(mode = 'logical', length = n)
set.seed(32167)
x_sim <- replicate(n,
c(
rnorm(round(len_x*2/3), mu_x, sd_x*1/3),
rnorm(round(len_x*1/3), mu_x, sd_x*2/3*2.5)
)
)
y_sim <- replicate(n,
c(
rnorm(round(len_x*2/3), mu_y, sd_y*1/3),
rnorm(round(len_x*1/3), mu_y, sd_y*2/3*2.5)
)
)
xy_sim <- rbind(x_sim, y_sim)
vec_sim <- apply(xy_sim, 2, function(i) scales::rescale_max(i,
from = c(
1/max(i)/len,
max(i)+max(i)/len
)
))
ci_beta <- lapply(
X = 1:n, FUN = function(i) {
fit <- betareg::betareg(vec_sim[,i]~g)
ci <- as.numeric(confint(pairs(emmeans::emmeans(fit, ~g)))[idx])
ic <- scales::rescale_max(ci,
to = c(
1/max(xy_sim[,i])/len,
max(xy_sim[,i])+max(xy_sim[,i])/len
),
from = c(0, 1)
)
return(ic)
})
ci_bca <- lapply(
X = 1:n, FUN = function(i) {
fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i],
type = 'bootstrap', boot_type = 'bca', R = n)
ci <- fun_int(fit)
return(ci)
})
ci_perc <- lapply(
X = 1:n, FUN = function(i) {
fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i],
type = 'bootstrap', boot_type = 'perc', R = n)
ci <- fun_int(fit)
return(ci)
})
ci_norm <- lapply(
X = 1:n, FUN = function(i) {
fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i],
type = 'bootstrap', boot_type = 'norm', R = n) #fix
ci <- fun_int(fit)
return(ci)
})
ci_basic <- lapply(
X = 1:n, FUN = function(i) {
fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i],
type = 'bootstrap', boot_type = 'basic', R = n) #fix
ci <- fun_int(fit)
return(ci)
})
vct <- ls(pattern = 'ci_')
res_ci <- t(simplify2array(lapply(1:length(vct), function(i) {
#do.call(fun_res, list(data = get(vct[i]), diff = get('diff')))
fun_res(data = get(vct[i]), get('diff')) #fix
})))
row.names(res_ci) <- vct
print(res_ci, digits = 5) # fix
low up l prob
ci_basic -173.1 -81.769 91.328 0.885
ci_bca -176.03 -81.595 94.435 0.773
ci_beta -172.44 -79.885 92.552 0.866
ci_norm -174 -80.332 93.666 0.876
ci_perc -172.38 -81.104 91.271 0.814
Автор: ИНО 18.06.2022 - 18:17
ИМХО бета тут как бы совсем за уши притянута, ограничивать сверху эмпирическим максимумом нонсенс. Однако ж, погляди, работает лучше всех, по крайней мере, на этих синтетических данных.
Код крутой, увы, моя такого не понема. Но все ж бросилось глаза, что названия некоторых бутреповских ДИ и их типы перепутаны местами.
Автор: comisora 18.06.2022 - 19:12
2ИНО
Ошибки исправил, результат тоже, спасибо.
Поэтому и написал, что это из серии "продуктивных" методов. Предполагаю, что можно использовать другие максимум и минимумы (например, из данных литературы), zero-one-inflated (gamlss.dist::BEINF) и ещё что-нибудь экзотическое. В моём представлении это не сильно хуже допущения о нормальности распределения или использования уже предложенных подходов к анализу в ходе обсуждения.
Несомненный плюс столь "достоверного" результата - возможность отчитаться за проделанную работу и обосновать необходимость дальнейшего финансирования, чтобы численность обеих выборок довести до 4  .
.
Касательно других обсуждаемых методов - в приложении статья про применимость теста Стьюдента, модификации Уэлча и ранговых преобразований. Может быть кого-то заинтересует.

Автор: 100$ 18.06.2022 - 21:26
>comisora,
а вы можете откомментировать конструкцию do.call?
Такого в листингах, по-моему, себе даже p2004r не позволял )
Автор: comisora 18.06.2022 - 23:53
2 100$
Конечно. Это я усложнил код, так как можно было легко вызвать функцию напрямую (отредактировал код, вставил функции, в т.ч. ту, которую вызывал через do.call).
do.call применяет функцию однократно к списку, в котором находятся аргументы, что равносильно вызову функции. Функция lapply - это цикл, в ходе которого функция вызывается для каждого элемента списка, просто реализованный в компактом виде. Примеры:
## Сумма
do.call(sum, list(c(1, 2, 4, 1, 2), na.rm = TRUE)) #Правильно
lapply(c(1, 2, 4, 1, 2), sum) #Неправильно
##Структура операций
L <- list(c(1,2,3), c(4,5,6))
L
[[1]]
[1] 1 2 3
[[2]]
[1] 4 5 6
lapply(L, sum)
[[1]]
[1] 6
[[2]]
[1] 15
list( sum(L[[1]]) , sum(L[[2]]))
[[1]]
[1] 6
[[2]]
[1] 15
do.call(sum, L)
[1] 21
sum(L[[1]], L[[2]])
[1] 21
##Передача аргументов в качестве листа
args <- list(n = 10, mean = 50, sd = 10) #Т-баллы
do.call(rnorm, args) #эквивалентно rnorm(args$n, args$mean, args$sd)
replicate(10, rnorm(10)) #В каждом столбце числа разные
do.call(replicate, list(10, rnorm(10))) #В каждом столбце числа одинаковые
##Вызов функции по её названию
do.call('colnames', list(iris))
##Комбинация списков
rbind(L) #do.call(rbind, list(L))
Reduce('rbind',x = L) #do.call(rbind, L)
Работа функции не самая очевидная, но в некоторых случаях её использование было очень кстати.
Автор: 100$ 19.06.2022 - 00:16
Конечно.
Благодарю. Буду осваивать.
А вот lapply(list(c(1,2,4,1,2)),sum) выдает 10-ку на ура.
Автор: 100$ 19.06.2022 - 22:20
Подведем некоторые промежуточные итоги.
В соответствии с рекомендациями старших товарищей (А.И.Орлов Эконометрика: учебник для вузов- Ростов н/Д:Феникс, 2009.-572 с.) вместо опостылевшего Стьюдента быстренько состряпаем на R критерий Крамера - Уэлча (с. 67-69).
{
m<-length(x)
n<-length(y)
mean_X<-mean(x)
mean_Y<-mean(y)
Var_X<-var(x)
Var_Y<-var(y)
Cmn<-sqrt(m*n)*(mean_X-mean_Y)/sqrt(n*Var_X+m*Var_Y)
return(c(TEST=Cmn,p_value=2*pnorm(-abs(Cmn))))
}
> CWTest(x,y)
TEST p_value
-3.9267209282 0.0000861118
Нулевая гипотеза радостно отвергается на любом разумном уровне значимости.
В этой связи у меня вопрос-просьба к гуру прграммирования на R: а может ли кто-нибудь оформить это в виде пакета {CW} местного значения, так, чтобы его при случае можно было качнуть с этого форума?
Автор: comisora 20.06.2022 - 00:42
2 100$
У меня опыта создания пакетов нет (да и не гуру я), хотя наслышан про функцию package.skeleton(). В моей области я редко видел, чтобы делали пакеты к выполненной задаче. Обычно народ колхозит и выкладывает творения в https://www.frontiersin.org/articles/10.3389/fpsyg.2015.01171/full файлах. Более продвинутые пользуются ресурсами вроде https://osf.io/. Обученные компьютерной грамоте (т.е. не из моей области) ваяют пакеты http://keii.ue.wroc.pl/clusterSim/.
На текущем этапе развития форума я вижу возможность создания файлов *.R или постов с кодом, которые бы содержали конкретные функции с источниками, пояснением их работы и т.п. Тот же AtteStat достоин того, чтобы для него была сделана обёртка из R/Python (я размышлял, как его подключить, но квалификации не хватило). Учитывая, что не всё можно найти на CRAN/Github/MATLAB/Python, а на форуме хорошая работа с источниками по различным критериям - есть шанс, что какой-нибудь справочник по статистике будет "оцифрован" и появится пакет forum.disser.ru.misc. Правда тогда придётся писать проверки на тип переменных, на минимальную длину и прочие вещи. И, разумеется, источники. Как пример, было обсуждение на форуме, что критерия история с критерием Крамера-Уэлча http://forum.disser.ru/index.php?showtopic=2550&st=0&p=10209&#entry10209.
Автор: ИНО 20.06.2022 - 04:56
В соответствии с рекомендациями старших товарищей (А.И.Орлов Эконометрика: учебник для вузов- Ростов н/Д:Феникс, 2009.-572 с.) вместо опостылевшего Стьюдента быстренько состряпаем на R критерий Крамера - Уэлча (с. 67-69).
Не знаю, что там насчет Крамера, но Ваш код выдает обычную статистику Уэлча (см. t.test()). А вот p проф. Орлов перелагает находить не самым обычным способом - через нормальное распределение, а не через распределение Стьюдента, утверждая: "Естественность указанной оценки состоит в том, что неизвестные статистику дисперсии заменены их выборочными оценками. Из многомерной центральной предельной теоремы и из теорем о наследовании сходимости [11] вытекает, что при росте объемов выборок распределение статистики Т Крамера-Уэлча сходится к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1. Итак, при справедливости H'0 и больших объемах выборок распределение статистики Т приближается с помощью стандартного нормального распределения Ф(х), из таблиц которого следует брать критические значения".
Так, может, в нашем случае предположение положение о больших объемах выборки неприменимо? Ибо ну очень уж неправдоподобно космическое p этот ваш CWTes(). Вот-эта гистрограмма тоже стремная какая-то:
for(i in 1:10000)
{x_sim<-rnorm(3, mean(x), sd(x))
y_sim<-rnorm(3, mean(x), sd(y))
res[i]<-CWTest(x_sim, y_sim)[2]
}
hist(res)
Поскольку, как мы уже успели убедиться, рандомизация при столь малых выборках работает плохо, попробуем смоделировать нулевую гипотезу, используя смоделированные выборки из нормальных распределений с одинаковыми средними и разными стандартными отклонениями, оцененными по нашим выборкам:
res<-rep(0, 99999)
for(i in 1:99999)
{x_sim<-rnorm(3, mean(x), sd(x))
y_sim<-rnorm(3, mean(x), sd(y))
Tsim<-CWTest(x_sim, y_sim)[1]
if(abs(Tsim)>=abs(Tobs))res[i]<-1
}
p=(sum(res)+1)/100000
p
Получилось p, среднее между t.test(x, y) и t.test(x, y, var.eq=T). Конечно, юзать такой метод в серьезном исследовании негоже, ибо мы вводим непредсказуемую зависимость от точности выборочных оценок стандартных отклонений, но, по крайней мере, можно сразу заметить, что оригинальный CWTest() нагло врет, рано ему еще в пакет залезать!
Автор: 100$ 20.06.2022 - 13:01
"Я проснулся сегодня рано..." (Исполняется на мотив песни Bella, ciao).
Захожу на форум и удивляюсь: у вас уже все готово. Это очень удобно.
А вы, собственно, чего ожидали? И Welch, и Пагурова, и Крамер-Уэлч здесь будут давать одно и то же.
Однако, Уэлч первым заметил, что критическая область этого критерия устроена очень сложно. Он искал аппроксимацию в виде t-распределения с дробными df, Пагурова возилась с полиномами, Орлов ничтоже сумняшеся предлагает нормальную аппроксимацию. Ну, и что?
А вы уже забыли, с чего началось обсуждение? С моего утверждения, что любая асимптотика здесь нехороша.
for(i in 1:10000)
{x_sim<-rnorm(3, mean(x), sd(x))
y_sim<-rnorm(3, mean(x), sd(y))
res[i]<-CWTest(x_sim, y_sim)[2]
}
hist(res)
А что вы пытаетесь рассмотреть на этой гистограмме - распределение p-value при альтернативе?
По моим представлениям в конструкции
извлекать надо не вторую компоненту функции, а первую [1] (тестовую статистику). Тогда гистограмма сразу становится симметричной около нуля и маленько напоминает стандартное нормальное распределение.
В общем, программирование по ночам вам не показано.
Что это было? Лекцыя на тему "проблема Беренса-Фишера для чайников"?
А что значит "нагло врет"? Вы же только что заметили, что он выдает ровно то же, что и t.test(). Алгоритмических и программистских ошибок в коде нет.
Вы базар-то фильтруйте.
Здесь "нагло врут" очень многие критерии:
- на вкладке PAST "Epps - Singleton test"(p-value ~0);
- еще наглее врет тест Катценбайссера - Хакля (p-value~0)
и, наверное, много чего еще.
Автор: ИНО 20.06.2022 - 17:10
Нет, на той гистограмме - распределение при нулевой гипотезе! И это очень стрёмное рапределение, с подозрительно большим количеством значений, очень близких к нулю. Сравните с аппроксимацией через распределение Стьюдента (с любым методом нахождения степеней свободы), там такого нету. И да, первая компонента тут совершенно не причем, с ней все в порядке и потому извлекать ее смыла нет. Нагло врет именно вторая. Более наглядно демонстрирует ее ущербность второй фрагмент кода - не поленитесь запустить, несмотря на 100000 итераций оно работает шустро (датчик случайных чисел написан явно не на R).
- на вкладке PAST "Epps - Singleton test"(p-value ~0);
- еще наглее врет тест Катценбайссера - Хакля (p-value~0)
Впервые слышу о таких критериях и вполне верю, что они могут нагло врать по причине неприменимости к обсуждаемой задаче.
Не уверен, что это именно та проблема (т. к. бают, будто для равных размеров выборок таковой и нет вовсе), но терминологию мы не будем оспаривать(С). Это было предупреждение, дабы у ТС (если он все еще с нами) или еще у кого кого, читающего данную тему, не возник соблазн применить в своем исследовании "критерий ИНО" и завернуть его в пакет:) Но, как грубая прикидка, демонстрирующая явную несостоятельность "критерия Крамера-Уэлча-Орлова" (который по странному стечению обстоятельств в таком виде более никто не использует
), в отличие от классических критериев в случае с малыми выборками, это сойдет. Что касается последних, то, как показано в статье по ссылке, любезно предоставленной comisora, они, как не странно, работают с малыми выборками не так уж и плохо. По крайней мере, не хуже альтеративных методов, которых негусто.И да, я не рано встал, а поздно лег. Сейчас хрен угадаешь, в какое время суток можно уличить время с не слушком большим количеством украинских артобстрелов для более или менее спокойного сна. В этот раз не угадал - днем стреляли больше, чем ночью.
Автор: 100$ 20.06.2022 - 23:24
Да, прошу пардону, только сейчас заметил, что mean(x) и там, и там.
Я тут помонтекарлил нулевую гипотезу для объемов 4, 5,6,8,10
и каждый раз гистограмма значений статистики становилась все более симметричной и похожей на стандартное нормальное. Считаю, что для выборок объемом 3 возможна любая "кривизна", обсуждать которую мне недосуг.
Разумеется, так и должно быть: на столь малых объемах выборок редко какой критерий строго выдерживает заявленный уровень значимости.
А что касается "нестрёмнаго распределения p-значения", то, например, для стерильного случая
гистограмма вам понравится: она практически равномерная, и число отвержений нулевой гипотезы (р=0 - 0,05) составляет примерно 25000, что есть 1/20 от 500 000 или 5%. Словом, с ростом объема выборок и номинальный уровень значимости ведет себя асимптотически корректно.
А вообще, вы можете внятно сказать, обо что вы страдаете? Критерий как критерий. Считаете, что нормальная аппроксимация - это зло? Или что pnorm() вычисляет не то, что нужно?
О какой несостоятельности речь? Что при предельном переходе он этот сдвиг ~128 перестанет замечать?
Скажем, в статье Пагуровой таблицы критических значений составлены для объемов выборок, начиная с 5-ти наблюдений. Критические значения составляют для альфа=,05 порядка 2,776 (но сильно меньше 3). Статистика критерия -3,92 предположительно отвергнет нулевую гипотезу на 5%-ном уровне. Возможно, даже и на 1%-ном.
А "густо" - это сколько? С которого зерна в вашей местности начинается куча?
И да, перечислите их уже, наконец. Оценим степень вашей осведомленности.
Да, да, смелее разите оппонентов этим доводом. Это добавляет комизма.
Я искренне желаю, чтобы все артобстрелы однажды прекратились, и навсегда остались лишь страшным сном.
Автор: ИНО 21.06.2022 - 03:31
Да все в порядке изначально было с гистограммой статистики (проверенной многими десятилетиями), претензии были исключительно к гисторамме p (оригинальный метод Орлова, "не имеющий аналогов в мире"). Несостоятелен критерий в том смысле, что выдаваемое p, по крайней мере, в случае с выборками, похожими на исследуемые в данной теме, имеет большее отношение к севрерному сиянию, чем к реальному достигаемому уровню значимости. Сильный перекос в сторону ошибки первого рода. Вообще, я повидал немало статей, авторы которых, профессиональные статистики с научными степенями красноречиво обосновывали "оптимальность" того или иного предлагаемого ими метода, часто подкрепляя теоретические выкладки результатами некоего сфероконного моделирования, показывающего наглядно преимущество на голову надо всеми предшествующими подходами, при том что последующие попытки приложить эти ноу-хау к реальным данным заканчивались печально. Самый последний пример - моя слепая вера в доверительные интервалы BCa, которые пи перепроверке моделированием оказались гораздо уже номинального уровня. Могу поделиться и другими примерами, где все было гораздо хуже.
С этим не спорю. Заметьте, здесь порядок цифр сильно иной, нежели в CWTest, и близок к Стьюденту. А существует ли реализация критерия Пагуровой в современной программном продукте?
Теперь об альтернативных методах. Все, известные мне, уже перебрали в этой теме:
1. Критерии рандомизации - недостаточно мощности вне зависимости от величины эффекта из-за специфики вычислений. Вы предложили модификацию, использующую перевыборку с заменой, однако не привели никаких ссылок на ее теоретическое обоснование. Этот вопрос действительно меня очень заинтересовал.
2. Критерий Вилкоксона-Манна-Уитни - просто недостаточно мощности. С другими классическими ранговыми предположительно будет еще печальнее. Ну, и гипотезу все они проверяют не совсем ту, но то уже мелочи.
4. Построение ДИ для разности средних бутстрепом - в принципе, работает, но расхождение номинального доверительного уровня с реальным может быть велико (в сторону ошибки первого рода), и, что самое неприятное, сильно различается в зависимости от конкретного метода - не очень понятно, какой следует выбрать. Моя прежняя слепая вера в BCa как самый продвинутый, похоже, себя не оправдала.
Автор: 100$ 21.06.2022 - 12:21
В сообщении #7 Игорь привел свои результаты. Было реализовано в Аттестате, описано в мануале к нему (Аттестату), затем, вероятно, перекочевало в StatAnt.
Вы, разумеется, вольны обложившись статьями Пагуровой, воплотить ее формулы "в железе" самостоятельно.
В принципе, здесь много чего "работает". И как оно "работает" я тоже вижу.
Благоприятные свойства бутстрепа мотивированы теоремой Гливенко-Кантелли. Она также точно "завязана" на предельный переход. На выборках объема 3 весь этот бутстрапеж ничем не лучше всего остального: длина BCa отличается в разы, доверительная вероятность к 95% не приближается, какие-то иные оптимальные свойства метода не просматриваются.
Мы тут в конце 2017 года развлекались двумя выборками по 4 наблюдения в каждой.
http://forum.disser.ru/index.php?showtopic=4170&st=30
Но жизнь не стоит на месте: глядишь, кто-то скоро выборки объемом 2 подтащит...
Автор: ИНО 21.06.2022 - 21:00
Ну, результаты моделирования как бы намекают, что Стьюдент б. м. честно работает (если принять допущение о нормальности). К сожалению, с бутстреповскими ДИ на моем компе особо промоделировать не вышло, так что ориентируюсь на результаты Вашего исследования, согласно которым номинальная ошибка первого рода занижена но не настолько, чтоб уж совсем ни в какие ворота не лезла. А вот что предложенная вначале Вами точная перестановка здесь оказалась абсолютно бессильна - факт неоспоримый. "Критерий Крмера-Уэлча-Орлова", увы, тоже подкачал. В обоих случаях полученное номинальное p чудовищно отклоняется от реального (в первом - завышено, во вором - занижено).
Тема по ссылке явно происходит от банального непонимания ТС задач и методов своего (своего ли?) исследования. Похоже на типичный конфуз, возникающий при попытке научного руководителя "тянуть" слабого студента или аспиранта. Там дизайн эксперимента похерен в зародыше, и обсуждать его практического смысла нет никакого. В этой же теме случай совершенно иной: ТС, похоже, столкнулся с реальной проблемой супер-пупермалых выборок (три и три, и будет дырка а больше взять негде) и пытается понять, можно ли вообще на таких данных сделать статистический вывод. Бог миловал меня в своих исследованиях от столь острого дефицита наблюдений, но вопрос считаю весьма интересным. С каких n начинается статистика? Помню, один физик меня уверял, что если хотя бы тысячи замеров нет, то и статанализу делать нечего:) И в физике это оправдано: все пока еще не открытые эффекты столь малы, что для их выявления требуется огромная мощность. В биологии все несколько иначе: целины полно, и порою на ней попадаются попадаются такие здоровенные эффекты, что прямо-таки в глаза бросаются, а пойди ж докажи формально, что тебе это не померещилось...
Автор: comisora 22.06.2022 - 10:42
http://forum.disser.ru/index.php?showtopic=4170&st=30
Но жизнь не стоит на месте: глядишь, кто-то скоро выборки объемом 2 подтащит...
В приложении книга, в которой обсуждается ситуация n=1.
https://stats.stackexchange.com/questions/429084/small-sample-size-and-not-normally-distributed.

|
Автор: 100$ 23.06.2022 - 00:19
Чистая правда: я в тот момент даже не представлял себе, что choose(6,3)=20.
Впрочем, неудивительно: на таких выборочных объемах тьма критериев будет просто смещенными, т.е. их мощность будет меньше номинального уровня значимости.
Я тут чуток помонтекарлил для равных выборочных объемов (n1=n2) от 3 до 100 способность CWTest() удерживать номинальный уровень значимости (alpha=,05).
Получается, что сколько-нибудь осмысленное его применение возможно только при n1=n2>60, п.ч. сходимость к предельному распределению очень медленная. Ребята, это же ужасно.
Такова плата за отсутствие необходимости беспокоиться о равенстве выборочных дисперсий (в случае нормального распределения), т.е. игнорирование мешающего параметра - истинного соотношения дисперсий.
N<-100000#Количество Монте-Карловых выборок
tab<-rep(0,R-2)
for(i in 3:R)# Для выборочных объемов от 3 до 100 с шагом 1
{
res<-replicate(N,CWTest(rnorm(i), rnorm(i))[1])
tab[i-2]<-length(res[abs(res)>1.96])/N
}
plot(3:R,tab,type="l",main="Ошибка I рода для CWTest()")
abline(h=.05,col='red')
Вы же сами себе уже ответили на этот вопрос с помощью choose(): чтобы отвергнуть Ho на 5%-ном уровне, достаточно n1=n2=4, n1=n2=5 отвергнут Ho на 1%-ном уровне.
Автор: ИНО 23.06.2022 - 04:56
Этот ответ справедлив только для критериев рандомизации. Но ими арсенал прикладной статистики не ограничивается.
n1=1 - вполне себе встречающийся на практике случай, но только если n2>1. Чисто теоретически, в сфероконном случае статистика начинается с n1=1 b n2=2 (что б было, где дисперсию считать). Стало интересно, как в таких условиях себя покажет критерий Стьюдента при выполнении всех допущений (в том числе о равенстве дисперсий, поскольку даже чисто теоретически тут различия в дисперсиях оценить невозможно). К сожалению функция power.t.test() работает только с одинаковыми n. Но можно помоделировать красивее:
p<-replicate(1000, t.test(rnorm(2, 0, 1), rnorm(1, d, 1),var.eq=T)$p.value)
delta<-rep(d, 1000)
res<-data.frame(delta, p)
mean_p1<-mean(p)
mean_p<-rep(NA, 99)
for (i in 1:99)
{
d<-d+1
p<-replicate(1000, t.test(rnorm(2, 0, 1), rnorm(1, d, 1),var.eq=T)$p.value)
mean_p[i]<-mean(p)
delta<-rep(d, 1000)
res_<-data.frame(delta, p)
res<-rbind(res, res_)
}
boxplot(p~delta, data=res, range=0)
abline(0.05,0, lwd=2, col="red")
Вывод: после величины эффекта, равной 12 сигмам, нулевая гипотеза вероятнее будет отклонена на пятипроцентном уровне значимости, чем принята. А после разницы в 18 сигм критерий работает уже достаточно уверенно. Увы с однопроцентным уровнем сильно хуже: можете нарисовать abline(0.01, 0) и поплакать над ней.
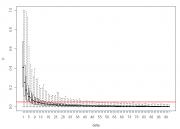
|
Автор: 100$ 23.06.2022 - 11:10
Но, если уж на то пошло, для желаемого соотношения ошибок I и II рода да для заданной величины эффекта, который хочется "уловить", требуемые объемы выборок для t.test() невозбранно определить еще на этапе планирования исследования.
Автор: salm 12.01.2023 - 11:51
Добрый день.  пожалуйста, у меня есть парные измерения показателя, мне нужно найти (или не найти) значимые изменения после воздействия фактора. Поскольку выборка небольшая, всего из 12 наблюдений, мой руководитель просит применить критерий W. Ансари-Бредли или К. Клотца, а в моих стат пакетах их нет. Если вам нетрудно, вы не могли бы обработать..?
пожалуйста, у меня есть парные измерения показателя, мне нужно найти (или не найти) значимые изменения после воздействия фактора. Поскольку выборка небольшая, всего из 12 наблюдений, мой руководитель просит применить критерий W. Ансари-Бредли или К. Клотца, а в моих стат пакетах их нет. Если вам нетрудно, вы не могли бы обработать..?
до. после.
1,96 2,03
2,89 2,60
2,61 2,16
1,83 2,17
1,56 1,65
2,12 2,65
1,44 2,13
2,04 2,16
1,65 2,09
1,12 1,16
1,33 2,16
0,79 1,10
Спасибо.
Автор: 100$ 12.01.2023 - 13:39
пожалуйста, у меня есть парные измерения показателя, мне нужно найти (или не найти) значимые изменения после воздействия фактора. Поскольку выборка небольшая, всего из 12 наблюдений, мой руководитель просит применить критерий W. Ансари-Бредли или К. Клотца, а в моих стат пакетах их нет. Если вам нетрудно, вы не могли бы обработать..?до. после.
1,96 2,03
2,89 2,60
2,61 2,16
1,83 2,17
1,56 1,65
2,12 2,65
1,44 2,13
2,04 2,16
1,65 2,09
1,12 1,16
1,33 2,16
0,79 1,10
Спасибо.
Ваш (уважаемый) руководитель шутит с вами злые шутки: ни Ансари-Брэдли, ни Клотц не работают со связанными выборками.
Кроме того, они тестируют гипотезу об однородности параметров масштаба против альтернативы различий масштабного параметра. Это точно то, что вам нужно?
Адекватными критериями в данном случае являются:
1) парный критерий Стьюдента (реализован везде, где только можно, в т.ч. в Экселе);
2) тест омега-квадрат Орлова;
3) тест знаковых рангов Уилкоксона;
4) тест двумерной симметрии Холлендера;
5) точный перестановочный тест для связанных выборок.
Все вышеперечисленное прикрепил в файле.
Мой вердикт - гипотеза на 5% уровне значимости не отвергается.

Автор: salm 12.01.2023 - 16:09
Кроме того, они тестируют гипотезу об однородности параметров масштаба против альтернативы различий масштабного параметра. Это точно то, что вам нужно?
Адекватными критериями в данном случае являются:
1) парный критерий Стьюдента (реализован везде, где только можно, в т.ч. в Экселе);
2) тест омега-квадрат Орлова;
3) тест знаковых рангов Уилкоксона;
4) тест двумерной симметрии Холлендера;
5) точный перестановочный тест для связанных выборок.
Все вышеперечисленное прикрепил в файле.
Мой вердикт - гипотеза на 5% уровне значимости не отвергается.
Спасибо еще раз огромное!!!
Автор: salm 24.02.2023 - 13:32
Здравствуйте. Скажите, раз непараметрический критерий подходит для малых выборок, зачем тогда расчет их объема для непарметрических критериев?
А еще скажите, как вы относитесь к формулировке: "значимость на уровне тенденции" - когда речь идет о том что бы отвергнуть гипотезу на уровне 5-10%? Когда значимость различий на заявленном уровне в 5% не найдена..?
Спасибо.
Автор: ИНО 24.02.2023 - 14:47
В указанных критериях объемы выборок, учитывается автоматически. Но ежели они очень малые, то достигаемый уровень значимости упирается в, скажем так, техническую границу и может никогда не перевалить за вожделенные 5% вне зависимости от величины различий. См. предыдущие страницы. Это как раз может быть одной из причин упомянутой Вами "значимости на уровне тенденции". Однако в большинстве случаев подобные выражения говорят лишь о том, что автор найти значимых различий не смог, но ему очень хочется.
Автор: Игорь 24.02.2023 - 17:37
Точные критерии, применяемые для малых выборок, при вычислении для больших выборок упираются в сложность расчета (для многих численность не более 12-13 или около того, иначе результатов ждать долго).
Если необходимо непременно найти различия хоть какие-нибудь (как исследователь, чувствуя, что они есть), примените критерии различных типов (положение, масштаб, функция распределения, комплекс параметров).
Автор: salm 24.02.2023 - 20:47
Точные критерии, применяемые для малых выборок, при вычислении для больших выборок упираются в сложность расчета (для многих численность не более 12-13 или около того, иначе результатов ждать долго).
Если необходимо непременно найти различия хоть какие-нибудь (как исследователь, чувствуя, что они есть), примените критерии различных типов (положение, масштаб, функция распределения, комплекс параметров).
Я пока толко поняла что расчетный обьем выборки позволяет мне не найти различия в 20% при заявленной мощности 80%. А могу ли я при недостаточной выборке совершить ошибку первого рода и соврать что различия есть?
Автор: salm 24.02.2023 - 20:55
Спасибо. А в принципе, такое выражение "значимость на уровне тенденции" имеет право на существование? вне конкретной ситуации? Вообще, уместно ли так написать, при понимании того, что выборка мала при таких параметрах признака?
Автор: 100$ 24.02.2023 - 23:32
> Спасибо. А в принципе, такое выражение "значимость на уровне тенденции" имеет право на существование?
Нет.
> ...вне конкретной ситуации?
Тем более, нет.
> Вообще, уместно ли так написать, при понимании того, что выборка мала при таких параметрах признака?
Нет.
Автор: ИНО 25.02.2023 - 05:37
Конечно, можете, особенно, если последуете совету Игоря и начнете проверять все возможные гипотезы всеми существующими критериями на одних и тех же данных.
Игорь, судя по этому Вашему совету, а также по тому что Вы написали недавно написали о развитии интерфейса Вашего ПО в сторону одной волшебной кнопки, считающей вес и сразу, можно ли сделать вывод о том, что на Вами принято волевое решение на проблему множественных сравнений окончательно и бесповоротно забить?
Автор: Игорь 1.03.2023 - 10:25
Автор: ИНО 1.03.2023 - 12:35
Проблема множественных сравнений отнюдь не исчерпывается сравнением одной выборки одним критерием с множеством других выборок. Сравнение двух выборок между собой множеством разных критериев (с последующем выбором того, где получилось p меньше) - это тоже про нее.
Автор: Игорь 1.03.2023 - 20:24
2 пример. Имеем 2 выборки. Сравниваем выборочные средние 4-мя эквивалентными критериями (Стьюдента, Уэлча, Пагуровой, Кокрена-Кокс). Все значимы.
Хотелось бы пошутить, но все так плохо, не до шуток сейчас. Предлагаю, если интересует, множественные сравнения перенести в отдельную тему. А мы ознакомимся и поправим свои знания.
Автор: ИНО 2.03.2023 - 07:16
Пример 1. Почему у Смирнова мощность значительно меньше, чем у предложенного Вами критерия "применить поочередно и Стьюдента и Фишера (и еще десятком других, проверяющих по отдельности разные гипотезы о параметрах распределений) и выбрать наименьшее p"? Зачем в наш век высоких технологий вообще такой маломощный критерий нужен, если запустить дюжину разных и при этом установить не только сам факт различий в распределениях, но заодно и то, в чем конкретно они заключаются, ничего не стоит? Или все же стоит? Вы сервисом Virustotal пользовались? Никаких интересных аналогий с поведением ошибки первого рода не заметили?
Пример 2. Все зависит от того, насколько области ошибки первого рода разных критериев перекрываться. Если они действительно эквивалентны, то перекрытие должно быть практически полным, поэтому корректировка на множественные сравнения не требуется. Шутка в том, что в реальности мы это установить не можем. Даже сам автор критерия обычно не может сказать в какой конкретной ситуации больше соврет его критерий, а в какой - его конкурент. При нынешнем уровне научно-технического прогресса выработка сколь-нибудь эффективной процедуры контроля ошибки первого рода ля такого плана анализа представляется нереализуемой. Поэтому рекомендуется выбирать только один критерий, который исследователь считает наиболее мощным в данном случае, или же, если специфику случая представляет слабо, - равномерно наиболее мощный. Мне не встречалось ни одной публикации со словами типа "гипотезу о равенстве математических ожиданий проверяли критериями Стьюдента, Уэлча, Пагуровой, Кокрена-Кокс с последующим выбором наименьшего достигнутого уровня значимости". А ведь именно такой анализа Вы реализовали (или хотите реализовать) в своем ПО.
Автор: Игорь 2.03.2023 - 07:39
Автор: ИНО 2.03.2023 - 10:06
Так-то оно так, вот только для перестраховки принято встраивать защиту от дурака. Хотя бы в виде предупреждения: "Множественные процедуры не рекомендуются" (С)х/ф "Пассажиры". Вы же озвучили диаметрально противоположный подход.
Автор: Игорь 2.03.2023 - 11:10
Автор: ИНО 2.03.2023 - 11:51
Причем тут смежные области? Вопрос лежит сугубо в плоскости дизайна и звучит так: следует ли автору ПО создавать такой интерфейс, который будет максимально благоприятствовать бездумному использованию? Одна кнопка "посчитать все" (если я правильно понял Ваш тезис о "радикальном упрощении") - это прямо-таки приглашение к дата дреджингу.
Форум Invision Power Board (http://www.invisionboard.com)
© Invision Power Services (http://www.invisionpower.com)