Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум врачей-аспирантов _ Медицинская статистика _ Регрессия Кокса
Автор: Alex_Z 9.01.2012 - 23:18
Немного запутался. Подскажите, пожалуйста.
Есть две группы больных. Основная и сравнения. Для обеих групп определяю факторы риска смерти по методу регрессии Кокса. Получаю коэффициент регресии и его ст.ошибку, хи-квадрат, р-значение, отношение шансов и 95%. Так вот, в основной группе фактором риска является высеваемая флора (метод высоко эффективен при грамотрицательной флоре) - это закономерно и ожидаемо. Больных с грамотрицательной флорой умерло на самом деле меньше. В группе сравнения летальность при грам-, грам+, грам+/- примерно одинаковая и флора фактором риска не является. Могу ли я сказать, что у больных основной группы достоверно снизилась вероятность умереть при грам- сепсисе? Как выразить это численно?
2. Еще вопрос по регрессии. Можно ли одновременно задавать в качестве предикторных переменных переменные, которые тесно коррелируют между собой. Как я понял из литературы - это крайне нежелательно. А что тогда делать? Просто у меня в анализе выжимаемости регрессией Кокса факторами риска являются как локализация первичного очага, так и высеваемая микрофлора. Разумеется, часто (хоть и не всегда) определенной локализации процесса соответвует определенная конкретная микрофлора. Что более важно и удобно с клинической точки зрения - флора или локализация - сказать сложно. У меня четыре градации признака "локализация" и три градации признака "флора". Что делать? Использовать простой регрессионный анализ отдельно для каждого фактора?
Автор: DrgLena 10.01.2012 - 11:27
В какой программе проводите кокс- регрессию?
Автор: Alex_Z 10.01.2012 - 11:30
SPSS v.17
Автор: DrgLena 10.01.2012 - 11:51

Уже хорошо. А в каком виде анализировалась переменная локализация, ведь фактором риска является определенная локализация относительно другой. Мне пришлось рецензировать работу в которой локализация кодировалась 1,2,3,4,5 и загонялась в Statistica как количественная переменная. С флорой - тоже. Возможно, две группы это условность, а при анализе выживаемости метод лечения, или тот признак , который разбил на две группы может быть предиктором, как и другие факторы.
Автор: Alex_Z 10.01.2012 - 12:25
Как я понял, в регрессии Кокса определяется как вырастет риск при увеличении предикторной переменной на единицу значения. Так? Или как увеличится риск в случае дихотомической переменной - да/нет.
А как быть, если необходимо проанализировать влияние номинальных переменных (я так понимаю, закодировав локализацию я получил такую шкалу) с тремя - четырьмя возможными значениями?
Автор: Alex_Z 10.01.2012 - 14:04
О! SPSS можно выделить часть ковариант как категориальные... Это решение?
http://translate.google.ru/translate?hl=ru&sl=en&tl=ru&u=http%3A%2F%2Ffaculty.chass.ncsu.edu%2Fgarson%2FPA765%2Fcox.htm&anno=2 Вот тут, если я правильно понял, сказано, что SPSS может ввести "фиктивные" переменные, если обозначить их как категориальные. Т.е. я смогу использовать данные "как есть"?
"Dummy variables. Whereas SPSS will create dummy variables automatically if a variable is declared categorical suing the Categorical button (see the figure above), this must be done explicitly in Stata"
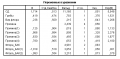
Автор: Alex_Z 10.01.2012 - 15:12
Вот, что получил... А почему SPSS не показывает коэффициент для "Причина" и "Флорп_бак".
Поясню. Причина - фактор, локализация. 1,2,3,4 и 5 - значения.
Флора_бак - флора. Значения 1,2,3.
|
Автор: Игорь 10.01.2012 - 20:04
Есть две группы больных. Основная и сравнения. Для обеих групп определяю факторы риска смерти по методу регрессии Кокса.
Очевидно, имеется в виду модель пропорциональных рисков Кокса. Возьмите модуль анализа выживаемости и анализа данных типа времени жизни Survival Analysis программного обеспечения AtteStat. Там сделан подробный обзор и дается возможность расчета. Правда, работает только под Windows (версия для современных операционных систем появится еще не скоро).
Автор: DrgLena 10.01.2012 - 20:44
Прежде чем пользоваться любой программой, нужно понимать принцип метода и особенности работы с переменными разного типа.
Для того, чтобы понять как логистическая или кокс регрессия работает с категориальными переменными, поймите сначала что такое относительный риск, грибы есть (1), грибов нет (0). Как вы трактуете коэффициент? Что значит 1,521? А теперь посмотрите, как программа предложила вам закодировать имеющиеся локализации, в отчете этого модуля есть такая табличка, а не только та, что вы привели. Коэффициенты будут зависеть от выбора, который вы сделаете при работе с категориальными переменными.
А что AtteStat предлагает для номинальных переменных, нужно предварительно создать бинарные для каждой категории локализации? Или все же предикторы могут быть только количественными?
Автор: Alex_Z 10.01.2012 - 21:05
DrgLena
Я так понимаю, что при обнаружении грибов, шанс (или риск) того, что наступил событие 1 (смерть) увеличится в 1,521 раз. Или на 152,1% Если я правильно понял, что Exp(B) - это отношение шансов. Верно?
Вы про эту таблицу?
Игорь, спасибо, постараюсь уже разбираться с SPSS. А то вообще мозги закипят.

|
Автор: DrgLena 10.01.2012 - 21:35
Теперь вам понятно, почему для последних категорий этих двух переменных коэффициент не нужен? Относительно этих категорий вы риски и считаете, а могли бы и другой выбор сделать, зависит от ваших предварительных знаний о роли каждой категории. А чем все же две группы отличаются, почему вы создаете отдельные модели для каждой?
Автор: DrgLena 10.01.2012 - 21:41
Я так понимаю, шанс (или риск) того, что наступил событие 1 (смерть) увеличится в 1,521 раз. Или на 152,1%
Нет, не правильно "в" это не "на". ПО вашему, если риск увеличивается в 1 раз, то это на 100%?
Автор: Alex_Z 10.01.2012 - 22:00
"Нет, не правильно "в" это не "на". ПО вашему, если риск увеличивается в 1 раз, то это на 100%?"
Да, понял ошибку. А если коэффициент меньше, одного, то снижается в 0,ХХХ раз?
"А чем все же две группы отличаются, почему вы создаете отдельные модели для каждой?"
Группа один - основная, там применен исследуемый метод лечения (эффективен при грамотрицательном сепсисе). Группа два - сравнения. То есть, если я вас правильно понял, больных обеих групп нужно объеденить и оценить факторы риска для больных обеих групп одновременно? И НЕпроведение процедуры будет фактором риска? Просто я хотел показать, что 1) процедура эффективна - оцениваем клиническую динамику, которая достоверно лучше, чем в группе сравнения; 2) построить кривые Каплан-Меера - показать, что выживаемость увеличилась в основной группе (сноска*); 3) показать, что при применении этого метода лечения у больных вид высеваемых бактерий - фактор риска, для группы сравнения - нет, т.к. у них шансы умереть от любой флоры примерно равны. Мой алгоритм неверен?
Т.е. для номинативных факторов, в которых больше двух градаций, выбрать "нулевой" уровень, относительно которого будет идти сравнение? МДа...тогда надо думать как поступить...
* я так понимать, это можно сделать тестами лог-ранк и Бреслоу? А не скажете чем они отличаются? Я где-то читал, что один из них более отражает достоверность на начальных этапах, а другой на поздних. Это верно? А где примерная граница применения этих тестов? Не могу никак снова найти этот источник.
Автор: DrgLena 10.01.2012 - 23:17
Анализ зависит от того что планировалось, как формировались группы. Если они отличались только методом лечения, то его эффективностью и будет знак и оценка коэффициента кокс регрессии, который будет учитывать и флору и локализацию и другие факторы.
К-М кривые могут демонстрировать различия. Анализируя кривые вы можете выбрать срок наблюдения, когда различия будут особенно выражены и доказательства направить на эти сроки.
Относительно тестов, Гехана-Вилкоксона, рекомендуют в тех случаях, когда различия кривых более выражены в начальный период наблюдения, а также в случаях, когда не выполняется модель пропорциональных рисков. Когда риски пропорциональны рекомендуется Кокс и Лог-ранг тесты. Критерий Кокса более чувствителен к обнаружению различий на концах распределения. Лог-ранговый рекомендуется, когда число смертей мало. Но эти тесты в Statistica, а что в SPSS ?посмотрите сами, вам до оценки моделей еще далеко, разберитесь с кодировкой предикторов, можно снизить число градаций путем их объединения до ?плохих? и ?хороших? относительно выживания, флора тоже может быть подвержена редуцированию, кроме того могут быть созданы переменные объединяющие и локализацию и флору , например зловредные с плохой локализацией и альтернатива, как вам подсказывают ваши наблюдения.
Автор: Alex_Z 10.01.2012 - 23:55
Спасибо большое за разъяснения и советы. Буду много думать...
Ну дело в том, что на самом деле, грамотрицательная флора чаще всего выявляется при локализации инфекции в трансплантате (мочевая система). И эффективность при этом наиболее высока, это факт. Но все равно хочется отдельно анализировать эти два фактора. А если сделать новые факторы? Скажем, по флоре - только грам"-" (да/нет), "смешанная" (да/нет), грам"+" (да/нет). И таким же образом поступить с локализацией? Можно так поступить?
А, наверное, я не так выразился. При оценке связи между номинальными признаками используется коэффициент не корреляции, а сопряженности? Достаточно ли будет при описании связи привести сам коэффициент и значимость?
Автор: DrgLena 11.01.2012 - 11:06
Моелирование - это есть поиск зависимостей, но не увлекайтесь, если ваши группы гетерогенны по факторам более значимым, чем те, что вы изучаете.
Автор: Alex_Z 11.01.2012 - 14:37
А позволите еще вопрос?
Факторы лучше анализировать вместе или отдельно? Или в каких случаях как? От набора факторов значительно может меняться достоверность некоторых из них.
Автор: Игорь 11.01.2012 - 17:55
Факторы лучше анализировать вместе или отдельно? Или в каких случаях как? От набора факторов значительно может меняться достоверность некоторых из них.
Позволю себе процитировать из справки AtteStat (относительно логистической регрессии, но в данном случае прием может также сработать):
"Сравнительная оценка прогностической ценности параметров представлена в работе Плавинской с соавт., причем в качестве альтернативы классической m-мерной множественной логистической регрессии использованы m логистических регрессий для каждого параметра объекта в отдельности. Данный эффективный прием может быть легко реализован пользователем настоящего программного обеспечения путем простой манипуляции с исходными данными, в том числе и для других родственных методов распознавания.
...
Список литературы
...
Плавинская С.И., Плавинский С.Л., Шестов Д.Б. Прогностическая значимость основных факторов риска у женщин по данным популяционного исследования и шкала риска смерти от ССЗ // Российский семейный врач, 2006, N 4, с. 4-9."
Автор: Alex_Z 11.01.2012 - 19:22
Игорь, спасибо! Очень интересно. Пока не могу ее найти. У вас ее нет? Если в и-нете не найду, в ЦНМБ поеду.
Автор: Alex_Z 11.01.2012 - 20:05
Перед тем как провести анализ Кокса нужно проверять факторы на корреляцию? И каким способом это лучше делать? Можно оценить связь между всеми сразу факторами папарно (их 6 штук, в каждом число градаций 2-5). Или оценивать наличие связей попарно вручную?
Автор: DrgLena 11.01.2012 - 22:44
Интересно, как вы эту самую корреляцию посчитаете между локализацией и флорой, например. Это что количественные переменные или упорядоченные категории? Начнитие изучение статистики, корреляция - не медицинский термин.
Автор: DrgLena 11.01.2012 - 22:48
Почитайте, что такое независимое влияние фактора риска. Оценка фактора в одновариантной и мультивариантной логистической регрессии будет различной.
Автор: Игорь 12.01.2012 - 05:43
Корреляцию - никак. Связи типа корреляции - можно.
Попарно посчитать корреляцию и связи типа корреляции. Почему "вручную"? - Программы есть.
Автор: Alex_Z 12.01.2012 - 09:39
"Вручную" - это я имел в виду несколько раз оценить параметры попарно. Считаю все, конечно, не "вручную", а в SPSS. Просто когда оцениваю корреляцию коэффициентом Спирмена, то в SPSS можно загнать сразу все параметры, и программа попарно сама все сравнить. Выдаст таблицу, где в столбце и строке будут эти параметры, а в ячейках - уровни значимости. А в хи-квадрат нужно создать несколько "попарных" расчетов. Вот, что я имел в виду.
Я считал, что наличие связей между качественными переменными можно оценить при помощи хи-квадрат Пирсона. Нет? И если эти связи выявлены, то одновременно учитывать эти факторы в модели Кокса вроде как некорректно. Вот, так я считал...
Автор: Alex_Z 12.01.2012 - 10:24
Я правильно понимаю, что поскольку сравниваю именно наминативные признаки, то беру только первую строку в таблице "симметричные меры"?
И нужно ли все таки оценивать связь между признаками, прежде чем оценивать их как факторы риска в регрессионном анализе?

|
Автор: Игорь 12.01.2012 - 16:33
Никогда с SPSS (да и другими проприетарными пакетами) сам не работал - не смогу помочь.
Вообще говоря, никто этого не требует. Корреляционная связь между количественными признаками или связь типа корреляции между неколичественными или разнородными признаками при ее наличии начинает "мешать" корректному проведению расчета. Если расчет проходит без ошибок, я бы проверять не стал.
Но вот если корреляционные связи существенны, тогда необходимо выявить такие факторы - называется "проблема мультиколлинеарности". Для этого есть специальные методы (не помню уже, рассматривалась ли проблема на данном форуме). Удобный метод называется "алгоритм Фаррара-Глаубера, который фактически представляет собой совокупность трех методов, о которых подробно рассказано в ряде источников. Есть источники на английском и на украинском языках. Программно метод реализован в бесплатном пакете ME.com, доступном для скачивания с сайта проекта AtteStat (у этих двух проектов - общая математическая библиотека). Там же есть необходимые ссылки.
Автор: 100$ 12.01.2012 - 17:33
Мулитиколлинеарность факторов чаще всего является (относительнвм) злом в случае оценивании модели методом наименьших квадратов (МНК). Т.к. этот метод оценивания в регрессии Кокса неприменим, то и беспокоиться особо не о чем.
Автор: DrgLena 12.01.2012 - 17:38
Нет, не правильно.
Alex_Z' Никакие строки из приведенной таблицы вам не нужны. К вашим чисто номинальным признакам понятие мультиколлинеарности не относится. Мультиколлинеарность ? это множественная совместная линейность. Высокая, вернее, точная коллинеарность означает, что регрессоры не являются линейно независимыми и в этом случае линейнозависимые коэффициенты оценить невозможно. Как с этом бороться - читать, читать?
Автор: DrgLena 12.01.2012 - 17:44
http://translate.google.com.ua/translate?hl=ru&sl=en&tl=ru&u=http%3A%2F%2Fwww.springerlink.com%2Findex%2F7441m22xrh170194.pdf&anno=2
Автор: Игорь 12.01.2012 - 17:51
Да, в регрессии Кокса применяется метод максимального правдоподобия (подробный вывод формул в AtteStat-е есть). А важна или нет мультиколлинеарность, можно посмотреть на реальных расчетах. Мне, честно говоря, не хочется. Но если кто-то возьмет на себя заботу проверить какой-нибудь пример, ознакомлюсь с интересом.
К сожалению, хорошо знаком с обсуждаемым предметом лишь с вычислительной стороны, поэтому практически лучше делать так, как говорит уважаемая DrgLena.
Автор: DrgLena 12.01.2012 - 19:04
По имеющимся фрагментам информации, я бы не советовала использовать кокс регрессию
Автор: 100$ 12.01.2012 - 19:10
Таки беспокоиться все равно не о чем

Автор: Игорь 13.01.2012 - 05:28
Возможно, шокирую уважаемых собеседников, но в большей части темы мы обсуждаем то, чего не существует. То, о чем здесь говорилось, называется не регрессией Кокса, а моделью пропорциональных рисков Кокса (сам тоже виноват).
Регрессией Кокса можно было бы назвать знаменатель левой части модели Кокса. Но и это название неверное, т.к. даная функция обычно называется по имени аппроксимирующей функции - например, регрессией Гомпертца, регрессией Вейбулла.
Автор: Alex_Z 13.01.2012 - 07:17
Спасибо уважаемым гуру статистики!
Форум Invision Power Board (http://www.invisionboard.com)
© Invision Power Services (http://www.invisionpower.com)