Здравствуйте, гость ( Вход | Регистрация )

  |

 17.06.2015 - 11:30 17.06.2015 - 11:30
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 15.06.2014 Пользователь №: 26464 |
Здравствуйте!
Нужна Ваша помощь. Анализируются данные по оборачиваемости. Для 15 аптек в течение 6 месяцев (с мая по октябрь) были получены данные по оборачиваемости (приведены в прикрепленном файле). В части аптек (аптеки 5,6,9,14) были проведены мероприятия по улучшению показателей оборачиваемости (в июне). Основная задача: анализ эффективности проведенных мероприятий (и интересно (?) вообще так ли нужны они были именно в этих аптеках). Я понимаю, что мне в данном случае может помочь дисперсионный анализ (я его задал через модуль GLM). Возникли вопросы по полученным результатам. 1) Для всей модели дисперсионного анализа получил таблицу (в прикрепленном файле). Можно ли как-нибудь оценить двухфакторное взаимодействие? Как получить значение ошибки (Error)? 2) Можно ли в моем случае вообще применять дисперсионный анализ? В прикрепленном файле находятся гистограммы распределения остатков (нормальность не видна) и результаты проверки однородности дисперсии (получил высоко статистически значимую неоднородность дисперсии в ячейках дисперсионного комплекса). На данном форуме прочитал про робастность дисперсионного анализа. Или все-таки необходимо проводить преобразование данных? Но если их провести, не потеряют ли они свой смысл (как интерпретировать изменение не оборачиваемости, а квадратного корня из значения оборачиваемости)? 3) Можно ли в данном случае и как грамотно провести Post hoc сравнения? В прикрепленном файле находятся данные, полученные при использовании теста Фишера и Тьюки для данных в моем примере ("значимых различий нет"). Может, еще что-нибудь посоветуете по анализу данных в моем примере. Заранее благодарен за ответы и помощь.
Прикрепленные файлы
|
 |
 
|



 |
|
|
17.06.2015 - 15:11
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Вы не закодировали в таблицу описанное на словах воздействие. А сам дисперсионный анализ не является эксплораторным методом, он доказывает статгипотезы о эффектах заложенных в структуру выборочных данных.
 |
|
|
|
|
|
|
17.06.2015 - 16:32
Сообщение
#3
|
||||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Еще и месяц фактически не указан
 Код library(reshape2) library(fda.usc) read.csv2("dannye.csv") аптека месяц оборач 1 1 105 62 2 2 105 37 3 3 105 32 4 4 105 54 5 5 105 86 6 6 105 58 7 7 105 43 8 8 105 32 9 9 105 70 10 10 105 50 11 11 105 47 12 12 105 27 13 13 105 26 14 14 105 68 15 15 105 35 16 1 106 57 17 2 106 36 18 3 106 29 19 4 106 57 20 5 106 87 21 6 106 56 22 7 106 37 23 8 106 30 24 9 106 70 25 10 106 52 26 11 106 43 27 12 106 25 28 13 106 25 29 14 106 61 30 15 106 35 31 1 107 47 32 2 107 37 33 3 107 33 34 4 107 56 35 5 107 79 36 6 107 63 37 7 107 43 38 8 107 30 39 9 107 59 40 10 107 55 41 11 107 46 42 12 107 25 43 13 107 30 44 14 107 59 45 15 107 39 46 1 108 54 47 2 108 39 48 3 108 34 49 4 108 57 50 5 108 78 51 6 108 60 52 7 108 40 53 8 108 30 54 9 108 54 55 10 108 51 56 11 108 44 57 12 108 32 58 13 108 31 59 14 108 55 60 15 108 38 61 1 109 34 62 2 109 31 63 3 109 26 64 4 109 43 65 5 109 60 66 6 109 40 67 7 109 30 68 8 109 26 69 9 109 37 70 10 109 34 71 11 109 32 72 12 109 23 73 13 109 23 74 14 109 39 75 15 109 29 76 1 110 39 77 2 110 31 78 3 110 31 79 4 110 42 80 5 110 65 81 6 110 41 82 7 110 30 83 8 110 26 84 9 110 40 85 10 110 40 86 11 110 45 87 12 110 24 88 13 110 24 89 14 110 41 90 15 110 31 data <- read.csv2("dannye.csv") > dcast(data, аптека~месяц) Using оборач as value column: use value.var to override. аптека 105 106 107 108 109 110 1 1 62 57 47 54 34 39 2 2 37 36 37 39 31 31 3 3 32 29 33 34 26 31 4 4 54 57 56 57 43 42 5 5 86 87 79 78 60 65 6 6 58 56 63 60 40 41 7 7 43 37 43 40 30 30 8 8 32 30 30 30 26 26 9 9 70 70 59 54 37 40 10 10 50 52 55 51 34 40 11 11 47 43 46 44 32 45 12 12 27 25 25 32 23 24 13 13 26 25 30 31 23 24 14 14 68 61 59 55 39 41 15 15 35 35 39 38 29 31 plot.fdata(fdata(data.recast[,-1])) t(scale(t(data.recast[,-1]))) 105 106 107 108 109 110 [1,] 1.2153558 0.75382831 -0.1692268 0.47691179 -1.3691984 -0.90767082 [2,] 0.5437821 0.24717366 0.5437821 1.13699884 -1.2358683 -1.23586831 [3,] 0.3986033 -0.62637656 0.7402632 1.08192316 -1.6513564 0.05694332 [4,] 0.3539075 0.77859645 0.6370335 0.77859645 -1.2032854 -1.34484841 [5,] 0.9198187 1.01029264 0.2865009 0.19602693 -1.4325045 -0.98013465 [6,] 0.5020121 0.30120725 1.0040242 0.70281691 -1.3052314 -1.20482899 [7,] 0.9753883 -0.02786824 0.9753883 0.47376005 -1.1983342 -1.19833425 [8,] 1.2247449 0.40824829 0.4082483 0.40824829 -1.2247449 -1.22474487 [9,] 1.0522754 1.05227537 0.2806068 -0.07015169 -1.2627304 -1.05227537 [10,] 0.3681605 0.61360087 0.9817614 0.49088069 -1.5953623 -0.85904121 [11,] 0.7586214 0.03034486 0.5765523 0.21241400 -1.9724157 0.39448313 [12,] 0.3100868 -0.31008684 -0.3100868 1.86052102 -0.9302605 -0.62017367 [13,] -0.1528545 -0.45856338 1.0699812 1.37569014 -1.0699812 -0.76427230 [14,] 1.2285598 0.62150670 0.4480630 0.10117551 -1.2863743 -1.11293060 [15,] 0.1286713 0.12867125 1.1580413 0.90069877 -1.4153838 -0.90069877 plot.fdata(fdata(t(scale(t(data.recast[,-1]))))) > res.pca <- fdata2pc(fdata( t(scale(t(data.recast[,-1]))) ), ncomp=4, norm=TRUE) > summary(res.pca) - SUMMARY: fdata2pc object - -With 4 components are explained 99.18 % of the variability of explicative variables. -Variability for each component (%): PC1 PC2 PC3 PC4 51.51 23.20 18.20 6.27 Теперь если всё таки появится вектор воздействий можно провести функциональный аналог anova.
Эскизы прикрепленных изображений
|
|||
|
|
|



|
|
|
17.06.2015 - 18:00
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 15.06.2014 Пользователь №: 26464 |
p2004r, спасибо за Ваш ответ и помощь!
Цитата(p2004r @ 17.06.2015 - 15:11)  Вы не закодировали в таблицу описанное на словах воздействие. А сам дисперсионный анализ не является эксплораторным методом, он доказывает статгипотезы о эффектах заложенных в структуру выборочных данных. Точно. Извиняюсь. Не обратил внимание. Уточню (так как анализ не совсем мне нужен). Но по приведенным данным мы ведь имеем право проверить эффекты различий для оборачиваемости на разных сроках и для разных аптек (по приведенному примеру, в предположении, что никаких воздействий не было)? Тогда поставленные вопросы остаются открытыми. Цитата(p2004r @ 17.06.2015 - 16:32) Еще и месяц фактически не указан Что Вы имеете в виду? Мы не имеем права для месяца присвоить значения 1-12 (для мая-5, не совсем ясно почему в прикрепленном файле 105)? Да. И где можно почитать про эксплораторные методы анализа? |
|
|
|
|
|
|
18.06.2015 - 13:22
Сообщение
#5
|
|||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(maxandron @ 17.06.2015 - 18:00) p2004r, спасибо за Ваш ответ и помощь! Точно. Извиняюсь. Не обратил внимание. Уточню (так как анализ не совсем мне нужен). Но по приведенным данным мы ведь имеем право проверить эффекты различий для оборачиваемости на разных сроках и для разных аптек (по приведенному примеру, в предположении, что никаких воздействий не было)? Тогда поставленные вопросы остаются открытыми. Что Вы имеете в виду? Мы не имеем права для месяца присвоить значения 1-12 (для мая-5, не совсем ясно почему в прикрепленном файле 105)? Да. И где можно почитать про эксплораторные методы анализа? 1. "Право" Вы конечно имеете вводить любые названия уровням факторов. Но тогда у Вас ещё появляется "обязанность" использовать эти же названия при описании данных. 2. А так кроме 6й аптеки все выбранные "стагнирующие" (ещё точно такие 1я и 8я) Код > kmeans.fd(fdata( t(scale(t(data.recast[,-1])))), ncl=2) $cluster [1] 1 2 2 1 1 2 2 1 1 1 1 2 2 1 2 $centers $data 105 106 107 108 109 110 center 1 0.9667909 0.6414424 0.4017865 0.2593579 -1.449047 -0.8203306 center 2 0.3865271 -0.1065490 0.7401991 1.0760584 -1.258059 -0.8381761 $argvals [1] 1 2 3 4 5 6 $rangeval [1] 1 6 $names $names$main [1] "fdataobj" $names$xlab [1] "t" $names$ylab [1] "X(t)" attr(,"class") [1] "fdata" > table(c(1, 2, 2, 1, 1, 2, 2, 1, 1, 1, 1, 2, 2, 1, 2), 1:15) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 1 0 0 1 1 0 0 1 1 1 1 0 0 1 0 2 0 1 1 0 0 1 1 0 0 0 0 1 1 0 1 Вот если увеличить число кластеров группа экспериментальных еще больше выделилась ?3 Код > table(c(3, 1, 4, 1, 3, 1, 1, 3, 3, 1, 4, 2, 2, 3, 1), 1:15) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 0 1 0 1 0 1 1 0 0 1 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 3 1 0 0 0 1 0 0 1 1 0 0 0 0 1 0 4 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0
Эскизы прикрепленных изображений
|
||
|
|
|


|
|
|
18.06.2015 - 21:33
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(maxandron @ 17.06.2015 - 13:30) Здравствуйте! Нужна Ваша помощь. Анализируются данные по оборачиваемости. Для 15 аптек в течение 6 месяцев (с мая по октябрь) были получены данные по оборачиваемости (приведены в прикрепленном файле). В части аптек (аптеки 5,6,9,14) были проведены мероприятия по улучшению показателей оборачиваемости (в июне). Основная задача: анализ эффективности проведенных мероприятий (и интересно (?) вообще так ли нужны они были именно в этих аптеках). Я понимаю, что мне в данном случае может помочь дисперсионный анализ (я его задал через модуль GLM). Возникли вопросы по полученным результатам. 1) Для всей модели дисперсионного анализа получил таблицу (в прикрепленном файле). Можно ли как-нибудь оценить двухфакторное взаимодействие? Как получить значение ошибки (Error)? 2) Можно ли в моем случае вообще применять дисперсионный анализ? В прикрепленном файле находятся гистограммы распределения остатков (нормальность не видна) и результаты проверки однородности дисперсии (получил высоко статистически значимую неоднородность дисперсии в ячейках дисперсионного комплекса). На данном форуме прочитал про робастность дисперсионного анализа. Или все-таки необходимо проводить преобразование данных? Но если их провести, не потеряют ли они свой смысл (как интерпретировать изменение не оборачиваемости, а квадратного корня из значения оборачиваемости)? 3) Можно ли в данном случае и как грамотно провести Post hoc сравнения? В прикрепленном файле находятся данные, полученные при использовании теста Фишера и Тьюки для данных в моем примере (?значимых различий нет?). Может, еще что-нибудь посоветуете по анализу данных в моем примере. Заранее благодарен за ответы и помощь. Поясните, пожалуйста, что значит оборачиваемость. Это важно для интерпретации результатов. Чем она выше тем лучше или наборот? |
|
|
|

|
|
|
19.06.2015 - 00:09
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 15.06.2014 Пользователь №: 26464 |
Цитата(nokh @ 18.06.2015 - 21:33) Поясните, пожалуйста, что значит оборачиваемость. Это важно для интерпретации результатов. Чем она выше тем лучше или наборот? Оборачиваемость-это количество дней в течение которых вложенные деньги в товар возвращаются организации. Поэтому, чем она ниже, тем лучше. |
|
|
|
|
|
|
19.06.2015 - 19:56
Сообщение
#8
|
|||
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
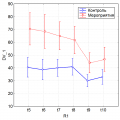
Цитата(maxandron @ 19.06.2015 - 02:09) Оборачиваемость-это количество дней в течение которых вложенные деньги в товар возвращаются организации. Поэтому, чем она ниже, тем лучше. Ну тогда всё логично получается... Под давлением нехватки времени и прочего я близок с тому чтобы поменять своё мнение относительно выбора способа задания дисперсионного комплекса: если можно обойтись более быстрым и простым - его и использовать. Поэтому и ваш случай обсчитал не через модуль общих линейных моделей, а через модуль повторных измерений в ANOVA (хотя по объёму информации он и уступает). Для этого нужна другая организация данных: рис. прикрепил ниже. Если работать в Statistica, то в Within effects нужно проставить 6 уровней: пакет автоматически сформирует фактор повторных измерений R1, который в нашем случае означает временной фактор с 6 градациями (месяцами). По результатам этого анализа высоко статистически значимо взаимодействие "Мероприятия х R1", что означает различие временных динамик для аптек с мероприятиями и без (контроль), т.е. различие профилей на графике. График прикрепил. Всё красиво. Видно, что это за различия в профиле: когда в контроле в период какой-то летней стагнации в контрольных аптеках всё держится на одном уровне, в аптеках с мероприятиями идёт снижение сроков оборачиваемости. В результате если до мероприятий аптеки-аутсайдеры отставали примерно (визуально) на 71-41=30, т.е. на месяц, то в октябре - уже где-то на 47-33=14 дней, т.е. на 2 недели. Я считаю, что сокращение времени оборота в 2 раза это очень хороший результат. Если нужны апостериорные сравнения - можно всё найти. В принципе, дисперсионный анализ можно было задать и как-то иначе, скажем ввести фактор "Срок" с 2 градациями: до и после мероприятий, но полагаю это только несколько усложнит анализ, а наглядности убавит. Сообщение отредактировал nokh - 20.06.2015 - 05:46
Эскизы прикрепленных изображений
|
||
|
|
|

|
|
|
20.06.2015 - 11:29
Сообщение
#9
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Если чисто по сырым данным функциональным данным, то вот так anova выглядит
Код > data.recast<- data.frame(v= c(1,1,1,1,2,2,1,1,2,1,1,1,1,2,1), data.recast)
> data.recast v аптека X105 X106 X107 X108 X109 X110 1 1 1 62 57 47 54 34 39 2 1 2 37 36 37 39 31 31 3 1 3 32 29 33 34 26 31 4 1 4 54 57 56 57 43 42 5 2 5 86 87 79 78 60 65 6 2 6 58 56 63 60 40 41 7 1 7 43 37 43 40 30 30 8 1 8 32 30 30 30 26 26 9 2 9 70 70 59 54 37 40 10 1 10 50 52 55 51 34 40 11 1 11 47 43 46 44 32 45 12 1 12 27 25 25 32 23 24 13 1 13 26 25 30 31 23 24 14 2 14 68 61 59 55 39 41 15 1 15 35 35 39 38 29 31 > anova.onefactor(fdata(data.recast[,-c(1:2)]), data.recast[,1], plot=TRUE) ### что бы оценить pvalue понадобиться увеличить число перевыборок > anova.onefactor(fdata(data.recast[,-c(1:2)]), data.recast[,1], nboot=10000)$pvalue [1] 1e-04
Эскизы прикрепленных изображений
|
|
|
|
|

|
|
|
20.06.2015 - 15:10
Сообщение
#10
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Но почему то мне представляется более правильно считать по "нормализованному поведению", когда и матожидание и дисперсия нормированы и отличается только "форма кривой".
А что в месяце "109" случилось? Код > anova.onefactor(fdata(t(scale(t(data.recast[,-c(1:2)])))), data.recast[,1], plot=TRUE) > anova.onefactor(fdata(t(scale(t(data.recast[,-c(1:2)])))), data.recast[,1], nboot=10000)$pvalue [1] 0.0115 > anova.onefactor(fdata(t(scale(t(data.recast[,-c(1:2)])))), data.recast[,1], nboot=10000)$pvalue [1] 0.0121 > anova.onefactor(fdata(t(scale(t(data.recast[,-c(1:2)])))), data.recast[,1], nboot=10000)$pvalue [1] 0.0103 > anova.onefactor(fdata(t(scale(t(data.recast[,-c(1:2)])))), data.recast[,1], nboot=100000)$pvalue [1] 0.01224
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
20.06.2015 - 16:50
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 15.06.2014 Пользователь №: 26464 |
p2004r, nokh большое спасибо за Вашу помощь! Будем разбираться и если что, задавать вопросы.
|
|
|
|
|
|
|