Здравствуйте, гость ( Вход | Регистрация )
 Форум врачей-аспирантов » Все сообщения пользователя
Форум врачей-аспирантов » Все сообщения пользователя
| Отправлено: 31.03.2019 - 12:39 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Да, я хелп читала, но там просто описание метода, а не принцип работы |
| Форум: Медицинская статистика · Просмотр сообщения: #23867 · Ответов: 3 · Просмотров: 4550 |



| Отправлено: 30.03.2019 - 19:58 | ||
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
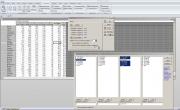
Подскажите в Statistica 10 реализован метод feature Selection. Я прикрепила скрин. в R есть библиотека Boruta Я хочу понять по какому принципу работает этот метод. Как он выявляет какие из независимых переменных влияют на зависимую? И почему бывают такие ситуации, когда 1. он считает что все переменные сильно связаны с зависимой 2. А также если взять в модель те переменные, которые метод выбрал, модель(не важно, нейронные сети, логистическая....................) может быть низкого качества в плане классификации. Ведь FS же показал переменные, что влияют.
Эскизы прикрепленных изображений
|
|
| Форум: Медицинская статистика · Просмотр сообщения: #23864 · Ответов: 3 · Просмотров: 4550 |
| Отправлено: 9.03.2018 - 15:08 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Я вроде нашла это sparse matrix, я это имела ввиду https://stackoverflow.com/questions/1200907...e-sparse-matrix |
| Форум: Медицинская статистика · Просмотр сообщения: #22749 · Ответов: 3 · Просмотров: 4761 |
| Отправлено: 8.03.2018 - 15:38 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Подскажите, есть ли статистический тест, который поможет проверить, что матрица данных данных действительно разряжена? |
| Форум: Медицинская статистика · Просмотр сообщения: #22743 · Ответов: 3 · Просмотров: 4761 |
| Отправлено: 23.02.2018 - 14:27 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Добрый день. Есть 20 переменных(прислала датасет с фиктивными, а то настоящие данные нельзя давать) группировать переменные можно или кластерным анализом или факторным допустим , если мы стали использовать факторный анализ, мы выделил 4 фактора, каждый нагружен тремя переменными. Вопрос то был понять, как наблюдения кучкуются у каждого фактора Я думала выделит факторы, превратить их в регрессионные переменные и по ним сделать кластерный анализ. Я так полагаю nokh это имели ввиду?
Прикрепленные файлы
|
| Форум: Медицинская статистика · Просмотр сообщения: #22666 · Ответов: 9 · Просмотров: 10170 |

| Отправлено: 22.02.2018 - 15:04 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Подскажите, как можно решить такую задачу 1. есть данные, в них 20 переменных 2. нужно кластеризовать эти 20 переменных, т.е. выделить классы схожим переменных 3.затем найти людей, которые "кучкуются" у каждого класса переменных. Например мы нашли 4 класса переменных абв, где, ежз, икл. наблюдения 1-30 кучкуются у класса к примеру ежз. |
| Форум: Медицинская статистика · Просмотр сообщения: #22661 · Ответов: 9 · Просмотров: 10170 |
| Отправлено: 23.01.2018 - 14:19 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Искажать нужно не только фио, а другие персональные данные. Фио я привела как пример Я не имею права передавать персональные данные, такие как ФИО, паспорт, и так далее, но если исказить информацию, так. чтобы потом смочь её прочесть, не нарушая закон можно. |
| Форум: Медицинская статистика · Просмотр сообщения: #22471 · Ответов: 5 · Просмотров: 6874 |
| Отправлено: 23.01.2018 - 11:20 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Согласно закону о персональных данных, напрямую нельзя передовать сторонним лицам такие данные, как ФИО. Однако из ФИО можно тоже получать такую информацию, как национальность, пол. Есть ли способы закодировать, а лучше сказать исказить персональные данные, так что с одной стороны они содержат начальную информацию, а с другой стороны мы не нарушаем закона, т.к. там не реальное ФИО, а кодировка. Можно ли составить какой-либо семантический словарь , а потом по нему расшифровывать? Подскажите, пожалуйста. |
| Форум: Медицинская статистика · Просмотр сообщения: #22467 · Ответов: 5 · Просмотров: 6874 |
| Отправлено: 20.11.2017 - 15:31 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Подскажите, пожалуйста, как мне в моем наборе данных изменить формат дат т.е. research$date 06.03.2017 перевести в формат 20170603 (yyyymmdd) далее формат данных часов research$h research$ m 16:29:58 16:30:23 ч:мин:сек мне нужно , чтобы поля были заполнены так research$h research$m 16 30 т.е. 16 часов, а в другом поле 30 минут |
| Форум: Медицинская статистика · Просмотр сообщения: #22212 · Ответов: 1 · Просмотров: 2943 |
| Отправлено: 20.11.2017 - 15:18 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
nokh, все в порядке. Тут правда остатки распределены не нормально, а значит и не надо парится с анализом мощности, под эти данные, он не подходит. |
| Форум: Медицинская статистика · Просмотр сообщения: #22211 · Ответов: 8 · Просмотров: 8442 |
| Отправлено: 18.11.2017 - 12:42 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
nokh, спасибо Вам, в каждой группе 25 чел. А как усреднить стандартные отклонения? |
| Форум: Медицинская статистика · Просмотр сообщения: #22203 · Ответов: 8 · Просмотров: 8442 |
| Отправлено: 17.11.2017 - 15:33 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, там в любом случае надо вводить сигму, но только одну,а у меня их три) Прям как в том анекдоте про блондинке в машине, ножек 2, а педалек 3)) |
| Форум: Медицинская статистика · Просмотр сообщения: #22199 · Ответов: 8 · Просмотров: 8442 |
| Отправлено: 16.11.2017 - 17:02 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Код Description Calculate power for one-way ANOVA models. Usage pwr.1way(k=k, n=n, alpha=alpha, f=NULL, delta=delta, sigma=sigma) Arguments k Number of groups n Sample size per group f Effect size alpha Significant level (Type I error probability) delta The smallest difference among k groups sigma Standard deviation, i.e. square root of variance И где в этих аргументах вводить среднее и сигмы, у меня три группы и все имеют разные средние и сигмы)) а тут дана только одна сигма |
| Форум: Медицинская статистика · Просмотр сообщения: #22196 · Ответов: 8 · Просмотров: 8442 |
| Отправлено: 16.11.2017 - 16:49 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Подскажите, пожалуйста, как мне рассчитать мощность для ановы с тремя группами, имея только средние и стандартные отклонения? пример М=40, S=4 M2=35 S=10 M3=45 S=8 Как мне мощность рассчитать в R |
| Форум: Медицинская статистика · Просмотр сообщения: #22194 · Ответов: 8 · Просмотров: 8442 |
| Отправлено: 21.10.2017 - 14:00 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
коллеги, то о чем вы говорите в R можно сделать? |
| Форум: Медицинская статистика · Просмотр сообщения: #22043 · Ответов: 7 · Просмотров: 7855 |
| Отправлено: 20.10.2017 - 15:04 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
С расчетом выборки немного знакома power analysis. Но в контексте моей задачи, что мне брать за эталон я не поняла. Дело в том, что sample size calculation требует подоплёку, в частности нужны данные из вне источников по схожим исследованиям, чтобы что-то сделать. |
| Форум: Медицинская статистика · Просмотр сообщения: #22031 · Ответов: 7 · Просмотров: 7855 |
| Отправлено: 19.10.2017 - 17:40 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
У меня есть идея, но лучше посоветуюсь с более умными. можно ли взять случайную выборку всех тех у кого есть значки в городе N пусть 1000 человек предложить им поучаствовать в онлайн опросе, где один из вопросов будет: есть ли у вас значки с гербом рсфрс? так можно получить доли например 150 человек сказали , да есть значки с герборм рсфср, т.е. 15% эту долю репрезентируем на генеральную совокупность. Так корректно делать? |
| Форум: Медицинская статистика · Просмотр сообщения: #22027 · Ответов: 7 · Просмотров: 7855 |
| Отправлено: 18.10.2017 - 16:09 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Уважаемые форумчане,  , пожалуйста, мне в этой задаче, я не знаю как её решить. , пожалуйста, мне в этой задаче, я не знаю как её решить. В городе N есть коллекционеры значков У коренных жителей города N значки бывают двух типов с изображением герба РСФСР и другие какой должен быть дизаин исследования, чтобы оценить долю значков с гербом рсфср, принадлежащих коренным жителям города N |
| Форум: Медицинская статистика · Просмотр сообщения: #22010 · Ответов: 7 · Просмотров: 7855 |
| Отправлено: 12.08.2017 - 13:35 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, я пробовала работать с тремя этими пакетами, но или у меня руки кривые безнадежно  , или ансамбливое обучение тут не помощник. , или ансамбливое обучение тут не помощник.library("ensembleR") acc1=read.xlsx("C:/Users/Admin/Desktop/buyning.xlsx") index <- sample(1:nrow(acc1),round(0.75*nrow(acc1))) train <- acc1[index,] test <- acc1[-index,] preds <- ensemble(train,test,'id',c('treebag','rpart'),'rpart') Error in train.default(training[, predictors], training[, outcomeName], : Stopping Something is wrong; all the RMSE metric values are missing: RMSE Rsquared Min. : NA Min. : NA 1st Qu.: NA 1st Qu.: NA Median : NA Median : NA Mean :NaN Mean :NaN 3rd Qu.: NA 3rd Qu.: NA Max. : NA Max. : NA NA's :1 NA's :1 ====== library("caretEnsemble") models <- caretList(train,test, methodList=c("glm", "lm")) Error: nrow(x) == n is not TRUE In addition: Warning messages: 1: In trControlCheck(x = trControl, y = target) : trControl$savePredictions not 'all' or 'final'. Setting to 'final' so we can ensemble the models ============== library("classyfire") acco=read.xlsx("C:/Users/admin/Desktop/buyning.xlsx") iClass <- acco[,1] idata <- acco[,-1] ens <- cfBuild(inputData = idata, inputClass = iClass, bootNum = 100, ensNum = 100, parallel = TRUE, cpus = 4, type = "SOCK") а тут такая ошибка Error in .initCheck(inputData, inputClass, bootNum, ensNum, parallel, : Argument "inputData" must contain numeric values. Шах и мат. На что он жалуется то? |
| Форум: Медицинская статистика · Просмотр сообщения: #21809 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 10.08.2017 - 11:16 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Т.е. вы считаете, что такую верификацию из двух методов лучше не делать? |
| Форум: Медицинская статистика · Просмотр сообщения: #21800 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 9.08.2017 - 15:43 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, Ваше мнение, как Вы считаете имеет ли место комбинирование моделей? Т.е.! КNN-очень хорошо отделяет нули от единиц, а вот дискриминантный анализ, после того,как я его дожала, стал отделять единицы от нулей. Есть ли смысл, сначала использовать КNN, а затем дискриминантный анализ? Т.е. на вход предикторы, на выходе КНН получаем 1, если при этом ДА=1, то итог 1, если ДА =0, то итог=0 Когда на вход предикторы, на выходе КНН получаем 0, если ДА=1, то итог 1, если ДА =0, то итог=0 Корректно ли так будет делать? |
| Форум: Медицинская статистика · Просмотр сообщения: #21797 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 8.08.2017 - 11:45 | ||
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
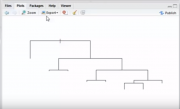
p2004r, подскажите, пожалуйста, а как мне нарисовать графически красиво для программиста, чтобы он уже на базе данных программировал решение. Я проявила сама инициативу хотела через дерево решений нарисовать, но пока не очень хорошо получается. И вопрос для моего повышения знаний. Если accuracy 90% значит ли это что на других выборках точность правильности определения будет не менее 90% т.е. из 100 наблюдений 90 будут правильно отнесены к своим классам. Или как понять эту цифру.
Эскизы прикрепленных изображений
|
|
| Форум: Медицинская статистика · Просмотр сообщения: #21788 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 6.08.2017 - 17:53 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Кстати точно, попробую, прологарифмировать. Подскажите, p2004r, как мне составить уравнение потом. Мне ведь надо не просто принести модель и сказать вот в R есть функция predict, так и предсказывайте программисту нужно сообщить уравнение, чтобы он в CRM для автоматизации запрограммировал. что-то ("mxnet") нет в репозитории. Видимо уже убрали > install.packages("mxnet") Installing package into ?C:/Users/Admin/Documents/R/win-library/3.3? (as ?lib? is unspecified) Warning in install.packages : package ?mxnet? is not available (for R version 3.3.2) |
| Форум: Медицинская статистика · Просмотр сообщения: #21784 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 6.08.2017 - 14:57 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
у меня AUc=0.55, в R считала, неужели мне никак модель не улучшить? |
| Форум: Медицинская статистика · Просмотр сообщения: #21782 · Ответов: 57 · Просмотров: 57528 |
| Отправлено: 5.08.2017 - 17:10 | |
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, здравствуйте, решила написать в своем же топике, но теперь тут другой скоринг (Раньше плохой, хороший), а сейчас купит-не купит услугу(id is dep var)  Логистическая регрессия здесь, показала ужасные результаты, почти все нули(те, кто не купили) были правильно к своему классу отнесены, а единицы(те кто купили) также к нулям. Все что смогла сама сделать, это Дискриминантный анализ в SPSS, вроде показал точность 60%, но это ни о чем. Сильная перемешка кейсов. Можете подсказать, как мне модель выровнять? С регрессией что спсс, что статистика также ,как и R показывали такой результат. Тут нужно только через ДА. acc=read.csv("C:/Users/Admin/Desktop/buyning.csv", sep=";",dec=",") getwd() > acc$profitValueList=as.numeric(acc$profitValueList) > acc$revenueValueList=as.numeric(acc$revenueValueList) > acc$courtPracticeList=as.numeric(acc$courtPracticeList) > acc$digestRedList=as.numeric(acc$digestRedList) > acc$digestGreyList=as.numeric(acc$digestGreyList) > acc$digestGreenList=as.numeric(acc$digestGreenList) > acc$linkedEntitiesByCeoNumList=as.numeric(acc$linkedEntitiesByCeoNumList) > acc$linkedEntitiesByFounderNumList=as.numeric(acc$linkedEntitiesByFounderNumList) > acc$linkedEntitiesChildrenNumList=as.numeric(acc$linkedEntitiesChildrenNumList) > acc$capitalList=as.numeric(acc$capitalList) > acc$gosWinnerNumList=as.numeric(acc$gosWinnerNumList) > acc$gosWinnerSumList=as.numeric(acc$gosWinnerSumList) > acc$gosPlacerNumList=as.numeric(acc$gosPlacerNumList) > acc$gosPlacerSumList=as.numeric(acc$gosPlacerSumList) > acc$inspectionsInFutureNumList=as.numeric(acc$inspectionsInFutureNumList) > acc$inspectionsHasViolationsNumList=as.numeric(acc$inspectionsHasViolationsNumList) > acc$inspectionsNoViolationsNumList=as.numeric(acc$inspectionsNoViolationsNumList) > acc$inspectionsHasViolationsFailsList=as.numeric(acc$inspectionsHasViolationsFailsList) > acc$Выручка=as.numeric(acc$Выручка) > acc$Прибыль=as.numeric(acc$Прибыль) > acc$Убыток=as.numeric(acc$Убыток) > acc$Баланс=as.numeric(acc$Баланс) > acc$Директор.Учредитель=as.numeric(acc$Директор.Учредитель) > acc$Директор.отдельно=as.numeric(acc$Директор.отдельно) > acc$Учредитель.отдельно=as.numeric(acc$Учредитель.отдельно) > index <- sample(1:nrow(acc),round(0.75*nrow(acc))) > train <- acc[index,] > test <- acc[-index,] > library("MASS") > fitTrn =lda(id~.,data=train) Error in lda.default(x, grouping, ...) : ошибка была variables 15 16 appear to be constant within groups Как мне хотя бы маломальски точную классификацию получить?
Прикрепленные файлы
|
| Форум: Медицинская статистика · Просмотр сообщения: #21779 · Ответов: 57 · Просмотров: 57528 |

 Открытая тема (есть новые ответы) Открытая тема (есть новые ответы) Открытая тема (нет новых ответов) Открытая тема (нет новых ответов) Горячая тема (есть новые ответы) Горячая тема (есть новые ответы) Горячая тема (нет новых ответов) Горячая тема (нет новых ответов) |
 Опрос (есть новые голоса) Опрос (есть новые голоса) Опрос (нет новых голосов) Опрос (нет новых голосов) Закрытая тема Закрытая тема Тема перемещена Тема перемещена |