Здравствуйте, гость ( Вход | Регистрация )

  |

 26.09.2011 - 22:12 26.09.2011 - 22:12
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Впервые столкнулся с ситуацией, когда отдельные показатели высоко статистически значимы в отдельных моделях бинарной регрессии. Однако при объединении в множественной регрессии они становятся резко незначимыми (р порядка 0,99), хотя сама модель значима и обладает 100%-ной чувствительностью и специфичностью. Для файла примера выбрал только 2 показателя - систолическое артериальное давление и пульс. Как быть? Как показать такую модель и как ей верить?
Прикрепленные файлы
|
 |
 
|


 |
|
|
27.09.2011 - 09:48
Сообщение
#2
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 26.09.2011 - 21:12)  Впервые столкнулся с ситуацией, когда отдельные показатели высоко статистически значимы в отдельных моделях бинарной регрессии. Однако при объединении в множественной регрессии они становятся резко незначимыми (р порядка 0,99), хотя сама модель значима и обладает 100%-ной чувствительностью и специфичностью. Для файла примера выбрал только 2 показателя - систолическое артериальное давление и пульс. Как быть? Как показать такую модель и как ей верить? из ковариации очевидно что имеет место две группы, и следовательно все зависимости наблюдаемые для смеси ложные Код plot(data$ad,data$hr,
bg=c("red","green")[as.factor(data$dead)], pch=c(21,22)[as.factor(data$dead)]) Сообщение отредактировал p2004r - 27.09.2011 - 09:49
Эскизы прикрепленных изображений
 |
|
|
|
|

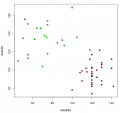
|
|
|
27.09.2011 - 10:33
Сообщение
#3
|
||
|
Группа: Пользователи Сообщений: 1325 Регистрация: 27.11.2007 Пользователь №: 4573 |
Конечно две группы, одни умерли, а другие живы. Давление и пульс коррелируют друг с другом, а с зависимой переменной коррелируют с разными знаками, поэтому экспоненциальный коэффициент для давления меньше единицы, а для пульса больше, но оба значимы в общей модели в этом примере.
Эскизы прикрепленных изображений
|
|
|
|
|


|
|
|
27.09.2011 - 12:06
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(DrgLena @ 27.09.2011 - 09:33) Конечно две группы, одни умерли, а другие живы. это не очевидно, например по росту или полу данный набор не будет представлять из себя две группы |
|
|
|
|
|
|
27.09.2011 - 17:47
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 1325 Регистрация: 27.11.2007 Пользователь №: 4573 |
Я думаю, что матрица корреляций предикторов вырождена, т.е. нельзя вычислить обратную матрицу. Иногда при этом корреляции искусственно уменьшают путем прибавления малой константы к диагональным элементам матрицы, потом вычисляют обратную. В данном случае важно оценить каждый предиктор, а не их совместное влияние, поскольку они сильно коррелируют между собой.
И лучше перейти к бинарным значениям, тогда снижение давления ниже 105 и повышение рульса более 112 - фатальны для состояния "1", вероятность практически =100%. А для количественных показателей повышение пульса на 1 удар или снижение давление на 1 мм.рт.ст влияет на шанс в 1,23 и в 0,81 раз. |
|
|
|
|
|
|
27.09.2011 - 19:15
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Благодарю откликнувшихся!
>p2004r Это задача множественной логистической регрессии. Она неоднократно обсуждалась на форуме, поэтому я и не стал подробно описывать данные. Задача: найти зависимость бинарного отклика "смерть" одновременно от двух количественных показателей. В R видел разные варианты, но, возможно, проще через обобщённую линейную модель с биномиальным откликом и связующей функцией logit. Интересно, что для этого примера выдаст R, но я быстро в ней не сработаю:(( В программе которой пользовался получил следующие результаты. Модель целиком: отношение правдоподобия = 70,852; df=2; Р<0,0001. Параметры модели: Пульс. Коэффициент = 5,6651 +/- 1167,5605; Р=0,9961; САД. Коэффициент = -3,6163 +/- 751,7844; Р=0,9962; Константа=-246,7322 При использовании бутстрепа стандартные ошибки коэффициентов регрессии получаются намного меньше, но всё равно это намного хуже по сравнению с результатами бинарных логистических регрессий по отдельным параметрам. >DrgLena. Вероятно так и есть, что-то там выродилось... В принципе все показатели (их у меня 5) количественные - можно было и дискриминантную функцию построить. Но хотелось логистическую модель, чтобы выдавала именно вероятности летального исхода. У нас данных много - в динамике до исхода: выздоровление (перевод из реанимации) или смерть. Я взял данные на момент исхода. Хотел построить модель и посмотреть её прогнозные свойства на тех же пациентах, но с использованием данных, собранных за сутки до исхода, за 2 суток, за 7 и т.п. Т.е хотел посмотреть как далеко она сохранит свою высокую диагностическую эффективность. В идеале хотели построить интегральную шкалу тяжести состояния пациента, по которой можно в динамике оценивать его состояние. А на практике врачи ориентируются именно по тому принципу как вы описали, т.е. по выходу отдельных показателей из коридора условной нормы. Но если использовать отдельные показатели - не знаю как объединить их в единую схему??? |
|
|
|
|
|
|
27.09.2011 - 21:24
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 377 Регистрация: 18.08.2008 Из: Москва Златоглавая Пользователь №: 5224 |
Цитата(DrgLena @ 27.09.2011 - 18:47) Я думаю, что матрица корреляций предикторов вырождена, т.е. нельзя вычислить обратную матрицу. Коэффициент корреляции между параметрами САД и Пульс, посчитанный в Excel, равен r=-0,67. Значение модуля r близко к 1, следовательно, данные предикторы сильно связаны. Уважаемые люди, вроде Пэтри и Сэбина в книге "Наглядная статистика в медицине" не рекомендуют использовать высококоррелированные переменные в анализе множественной регрессии именно из-за их большой зависимости.
Сообщение отредактировал DoctorStat - 27.09.2011 - 21:25 Просто включи мозги => http://doctorstat.narod.ru
|
|
|
|
|
|
|
27.09.2011 - 21:47
Сообщение
#8
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 27.09.2011 - 18:15) Благодарю откликнувшихся! >p2004r Это задача множественной логистической регрессии. Она неоднократно обсуждалась на форуме, поэтому я и не стал подробно описывать данные. Задача: найти зависимость бинарного отклика "смерть" одновременно от двух количественных показателей. В R видел разные варианты, но, возможно, проще через обобщённую линейную модель с биномиальным откликом и связующей функцией logit. Интересно, что для этого примера выдаст R, но я быстро в ней не сработаю:(( В программе которой пользовался получил следующие результаты. Модель целиком: отношение правдоподобия = 70,852; df=2; Р<0,0001. Параметры модели: Пульс. Коэффициент = 5,6651 +/- 1167,5605; Р=0,9961; САД. Коэффициент = -3,6163 +/- 751,7844; Р=0,9962; Константа=-246,7322 При использовании бутстрепа стандартные ошибки коэффициентов регрессии получаются намного меньше, но всё равно это намного хуже по сравнению с результатами бинарных логистических регрессий по отдельным параметрам. это буквально пара строк, Вы совершенно зря не пытаетесь использовать R Код > glm(data$dead ~ data$hr + data$ad, family=binomial(link = "logit")) Call: glm(formula = data$dead ~ data$hr + data$ad, family = binomial(link = "logit")) Coefficients: (Intercept) data$hr data$ad -274.905 6.304 -4.021 Degrees of Freedom: 51 Total (i.e. Null); 49 Residual Null Deviance: 70.85 Residual Deviance: 1.278e-08 AIC: 6 Предупреждения 1: glm.fit: алгоритм не сошелся 2: glm.fit: возникли подогнанные вероятности 0 или 1 anova(glm(data$dead ~ data$hr + data$ad, family=binomial(link = "logit"))) Analysis of Deviance Table Model: binomial, link: logit Response: data$dead Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 51 70.852 data$hr 1 50.118 50 20.734 data$ad 1 20.734 49 0.000 Предупреждения 1: glm.fit: алгоритм не сошелся 2: glm.fit: возникли подогнанные вероятности 0 или 1 > summary(glm(data$dead ~ data$hr + data$ad, family=binomial(link = "logit"))) Call: glm(formula = data$dead ~ data$hr + data$ad, family = binomial(link = "logit")) Deviance Residuals: Min 1Q Median 3Q Max -6.880e-05 -2.100e-08 -2.100e-08 2.100e-08 7.463e-05 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -274.905 425613.449 -0.001 0.999 data$hr 6.304 3173.929 0.002 0.998 data$ad -4.021 2071.585 -0.002 0.998 (Dispersion parameter for binomial family taken to be 1) Null deviance: 7.0852e+01 on 51 degrees of freedom Residual deviance: 1.2781e-08 on 49 degrees of freedom AIC: 6 Number of Fisher Scoring iterations: 25 Предупреждения 1: glm.fit: algorithm did not converge 2: glm.fit: fitted probabilities numerically 0 or 1 occurred PS по моему обычный lda в этой ситуации даст великолепную модель для прогноза Сообщение отредактировал p2004r - 27.09.2011 - 21:54 |
|
|
|
|
|
|
27.09.2011 - 21:49
Сообщение
#9
|
|
|
Группа: Пользователи Сообщений: 1325 Регистрация: 27.11.2007 Пользователь №: 4573 |
DoctorStat, это справедливо для любой множественной регрессии. В данном случае полезно посмотреть именно динамику показателей при двух различных исходах дисперсионным анализом для повторных измерений, с тем чтобы уловить время, когда появляется повышение пульса и снижение давления, предиктором может быть именно разница этих или и других показателей и эти разницы могут входить в логистическую модель.
В моделях с полным разделением, как в данном случае, статистические тесты ненаждежны. Для этого примера, одна из программ выдает предупреждение: ******** WARNING ******** WARNING ******** WARNING ******** WARNING ******** Your dataset had COMPLETE SEPARATION which means that the maximum likelihood routine did NOT converge so the statistical tests are not valid. Although the prediction equations correctly classified all of your data, they may not do so for other observations. Complete Separation often occurs because your sample size is too small. ******** WARNING ******** WARNING ******** WARNING ******** WARNING ******** В этих условиях, сколько программ, столько и коэффициентов разных получится. Сообщение отредактировал DrgLena - 27.09.2011 - 22:11 |
|
|
|
|
|
|
4.10.2011 - 13:01
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(p2004r @ 28.09.2011 - 00:47) это буквально пара строк, Вы совершенно зря не пытаетесь использовать R ... PS по моему обычный lda в этой ситуации даст великолепную модель для прогноза Пытаюсь! Но только когда сильно прижмёт))) Задам вопрос в ветке по R. Про дискриминантный анализ мысль сразу была (см. сообщение #6), но в медицинских работах сейчас популярны именно модели на основе логистической регрессии. Её коэффициенты легко пересчитываются в отношения шансов (Odds ratio) к которым все привыкли, в отличие от показателей факторной структуры канонической дискриминантной функции. >DrgLena, DoctorStat. Да, всё так. И коррелированность показателей высокая, и разделение групп однозначное. Причём не только для тех двух, что выложил, а для всех 5-6 что отобрал для регрессии. Дискриминантный анализ даёт только одну ось, что, по сути, и говорит о такой простой корреляции. В принципе, это - закономерно. Организм реагирует на приближающуюся смерть или на выздоровление комплексно: что-то увеличивается, что-то уменьшается. В динамике отслеживать эти паттерны сложно, инструментария не хватает. Встречал работы, где ключевые для состояния пациента паттерны в продольных (longitudinal) исследованиях находят алгоритмами Data mining, но для меня это далеко. Да и сами данные слабоваты; это не стройная кардиограмма или энцефалограмма, а обычные рваные больничные данные с многочисленными дырами как по показателям, так и по временным точкам. Попробуем ещё для логрегресии взять не последний день, а что-нибудь пораньше или с дискриминантной функцией поковыряюсь - как она на более ранних сроках себя покажет... |
|
|
|
|
|
|
4.10.2011 - 17:26
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 4.10.2011 - 12:01) Попробуем ещё для логрегресии взять не последний день, а что-нибудь пораньше или с дискриминантной функцией поковыряюсь - как она на более ранних сроках себя покажет... Можно строить траекторию каждого больного (по типу Parallel Coordinates Plot) и по данным траекториям проводить кластерный анализ... Код library("kml") myCld<-as.cld(generateArtificialLongData()) kml(myCld,nbRedrawing=3,print.cal=TRUE,print.traj=TRUE) try(choice(myCld)) library("kml3d") myCld<-generateArtificialLongData(c(15,15,15)) kml(myCld,nbRedrawing=3) try(choice(myCld)) plot3d(myCld) В случае lda наверное надо проводить его накопительно, модель на n-й день даблюдения должна включать в себя все предыдущие дни, а обучаться по известному итогу. Проверить её можно каким нибудь складным ножём, исключая каждый раз одну точку и делая прогноз именно для неё. Или полноценный бутстреп учинить (в каждом из исходов). |
|
|
|
|
|
|
23.03.2012 - 12:59
Сообщение
#12
|
|
|
Группа: Пользователи Сообщений: 63 Регистрация: 20.03.2012 Из: Ташкент Пользователь №: 23582 |
Цитата(nokh @ 27.09.2011 - 21:15) Но хотелось логистическую модель, чтобы выдавала именно вероятности летального исхода. У нас данных много - в динамике до исхода: выздоровление (перевод из реанимации) или смерть. Я взял данные на момент исхода. Хотел построить модель и посмотреть её прогнозные свойства на тех же пациентах, но с использованием данных, собранных за сутки до исхода, за 2 суток, за 7 и т.п. Т.е хотел посмотреть как далеко она сохранит свою высокую диагностическую эффективность. В идеале хотели построить интегральную шкалу тяжести состояния пациента, по которой можно в динамике оценивать его состояние. А на практике врачи ориентируются именно по тому принципу как вы описали, т.е. по выходу отдельных показателей из коридора условной нормы. Но если использовать отдельные показатели - не знаю как объединить их в единую схему??? Логистическая регрессия - это один искусственный нейрон и он весьма ограничен в своих возможностях. В Вашей задаче вероятность летального исхода низка только в случае если САД на высоком уровне, а пульс на низком. В остальных трех вариантах комбинаций вероятность должна возрастать. Для одиночного искусственного нейрона такая задача не по зубам, т.к. здесь отсутствует линейная сепарабельность. Поэтому для решения необходимо некоторое усложнение. Вот, например, файл Excel, который решает Вашу задачу, т.е. выдает вероятности летального исхода по САД и пульсу.  DeathProbability.zip ( 1,79 килобайт )
Кол-во скачиваний: 227
DeathProbability.zip ( 1,79 килобайт )
Кол-во скачиваний: 227Сообщение отредактировал YVR - 23.03.2012 - 13:39 Yury V. Reshetov |
|
|
|
|
|
|
30.03.2012 - 13:15
Сообщение
#13
|
||
 Группа: Пользователи Сообщений: 49 Регистрация: 3.03.2012 Из: USA Пользователь №: 23536 |
Цитата(nokh @ 27.09.2011 - 04:42) Впервые столкнулся с ситуацией, когда отдельные показатели высоко статистически значимы в отдельных моделях бинарной регрессии. Однако при объединении в множественной регрессии они становятся резко незначимыми (р порядка 0,99), хотя сама модель значима и обладает 100%-ной чувствительностью и специфичностью. Для файла примера выбрал только 2 показателя - систолическое артериальное давление и пульс. Как быть? Как показать такую модель и как ей верить? Привет, nokh! Почитала Ваш пост. Попросила почитать его одного профи, который считал мои данные. Вот что он написал мне. Во-первых, странно, что всего используется лишь 2 предиктора. Это даже как-то сомнительно, ведь в реальной практике мы собираем десятки показателей. Далее относительно необратимости матрицы. Здесь тоже неверное утверждение. Такое, как я поняла из беседы с ним, возможно лишь при явной мультиколлинеарности, т.е. когда имеем коэфф-ты корреляции у которых модуль равен 1. Здесь такого нет. Я переслала ему Ваш массив, он его обработал и сказал, что нужно использовать пошаговый отбор предикторов задав нулевое значение свободного члена. И вот что он получил: Процент конкордации равен 98.6% , Somers' D= 0.976. В уравнении остаётся только САД. ROC-кривую привожу в приложении. Успеха! Татьяна.
Эскизы прикрепленных изображений
|
|
|
|
|

|
|
|
31.03.2012 - 11:10
Сообщение
#14
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Можно еще попробовать оценить модель методом инструментальных переменных IV (Instrumental Variable), взяв в качестве инструмента самое простое, что есть в природе: IV=САД/Пульс или Пульс/САД (что больше понравится). Тогда ни о какой м/коллинеарности речи не будет, но инструмент может оказаться слабым.
|
|
|
|
|
|
|
3.04.2012 - 23:58
Сообщение
#15
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Larina Tatjana @ 30.03.2012 - 13:15) Привет, nokh! Почитала Ваш пост. Попросила почитать его одного профи, который считал мои данные. Вот что он написал мне. Во-первых, странно, что всего используется лишь 2 предиктора. Это даже как-то сомнительно, ведь в реальной практике мы собираем десятки показателей. Далее относительно необратимости матрицы. Здесь тоже неверное утверждение. Такое, как я поняла из беседы с ним, возможно лишь при явной мультиколлинеарности, т.е. когда имеем коэфф-ты корреляции у которых модуль равен 1. Здесь такого нет. Я переслала ему Ваш массив, он его обработал и сказал, что нужно использовать пошаговый отбор предикторов задав нулевое значение свободного члена. И вот что он получил: Процент конкордации равен 98.6% , Somers' D= 0.976. В уравнении остаётся только САД. ROC-кривую привожу в приложении. Успеха! Татьяна. Вы на график простой давление-пульс смотрели? Какая мультиколлинеарность?! Здесь коэффициент корреляции "ложный". Данные _полностью_ разделены на две группы. Именно наличием этого разделения и объясняется наличие коэффициента корреляции. Вы так тонко тролите? |
|
|
|
|
|
|