Здравствуйте, гость ( Вход | Регистрация )

  |

 16.05.2017 - 22:50 16.05.2017 - 22:50
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 9 Регистрация: 20.09.2016 Пользователь №: 28664 |
Здравствуйте, уважаемые форумчане!
Прошу прощения за беспокойство. Как бы это странно не звучало, но голову сломал из-за того, что не смог определить, какими являются признаки: качественными или количественными? Исходные данные такие: Целью всей работы является получение возможности при анализе случая определить к какому из двух событий он относится, т.е. дифференциальная диагностика между двумя альтернативными событиями. Для этого исследуются две группы, включающие в себя наблюдения, где доказано, что было событие 1 (первая группа) и событие 2 (2 группа). И вот, в качестве примера: Я построил два ряда, состоящих из целых 12 чисел, характеризующих распределение наблюдений в обеих группах в зависимости от месяца года:
В итоге у меня имеется два ряда из 12 чисел, каждый из которых характеризует первую и вторую группы. У меня стоит цель проверить, имеется ли статистически значимая разница между этими показателями. Так вот, эти два ряда цифр я могу оценивать, как количественные и, соответственно, применять для их сравнения статистические критерии для количественных признаков (Стьюдент, Манн-Уитни и т.п.) или же воспринимать их как качественные и применять иные критерии (Хи-квадрат, точный тест Фишера и т.п.). Заранее благодарю за ответы. P.S.: я понимаю, что вопрос глупый, но таким вот уродился я не шибко грамотным( |
 |
 
|


 |
|
|
17.05.2017 - 00:36
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Robotnik @ 17.05.2017 - 00:50)  ... В итоге у меня имеется два ряда из 12 чисел, каждый из которых характеризует первую и вторую группы. У меня стоит цель проверить, имеется ли статистически значимая разница между этими показателями. Так вот, эти два ряда цифр я могу оценивать, как количественные и, соответственно, применять для их сравнения статистические критерии для количественных признаков (Стьюдент, Манн-Уитни и т.п.) или же воспринимать их как качественные и применять иные критерии (Хи-квадрат, точный тест Фишера и т.п.) По поводу диагностики пока непонятно..., а с данными - полный порядок. У вас таблица из 2х строк и 12 колонок (ну или 2х колонок и 12 строк:) , в ячейках находятся частоты. Типичная таблица сопряжённости, которую можно обсчитать хи-квадратом и подобными критериями. Если различия будут значимыми - далее нужно разбираться за счёт каких ячеек она преимущественно проявилась. Это делается с помощью расчёта скорректированных стандартизованных остатков (остатков Хабермана). Всё это легко посчитать в PAST. |
|
|
|

|
|
|
17.05.2017 - 01:52
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 9 Регистрация: 20.09.2016 Пользователь №: 28664 |
Цитата(nokh @ 17.05.2017 - 00:36) По поводу диагностики пока непонятно..., а с данными - полный порядок. У вас таблица из 2х строк и 12 колонок (ну или 2х колонок и 12 строк:) , в ячейках находятся частоты. Типичная таблица сопряжённости, которую можно обсчитать хи-квадратом и подобными критериями. Если различия будут значимыми - далее нужно разбираться за счёт каких ячеек она преимущественно проявилась. Это делается с помощью расчёта скорректированных стандартизованных остатков (остатков Хабермана). Всё это легко посчитать в PAST. Насчёт самой диагностики - можно не заморачиваться. Это я просто написал, как введение)) Спасибо большое за оперативный ответ. Если Вы не против, то ещё один вопрос. Как обстоят дела, если имеется сразу несколько выборок? В указанном мною выше примере выборки две, а если их шесть? Приведу опять пример: Есть у меня таблица (прикрепил её к этому посту), в которую я вложил данные о количественной неоднородности телесных повреждений, обнаруженных у жертв сексуального насилия, с учётом их локализации, то есть, имеется 40 наблюдений, где было всего одно повреждение на голове, 23 наблюдения, где 2 повреждения на голове, 27 наблюдений, где одно повреждение на туловище и т.д. Подскажите мне, как мне проверить наличие/отсутствие статистической значимости между, скажем, первым столбцом и вторым, т.е. между наблюдениями, где повреждения обнаруживались в количестве "1" и в количестве "2"? Дело в том, что я сначала применил критерий Краскела-Уоллиса, а затем попарно сравнил все выборки с помощью критерия Манна-Уитни (с учётом нового уровня статистической значимости, естественно), но теперь что-то не очень уверен в правильности выбранных мной критериев. Ещё раз прошу прощения за назойливые вопросы - просто работы было сделано много, но вероятность того, что она выполнена неверно расстраивает(  Таблица.xlsx ( 8,78 килобайт )
Кол-во скачиваний: 245
Таблица.xlsx ( 8,78 килобайт )
Кол-во скачиваний: 245 |
|
|
|
|
|
|
17.05.2017 - 10:50
Сообщение
#4
|
||
 Группа: Пользователи Сообщений: 105 Регистрация: 23.11.2016 Пользователь №: 28953 |
Цитата(Robotnik @ 17.05.2017 - 01:52) Насчёт самой диагностики - можно не заморачиваться. Это я просто написал, как введение)) Спасибо большое за оперативный ответ. Если Вы не против, то ещё один вопрос. Как обстоят дела, если имеется сразу несколько выборок? В указанном мною выше примере выборки две, а если их шесть? Приведу опять пример: Есть у меня таблица (прикрепил её к этому посту), в которую я вложил данные о количественной неоднородности телесных повреждений, обнаруженных у жертв сексуального насилия, с учётом их локализации, то есть, имеется 40 наблюдений, где было всего одно повреждение на голове, 23 наблюдения, где 2 повреждения на голове, 27 наблюдений, где одно повреждение на туловище и т.д. Подскажите мне, как мне проверить наличие/отсутствие статистической значимости между, скажем, первым столбцом и вторым, т.е. между наблюдениями, где повреждения обнаруживались в количестве "1" и в количестве "2"? Дело в том, что я сначала применил критерий Краскела-Уоллиса, а затем попарно сравнил все выборки с помощью критерия Манна-Уитни (с учётом нового уровня статистической значимости, естественно), но теперь что-то не очень уверен в правильности выбранных мной критериев. Ещё раз прошу прощения за назойливые вопросы - просто работы было сделано много, но вероятность того, что она выполнена неверно расстраивает(
Таблица.xlsx ( 8,78 килобайт )
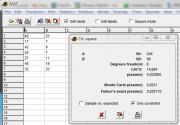
Кол-во скачиваний: 245Robotnik,  ! !Уверен, что обсуждаемые варианты анализа (таблицы сопряжённости и сравнение количественных показателей), это лишь небольшое количество планируемых методов и направлений анализа этого интересного массива данных. Уверен в этом потому, что анализ сложных баз данных простыми методами анализа, не даёт глубокого, полного и очень полезного результата для достижения поставленной цели исследования. Также как практикующий врач, принимая больного пациента, не задаёт ему 1-2 вопроса, и не направляет его на получение 1-2 видов анализа. Поскольку при малом количестве информации маловероятно достаточно точно идентифицировать заболевание или патологию, и, соответственно, назначить продуктивное и полезное лечение. Приведу простой пример. Я скачал Ваш частотный массив, и сделал анализ таблицы сопряжённости в PAST. Результат этого анализа прикреплён (файл PAST_FREQ.jpg ). Все 3 метода анализа дают достигнутый уровень значимости P=0,02, что говорит о наличии взаимосвязи между количествами повреждений. Однако это вовсе не означает, что данная взаимосвязь распространяется на все ВИДЫ ПОВРЕЖДЕНИЙ. При заказах в анализе подобных зависимостей, я и мои коллеги всегда вычисляем и вклады в эту зависимость каждой из отдельных клеток (комбинации градаций двух признаков). Этим самым можно оценить, в каких типах повреждений есть связи интенсивные, а в каких - очень слабые, либо вообще отсутствуют. Фактически это говорит о том, что помимо анализа таблицы сопряжённости размерностью 7*2, следует проводить и анализы таблиц с размерностями 2*2. Естественно, это увеличивает объём проводимых анализов. В исследовании телесных повреждений, обнаруженных у жертв сексуального насилия, наверняка фиксируется более 7 качественных признаков. Скорее всего, есть немало и иных признаков. А в таком случае целесообразно, учитывая весь имеющийся набор признаков, использовать и набор разных многомерных методов анализа. Априори не могу порекомендовать какие конкретно методы следует применить в этом исследовании. Поскольку для этого нужно иметь саму базу данных со всеми фиксируемыми признаками. Уверен, что используемая Вами база данных достаточно большая. А потому и можно применить к ней большое количество продуктивных методов статистического анализа. Набор этих методов, естественно, будет определяться целями исследования. Желаю успешного продолжения этого полезного исследования!
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
17.05.2017 - 12:46
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 9 Регистрация: 20.09.2016 Пользователь №: 28664 |
leo_biostat
Спасибо Вам большое за развёрнутый ответ. Если Вы не против, я уточню для себя - я правильно понимаю, что в моём случае сравнивать выборки нужно именно с помощью Хи-квадрата, а не Манна-Уитни? И как быть с фактом множественного сравнения - нужно ли применять поправку Бонферонни или же везде оставлять критический уровень значимости 0,05? P.S.: и ещё: сравнил сейчас все выборки из моей таблицы с помощью хи-квадрат и получилось, что ни в одной паре сравнений не обнаружена статистическая значимость различий (с учётом поправки Бонферонни, естественно). Такое вполне может быть? Сообщение отредактировал Robotnik - 17.05.2017 - 14:02 |
|
|
|
|
|
|
17.05.2017 - 14:35
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(Robotnik @ 17.05.2017 - 12:46) Бонферонни Пожалуйста, не пишите больше так эту фамилию. Он - Карло-Эмилио Бонферрони. Сообщение отредактировал 100$ - 17.05.2017 - 14:36 |
|
|
|
|
|
|
17.05.2017 - 21:43
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(100$ @ 17.05.2017 - 16:35) Пожалуйста, не пишите больше так эту фамилию. Он - Карло-Эмилио Бонферрони. Пора вводить поправку Карлоса Сесара Сальвадора Араньи Кастанеды: на точку сборки в другой реальности. Говоришь людям что делать, а они - про поправку Бонферрони... Сообщение отредактировал nokh - 17.05.2017 - 21:48 |
|
|
|
|
|
|
17.05.2017 - 23:10
Сообщение
#8
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(nokh @ 17.05.2017 - 21:43) Пора вводить поправку Карлоса Сесара Сальвадора Араньи Кастанеды: на точку сборки в другой реальности. Говоришь людям что делать, а они - про поправку Бонферрони... Неблагодарные... |
|
|
|
|
|
|
21.05.2017 - 09:41
Сообщение
#9
|
|
|
Группа: Пользователи Сообщений: 105 Регистрация: 23.11.2016 Пользователь №: 28953 |
Цитата(Robotnik @ 17.05.2017 - 12:46) leo_biostat Спасибо Вам большое за развёрнутый ответ. Если Вы не против, я уточню для себя - я правильно понимаю, что в моём случае сравнивать выборки нужно именно с помощью Хи-квадрата, а не Манна-Уитни? И как быть с фактом множественного сравнения - нужно ли применять поправку Бонферонни или же везде оставлять критический уровень значимости 0,05? P.S.: и ещё: сравнил сейчас все выборки из моей таблицы с помощью хи-квадрат и получилось, что ни в одной паре сравнений не обнаружена статистическая значимость различий (с учётом поправки Бонферонни, естественно). Такое вполне может быть? Robotnik, !Чтобы получить надёжные ответы на подобные вопросы, высылайте на мой личный мэйл свой массив данных (в формате EXCEL), с его описанием, и описанием цели исследования, и я напишу Вам весь список рекомендуемых методов анализа. А некоторые примеры даже сделаю. Успеха Вам в исследованиях! |
|
|
|
|
|
|
21.05.2017 - 22:16
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(100$ @ 18.05.2017 - 01:10) Неблагодарные... Скорее - невнимательные... Сразу же написал про согласованные стандартизованные остатки Хабермана (Adjusted standardized residuals). Ну это чтобы не делать из одной большой таблицы сопряжённости миллион таблиц 2х2 - как тут рекламирующий свои услуги предприниматель рекомендует. И про отклонения Фримана - Тьюки (Freeman-Tukey deviaties) на форуме писалось неоднократно. |
|
|
|
|
|
|
22.05.2017 - 18:42
Сообщение
#11
|
|
 Группа: Администраторы Сообщений: 301 Регистрация: 6.10.2004 Из: Саратов Пользователь №: 4 |
Цитата(nokh @ 21.05.2017 - 23:16) рекламирующий свои услуги предприниматель Форум врачей-аспирантов создан не для того, чтобы быть рекламной площадкой.Лучше размещать активную рекламу не в темах форума, а рекламных сетях (Яндекс.Директ, Google AdSense). |
|
|
|
|
|
|
23.05.2017 - 15:45
Сообщение
#12
|
|||
|
Группа: Пользователи Сообщений: 105 Регистрация: 23.11.2016 Пользователь №: 28953 |
Цитата(Robotnik @ 17.05.2017 - 12:46) leo_biostat Спасибо Вам большое за развёрнутый ответ. Если Вы не против, я уточню для себя - я правильно понимаю, что в моём случае сравнивать выборки нужно именно с помощью Хи-квадрата, а не Манна-Уитни? И как быть с фактом множественного сравнения - нужно ли применять поправку Бонферонни или же везде оставлять критический уровень значимости 0,05? P.S.: и ещё: сравнил сейчас все выборки из моей таблицы с помощью хи-квадрат и получилось, что ни в одной паре сравнений не обнаружена статистическая значимость различий (с учётом поправки Бонферонни, естественно). Такое вполне может быть? Robotnik, !Неясно, что означает "в моём случае". Относительно критериев Хи-квадрат Манна-Уитни. Точнее, сейчас этот последний критерий чаще называют Манна-Уитни-Вилкоксона. Поясняю, что критерий Хи-квадрат используется не в одном алгоритме, а во многих. А критерий Манна-Уитни-Вилкоксона является ранговым критерием. Поэтому выбор используемого критерия зависит от вида анализируемых признаков. Вернусь к Вашему файлу "Таблица.xlsx". Чтобы продемонстрировать полезность более детального анализа данной таблицы сопряжённости, привожу результат анализа этой таблицы в файле "Image 2.png". Как видим, имеется статистически значимая взаимосвязь между этой парой признаков. Напоминаю, что в интенсивность этой взаимосвязи отдельные клетки этой таблицы вносят разные вклады. В частности, этот вклад конкретной клетки зависит от разности между фактической частотой и ожидаемой (расчётной). Зная детали данного метода, можно установить процент вклада каждой клетки таблицы в установленную взаимосвязь. В файле "Image 4.png" показаны отсортированные по уменьшению вклада все клетки таблицы. Как видим. 16,7% этой связи обуславливает клетка "Туловище"+ ">5". И первые 7 комбинаций этих двух признаков, из 7*6=42 клеток этой таблицы, обеспечивают 54,30% интенсивности взаимосвязи. Исходя из этой информации, можно реконструировать эту таблицу так, чтобы установить более важные комбинации градаций признаков. Желаю успешного продолжения данного исследования!
Эскизы прикрепленных изображений
|
||
|
|
|


|
|
|
23.05.2017 - 16:29
Сообщение
#13
|
|
|
Группа: Пользователи Сообщений: 105 Регистрация: 23.11.2016 Пользователь №: 28953 |
Цитата(logvin @ 22.05.2017 - 18:42) Форум врачей-аспирантов создан не для того, чтобы быть рекламной площадкой. Лучше размещать активную рекламу не в темах форума, а рекламных сетях (Яндекс.Директ, Google AdSense). [ личная переписка удалена модератором] От модератора: дискуссия о понятии рекламы закрыта. Сообщение отредактировал Олег Кравец - 24.05.2017 - 21:18 |
|
|
|
|
|
|