Здравствуйте, гость ( Вход | Регистрация )
 Форум врачей-аспирантов » Все сообщения пользователя
Форум врачей-аспирантов » Все сообщения пользователя
| Отправлено: 1.12.2021 - 00:04 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Camel1000 @ 30.11.2021 - 17:37)  Всем добрый день. Совершенно запутался в вопросе дисперсии отношений двух случайных величин. Если у нас есть выборка 1 (12 значений), описываемая средним арифметическим A (что, как я понимаю, является грубой оценкой матожидания) и дисперсией Sa, и выборка 2 (12 значений), описываемая средним арифметическим B и дисперсией Sb, то какова будет дисперсия S(a/b) отношения A и И, Спасибо заранее, Camel1000 Для конкретных параметров легче легкого Код > quantile(replicate(100000, mean(rnorm(10, mean=1,sd=2))/mean(rnorm(14, mean=2,sd=1))), probs=c(0.025,0.5,0.975)) 2.5% 50% 97.5% -0.1213920 0.5002085 1.1963876 > quantile(replicate(100000, mean(rnorm(10, mean=10,sd=2))/mean(rnorm(14, mean=2,sd=1))), probs=c(0.025,0.5,0.975)) 2.5% 50% 97.5% 3.818239 4.996390 6.911531 Ну и видим 4 сигмы соответственно. Можно сразу писать sd() вместо quantile() |
| Форум: Медицинская статистика · Просмотр сообщения: #27047 · Ответов: 6 · Просмотров: 8219 |



| Отправлено: 19.11.2021 - 18:57 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
|
| Форум: Медицинская статистика · Просмотр сообщения: #27044 · Ответов: 0 · Просмотров: 6283 |
| Отправлено: 15.10.2021 - 00:51 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Engeneer @ 14.09.2021 - 19:24) В Планах Плакета-Бурмана создается матрица эксперимента, в которой "+" это максимальный уровень фактора, "-" минимальный уровень фактора. В случае если мы рассматриваем 3 уровневый факторный эксперимент, существует так называемые "звездные точки", "звездное плечо" см. подробнее https://works.doklad.ru/view/eK433Y2roMs/all.html и https://portal.tpu.ru/departments/kafedra/i...b/KonspPExp.pdf и http://window.edu.ru/catalog/pdf2txt/524/2...p_page=19(поиск по названию звезд) не понятно как поступать, когда фактором является вещество. а именно меняется от 0 до 100 по массе в веществе. при использовании скажем звездного плеча 1,498 мы должны массу вещества взять 149,8 процентов. это бред. как поступать? заранее спасибо! В эксперименте вы восстанавливаете градиент в окрестностях выбранной точки. Поэтому выбираете шаг изменения на котором градиент гладкий и его можно свести к линейной модели. Точку в которой вы проводите эксперимент вы выбираете из каких то соображений (у биологических систем еще и стабилизирована эта точка бывает). Обычно потом просто идут (смещают точку) в направлении градиента (как правило оно отображает нечто что вы оптимизируете). Чаще всего вся поверхность градиента в сумме обладает некими нелинейностями. Иногда ошибки-шумы такие большие что рассмотреть что то на поверхности не удается. Если восстановить поверхность градиента полностью мы получаем фазовый портрет системы и можем думать начинать как она устроена на качественном уровне. |
| Форум: Медицинская статистика · Просмотр сообщения: #27023 · Ответов: 18 · Просмотров: 31962 |
| Отправлено: 15.09.2021 - 22:43 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Blaid @ 9.09.2021 - 16:34) Да, количественная. Прикрепляю файл с данными. Корреляция между плотностью загрязнения (количественным предиктором) и удельной активностью (переменной отклика) имеет R2 равный 0,66. Т.е. явно вариация удельной активности обусловлена не только (и может быть не столько) плотностью загрязнения территории. Прежде чем включать какие либо предикторы в модель, надо убедиться что эти предикторы вообще имеют связь с моделируемой переменной. На основании приложенных данных простая рандомизация показывает, что строить что либо сложнее модели "Удельная активность Cs-137 в древесине, Бк/кг ~ плотность загрязнения, Ки/кв. км + Черничный " нет никаких. |
| Форум: Медицинская статистика · Просмотр сообщения: #26987 · Ответов: 13 · Просмотров: 15467 |
| Отправлено: 24.06.2021 - 17:06 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Choledochus @ 10.06.2021 - 13:35) После каких сочетаний клавиш в SPSS получается выделить главный компонент? Можно по-простому. В учебниках пока не разобрался, хотя есть несколько. Спасибо Процедуру рандомизации для собственных значений разложения матрицы с данными делают вручную (или какой то пакет используют где тесты "на наличие простой структуры в pca(fa) реализованы). |
| Форум: Медицинская статистика · Просмотр сообщения: #26825 · Ответов: 8 · Просмотров: 14722 |
| Отправлено: 14.04.2021 - 15:17 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Duncle @ 14.04.2021 - 10:04) Добрый день, уважаемые коллеги! Готовлю небольшую статью. Была проведена электромиография 30 пациентам. У всех выявлен гипертонус некоторых мышц. Далее расслабляли мышцы по 2 методам (15 человек по одному методу, и 15 по другому). Результаты примерно одни и те же. Как статистически сравнить более точно и вывести статистически, что достоверных различий нет. Курс статистики прошёл мимо из-за COVID   , пожалуйста, кто может. Отблагодарю , пожалуйста, кто может. Отблагодарю  Можно писать в ЛС Всегда поражало что к статистикам как к докторам приходят когда "уже поздно пить боржоми"ТМ. План уже проведенного исследования весьма "античен", сейчас оба варианта воздействия (если оно конечно заключается не в "ампутации головы") проводят последовательно (и группы просто разным порядком отличаются). Обязательна "группа плацебо" должна быть. Ну и "мощность", "размер эффекта", "уровень значимости"... вот это всё "скучное и не нужное"tm определяют "до", а ни в коем случае не "после того как". |
| Форум: Медицинская статистика · Просмотр сообщения: #26744 · Ответов: 7 · Просмотров: 13960 |
| Отправлено: 1.08.2020 - 17:13 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Choledochus @ 1.08.2020 - 16:28) Есть два значения (КЛТР двух разных силиконов) 354 и 368. Дисперсия, ошибка среднего и т.д. неизвестны. Тем не менее можно что-то сказать о них? Есть ли значимые различия между ними или нет? Или ничего сказать невозможно? Ну хоть что-то можно заявить? Спасибо. Если есть результаты поверки приборов на которых эти попугаи получены, то ответ "да". PS а в каком хабзае это спрашивают на тестах? |
| Форум: Медицинская статистика · Просмотр сообщения: #25978 · Ответов: 4 · Просмотров: 13309 |
| Отправлено: 27.06.2020 - 18:18 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Логично здесь выглядит Survival analysis |
| Форум: Медицинская статистика · Просмотр сообщения: #25847 · Ответов: 4 · Просмотров: 6489 |
| Отправлено: 26.06.2020 - 20:32 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 24.06.2020 - 20:30) Благодарю всех откликнувшихся! Если у форумчан есть время и желание прикрепляю свои объекты. А где вот эти "овалы", что на картинке "по отдельности"? |
| Форум: Медицинская статистика · Просмотр сообщения: #25844 · Ответов: 15 · Просмотров: 153233 |
| Отправлено: 23.06.2020 - 18:18 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 23.06.2020 - 09:43) Имеется несколько выборок образцов с измеренными в ImageJ показателями размеров и формы. Посчитана описательная статистика. Теперь я хочу найти образец, наиболее типичный для каждой выборки по комплексу показателей и использовать его контур в качестве иллюстрации для всей выборки. Подскажите, пожалуйста, каким методом проще всего найти типичный образец и что использовать: среднее, медиану, моду? Может есть готовые рекомендации для таких задач? Спасибо! Если доступна форма объекта, то есть традиционная морфометрия с её методиками выведения "средней формы".
Прикрепленные файлы
|
| Форум: Медицинская статистика · Просмотр сообщения: #25830 · Ответов: 15 · Просмотров: 153233 |

| Отправлено: 9.06.2020 - 20:57 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Voevod @ 9.06.2020 - 19:30) Лет 15 назад и у меня были аналогичные ситуации в своём исследовании. И только когда обратился к профессионалам в [Название фирмы удалено администратором форума], понял, что такие подходы просто примитивны. Поскольку весьма продуктивные результаты получил от них по методам многомерного анализа. Вот и написал потом эти результаты в зарубежных журналах. Также рекомендую свой вопрос записывать более подробно. Если используете таблицу сопряжённости, то и вводите её. То есть ваш вопрос не полностью подробен. Желаю успеха! Это так толсто, что даже уже тонко. |
| Форум: Медицинская статистика · Просмотр сообщения: #25806 · Ответов: 5 · Просмотров: 6936 |
| Отправлено: 7.05.2020 - 23:33 | ||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(comisora @ 30.04.2020 - 16:08) Вопрос: можно ли каким-то образом связать оценки экспертов с рейтинговыми данными? Сочинить смешанную модель с бета-распределением не хватает навыка. Смотрел single-case analysis и arima - остро не хватает данных. медитируйте над результатом ps похоже 19ый скоррелировал с "агенствами" ))
Эскизы прикрепленных изображений
|
|
| Форум: Медицинская статистика · Просмотр сообщения: #25733 · Ответов: 2 · Просмотров: 4630 |

| Отправлено: 7.05.2020 - 23:15 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
так как тут помочь? связи никакой в данных нет кроме годов общих две вот эти таблицы по сути каноническую корреляцию по трем строкам (года) с пропущенными значениями в довесок посчитать разве что? )))Код > acast(expert, type ~ year, value.var="rate", median) 2015 2017 2019 a 0.7500000 0.1578947 0.7894737 d 0.6930000 0.7500000 0.7720000 n 0.8750000 0.9583333 0.9583333 r 0.9761905 0.9761905 0.9761905 > acast(expert, expert ~ year ~ type, value.var="neg") , , a 2015 2017 2019 exp_1 -1.5177168 -1.2039728 -0.5773154 exp_10 NA -1.4663371 -0.5653138 exp_11 NA -2.0149030 -2.0794415 exp_12 -1.3862944 1.3862944 -2.4423470 exp_13 0.2744368 -0.4054651 -0.6931472 exp_14 -2.0149030 -1.6094379 -2.3025851 exp_15 -1.3247816 -2.0946317 -1.4136933 exp_16 -2.5649494 -2.5649494 -2.3025851 exp_17 NA -1.0986123 -1.3862944 exp_18 -0.9162907 -2.1400662 -2.5520460 exp_19 0.0000000 -1.6094379 -0.6931472 exp_2 -0.9162907 -2.3025851 -2.5649494 exp_20 -0.9985288 -0.1541507 0.4054651 exp_21 -0.6190392 0.0000000 0.5596158 exp_22 -1.7047481 -2.5649494 -1.3862944 exp_23 -1.9459101 -2.9444390 -3.4339872 exp_3 NA NA -4.5432948 exp_4 -1.5968591 -3.2958369 -1.5892352 exp_5 -2.2553322 -2.2512918 1.2237754 exp_6 -2.3025851 -2.6390573 -1.6094379 exp_7 NA -1.9459101 -3.6109179 exp_8 -0.9162907 -1.6094379 0.0000000 exp_9 NA -0.5108256 -1.9459101 , , d 2015 2017 2019 exp_1 -1.5177168 -1.2039728 -0.5773154 exp_10 NA -1.4663371 -0.5653138 exp_11 NA -2.0149030 -2.0794415 exp_12 -1.3862944 1.3862944 -2.4423470 exp_13 0.2744368 -0.4054651 -0.6931472 exp_14 -2.0149030 -1.6094379 -2.3025851 exp_15 -1.3247816 -2.0946317 -1.4136933 exp_16 -2.5649494 -2.5649494 -2.3025851 exp_17 NA -1.0986123 -1.3862944 exp_18 -0.9162907 -2.1400662 -2.5520460 exp_19 0.0000000 -1.6094379 -0.6931472 exp_2 -0.9162907 -2.3025851 -2.5649494 exp_20 -0.9985288 -0.1541507 0.4054651 exp_21 -0.6190392 0.0000000 0.5596158 exp_22 -1.7047481 -2.5649494 -1.3862944 exp_23 -1.9459101 -2.9444390 -3.4339872 exp_3 NA NA -4.5432948 exp_4 -1.5968591 -3.2958369 -1.5892352 exp_5 -2.2553322 -2.2512918 1.2237754 exp_6 -2.3025851 -2.6390573 -1.6094379 exp_7 NA -1.9459101 -3.6109179 exp_8 -0.9162907 -1.6094379 0.0000000 exp_9 NA -0.5108256 -1.9459101 , , n 2015 2017 2019 exp_1 -1.5177168 -1.2039728 -0.5773154 exp_10 NA -1.4663371 -0.5653138 exp_11 NA -2.0149030 -2.0794415 exp_12 -1.3862944 1.3862944 -2.4423470 exp_13 0.2744368 -0.4054651 -0.6931472 exp_14 -2.0149030 -1.6094379 -2.3025851 exp_15 -1.3247816 -2.0946317 -1.4136933 exp_16 -2.5649494 -2.5649494 -2.3025851 exp_17 NA -1.0986123 -1.3862944 exp_18 -0.9162907 -2.1400662 -2.5520460 exp_19 0.0000000 -1.6094379 -0.6931472 exp_2 -0.9162907 -2.3025851 -2.5649494 exp_20 -0.9985288 -0.1541507 0.4054651 exp_21 -0.6190392 0.0000000 0.5596158 exp_22 -1.7047481 -2.5649494 -1.3862944 exp_23 -1.9459101 -2.9444390 -3.4339872 exp_3 NA NA -4.5432948 exp_4 -1.5968591 -3.2958369 -1.5892352 exp_5 -2.2553322 -2.2512918 1.2237754 exp_6 -2.3025851 -2.6390573 -1.6094379 exp_7 NA -1.9459101 -3.6109179 exp_8 -0.9162907 -1.6094379 0.0000000 exp_9 NA -0.5108256 -1.9459101 , , r 2015 2017 2019 exp_1 -1.5177168 -1.2039728 -0.5773154 exp_10 NA -1.4663371 -0.5653138 exp_11 NA -2.0149030 -2.0794415 exp_12 -1.3862944 1.3862944 -2.4423470 exp_13 0.2744368 -0.4054651 -0.6931472 exp_14 -2.0149030 -1.6094379 -2.3025851 exp_15 -1.3247816 -2.0946317 -1.4136933 exp_16 -2.5649494 -2.5649494 -2.3025851 exp_17 NA -1.0986123 -1.3862944 exp_18 -0.9162907 -2.1400662 -2.5520460 exp_19 0.0000000 -1.6094379 -0.6931472 exp_2 -0.9162907 -2.3025851 -2.5649494 exp_20 -0.9985288 -0.1541507 0.4054651 exp_21 -0.6190392 0.0000000 0.5596158 exp_22 -1.7047481 -2.5649494 -1.3862944 exp_23 -1.9459101 -2.9444390 -3.4339872 exp_3 NA NA -4.5432948 exp_4 -1.5968591 -3.2958369 -1.5892352 exp_5 -2.2553322 -2.2512918 1.2237754 exp_6 -2.3025851 -2.6390573 -1.6094379 exp_7 NA -1.9459101 -3.6109179 exp_8 -0.9162907 -1.6094379 0.0000000 exp_9 NA -0.5108256 -1.9459101 |
| Форум: Медицинская статистика · Просмотр сообщения: #25732 · Ответов: 2 · Просмотров: 4630 |
| Отправлено: 6.05.2020 - 10:58 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Robotnik @ 4.05.2020 - 15:11) "9"? Что за "9"? Я нигде не упоминал его. Да и нет никакого "сакрального" числа. Вы о чём? Вы _просто_ ответить способны? 9 значимо выбивается из "великого полиноминольного математического распределения"ТМ. Имеет ли значение "9 повреждений" для (например) "оценки тыжести преступления"? |
| Форум: Медицинская статистика · Просмотр сообщения: #25727 · Ответов: 14 · Просмотров: 11673 |
| Отправлено: 4.05.2020 - 14:52 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Robotnik @ 3.05.2020 - 19:08) А что за случай с 43 повреждениями? Ну вот такой случай. Это не ошибка, я сам все наблюдения анализировал и перепроверял потом. Но я так понимаю, что это статистический выброс, поэтому он не влияет на общую картину. Благодарю всех за ответы! Буду думать и, если что, спрошу ещё. Только можно ещё сразу сейчас кое-что прояснить для себя: 1). Я построил гистограмму и распределение было сильно смещено влево: наиболее часто встречались наблюдения, где повреждение было одно или два (n = 69 и n = 68, соответственно). При этом я имею медиану, равную 4 и её 95%-ый интервал от трёх до четырёх. Объясните мне, глупому, разве здесь нет противоречия? Согласно медиане и её интервалу в генеральной совокупности встречаются преимущественно случаи, в которых повреждения варьируют от 3 до 4, а если посмотреть на гистограмму, то больше наблюдений, где повреждений от одного до двух максимум. 2). Как интерпретировать межквартильный размах? Вот у меня он равен 5 (Q3-Q1 или 7 - 2 = 5). Это что значит? Эту меру разброса можно как-то переносить на генеральную совокупность? И почему вы писали, что размах предпочтительнее в моём случае? а "9" это какое то "сакральное" число в практике судебной? |
| Форум: Медицинская статистика · Просмотр сообщения: #25713 · Ответов: 14 · Просмотров: 11673 |
| Отправлено: 3.05.2020 - 13:22 | |||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Рисуйте зависимость вероятности для измерения оказаться меньше заданного значения от величины этого значения с доверительным интервалом 95% (по идее это полностью описывает распределение выборочное и пределы оценки для распределения генсовокупности). В полулогарифмических лучше выглядит для вашей выборки вот так. PS Можно в виде кучи боксплотов изобразить (для каждого числа повреждений отдельный ящик на общем графике), но очень уж плотный получается тогда график.
Эскизы прикрепленных изображений
|
||
| Форум: Медицинская статистика · Просмотр сообщения: #25704 · Ответов: 14 · Просмотров: 11673 |
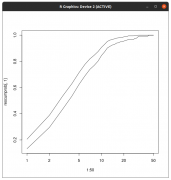
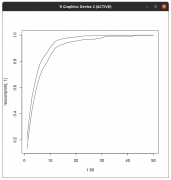
| Отправлено: 4.04.2020 - 08:37 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(passant @ 4.04.2020 - 00:08) Уважаемые коллеги-медики. Итак, формальная постановка задачи. Необходимо подтвердить H0 гипотезу отсутствия различий между двумя наборами данных. ебе "многомерная проверка гипотез". Это невозможная постановка задачи. Нулевую гипотезу можно только отвергнуть, при произвольно выбранных трех параметров (и вычисленном четвертом) из четырех 1-2)ошибках первого-второго родов, 3)размере эффекта, 4) размер группы. Ну вот для каждого из исследований в выборке метаанализа проводите этот расчет-перерасчет и "приводите к обозримому одновременно виду". Например размер выборки уже "прибит гвоздями" и константа в пострассмотрении, значит "по этой оси ставим точку", остальные три переменных "живут в пространстве размерности минус один", значит они будут в виде "плоскости проходящей через точку размера выборки". Ну и остальные исследования так же "перегоняем". Размер эффекта по сути эквивалентен этакому "одностороннему доверительному интервалу", по его оси (её направление в построенном пространстве можно и восстановить) его и откладываем "от нуля". Картину перекрывающихся "интервалов эффектов" от исследований "глубокомысленно изучаем" и делаем выводы. "Математически" в этой задаче (работе с результатами исследования "как целого") думаю ничего больше нет. А сами техники можно посмотреть в https://cran.r-project.org/web/views/MetaAnalysis.html Вот например метапакет визуализации результатов https://cran.r-project.org/web/packages/met...es/metaviz.html |
| Форум: Медицинская статистика · Просмотр сообщения: #25559 · Ответов: 17 · Просмотров: 17013 |
| Отправлено: 4.04.2020 - 08:15 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 4.04.2020 - 05:52) Благодарю за мнения и код! Попробую всё-таки ещё свой вариант, интересно будет сравнить с результатом р2004r. По поводу Сайсон - Глаза ничего не читал, но мне решительно не понравился ноль в качестве нижней границы. Получается так: по набору в 73 объекта частота почти 9,5%, а нижняя граница ноль. Причём не 0.0001, что и так нереалистично мало, а вообще 0.00000000. Т.е. по-сути, метод говорит, что несмотря на то, что в выборке у меня оказалось почти 10%, если я продолжу процесс извлечения выборок, то в 95% выборок не обнуружу ни одного объёта такой категории. Не верю. Поэтому более склонен довериться моделированию. Последнее для меня очень затратно по времени написания кодов, но может за самоизоляцию и получится (как ни странно, сейчас времени вообще нет: в НИИ дана команда сидеть дома и писать статьи на год вперёд))), а в универе народ у кого занятий много вообще вешается с этой дистанционкой...) Возьмите готовые доверительные интервалы отсюда https://cran.r-project.org/web/packages/Ternary/index.html |
| Форум: Медицинская статистика · Просмотр сообщения: #25558 · Ответов: 6 · Просмотров: 6745 |
| Отправлено: 2.04.2020 - 09:49 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 2.04.2020 - 09:24) Раньше считал (вероятно не совсем корректно) ДИ для долей всегда методами для биномиального распределения. Т.е., например, в ряду абсолютных частот 4-х категорий {13, 35, 18, 7} с суммой n=73 доля первой категории f=13/73*100%=17,8%. Для неё находил 95% ДИ методом Клоппера - Пирсона или в полседнее время методом Джеффриса (байесовский априорный интервал): [10,4; 27,7]. Сейчас решил посчитать ДИ для полиномиального распределения, думал, что раз информации больше, то они Уже будут. Ничего подобного. R-пакет DescTool считает одновременные ДИ для полиномиалного распределения функцией MultinomCI. library(DescTools) x<-c(13,35,18,7) MultinomCI(x) est lwr.ci upr.ci [1,] 0.17808219 0.06849315 0.3006248 [2,] 0.47945205 0.36986301 0.6019947 [3,] 0.24657534 0.13698630 0.3691180 [4,] 0.09589041 0.00000000 0.2184330 По умолчанию считает ДИ методом Сайсона - Глаза по SAS-овскому алгоритму. Всё хуже, чем даже биномиальный Клоппер - Писон, который ругают за консервативность. Видно, что для 7 (9,6%) нижняя граница вообще ноль. Более адекватные результаты даёт только метод Уилсона: > MultinomCI(x, method="wilson") est lwr.ci upr.ci [1,] 0.17808219 0.10713373 0.2812173 [2,] 0.47945205 0.36877454 0.5921840 [3,] 0.24657534 0.16204465 0.3564445 [4,] 0.09589041 0.04722895 0.1849564 Воросы: 1) Каким способом считаете вы? 2) Хочу попробовать сделать бутстреп. Думаю так: многократно пробублировать набор 4 типов в соотношении 13 : 35 : 18 : 7 и извлекать из него с возвратом случайные выборки размером n=73; для каждогго типа потом рассчитать ДИ методом процентилей. Корректно так будет организовать? Для долей надо "восстановить" выборку в виде объектов с признаками замеренными. После этого или 1) перемешиваем признаки (рандомизация) и получаем "доверительный интервал для 0-гипотезы". Или 2) извлекаем "с возвращением" перевыборки и считаем в каждой нужные нам доли, следим за "сходимостью процентилей долей в накопленной выборке", как только достигнутая точность нас устраивает прекращаем. Код > d <- c(rep(1, 13), rep(2, 35), rep(3, 18), rep(4, 7)) > table(d) d 1 2 3 4 13 35 18 7 > length(d) [1] 73 > dd <- replicate(100000, table(sample(factor(d), replace=T))) > str(dd) int [1:4, 1:100000] 12 36 15 10 12 37 16 8 17 40 ... - attr(*, "dimnames")=List of 2 ..$ :8322456 [1:4] "1" "2" "3" "4" ..$ : NULL > sapply(1:nrow(dd), function(i) quantile(dd[i,], probs=c(0.025,0.5,0.975))) [,1] [,2] [,3] [,4] 2.5% 7 27 11 3 50% 13 35 18 7 97.5% 20 43 25 12 PS ну и конечно нарисовать все эти доверительные интервалы можно только в виде тернарных графиков (придется перегруппирование небольшое делать, что бы размерности хватило, хотя можно в виде 3д пирамиды в данном конкретном примере). |
| Форум: Медицинская статистика · Просмотр сообщения: #25545 · Ответов: 6 · Просмотров: 6745 |
| Отправлено: 4.03.2020 - 23:22 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(p2004r @ 27.02.2020 - 14:31) https://invisioncommunity.com/forums/topic/...-elasticsearch/ Как бы снабдить каждую открытую тему блоком верстки (например в самый низ страницы вынесенном), где автоматом показаны топ-10 самых релевантных остальных тем из истории форума в которых обсуждается та же самая тема, что и поднятая в данной открытой теме? PS ну и проиндексировать в Elasticsearch всю историю форума естественно под это дело Версия 4.3+ поддерживает нормальный поиск. https://invisioncommunity.com/news/product-...ovements-r1062/ Elasticsearch In Invision Community 4.3 we are adding native support for Elasticsearch, a third party search engine which offers a number of benefits over searching your MySQL database: Elasticsearch, being designed and indexing data in a way optimised for search rather than data storage, is generally able to match and sort by relevancy with better accuracy than MySQL. Elasticsearch is generally faster. One user performing a search doesn't slow down other users trying to read and make posts at the same time (when searching MySQL, the data has to be "locked" from changes when the search is being performed). It scales very well with very large datasets, and runs very easily on multiple servers. Elasticsearch understands language. If for example, you search for "community", it will also return results which contain the word "communities", understanding that these are the same. Supported languages are Arabic, Armenian, Basque, Brazilian, Bulgarian, Catalan, Chinese, Czech, Danish, Dutch, English, Dinnish, Drench, Galician, German, Greek, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Korean, Latvian, Lithuanian, Norwegian, Persian, Portuguese, Romanian, Russian, Sorani, Spanish, Swedish, Turkish, Thai. Elasticsearch supports custom functions on the scoring algorithm. In our initial implementation this has allowed us to add settings to allow you to control the time decay (allowing newer results to show higher) and author boost (allowing content posted by the user to optionally show higher in results). Unlike with MySQL, there is no minimum query length and a very small list of stop words. |
| Форум: Разное · Просмотр сообщения: #25405 · Ответов: 2 · Просмотров: 4495 |
| Отправлено: 27.02.2020 - 14:31 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
https://invisioncommunity.com/forums/topic/...-elasticsearch/ Как бы снабдить каждую открытую тему блоком верстки (например в самый низ страницы вынесенном), где автоматом показаны топ-10 самых релевантных остальных тем из истории форума в которых обсуждается та же самая тема, что и поднятая в данной открытой теме? PS ну и проиндексировать в Elasticsearch всю историю форума естественно под это дело Вот как то в духе этого руководства https://qbox.io/blog/practical-guide-elasti...oring-relevancy |
| Форум: Разное · Просмотр сообщения: #25390 · Ответов: 2 · Просмотров: 4495 |
| Отправлено: 23.02.2020 - 13:03 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Felix77 @ 23.02.2020 - 11:36) Коэффициенты корреляций между предикторами слабые - 0.14-0.36. И с чего вдруг мультиколлинеарность больше чем допустимо. Не понимаю! Код > car::vif(modkim) Анемия Объем.контраста возраст 5.584514 5.157870 1.400406 Generally, VIF for an X variable should be less than 4 in order to be accepted as not causing multi-collinearity. The cutoff is kept as low as 2, if you want to be strict about your X variables. ЗЫ Код > glm(КИН ~ Объем.контраста + возраст , kinm, family=binomial(link="logit")) Call: glm(formula = КИН ~ Объем.контраста + возраст, family = binomial(link = "logit"), data = kinm) Coefficients: (Intercept) Объем.контраста возраст -16.17699 4.67647 0.07174 Degrees of Freedom: 300 Total (i.e. Null); 298 Residual Null Deviance: 220.4 Residual Deviance: 60.04 AIC: 66.04 > car::vif(glm(КИН ~ Объем.контраста + возраст , kinm, family=binomial(link="logit"))) Объем.контраста возраст 1.014424 1.014424 |
| Форум: Медицинская статистика · Просмотр сообщения: #25373 · Ответов: 8 · Просмотров: 7225 |
| Отправлено: 23.02.2020 - 10:39 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Felix77 @ 23.02.2020 - 09:34) Доброго времени суток! Модель вроде бы адекватная (зависимая переменная - КИН), 3 предиктора - объем контраста, возраст, анемия (есть или нет). Но вот отношения шансов получаются какие-то очень высокие. Intercept) Анемия1 возраст Объем.контраста 4.991232e-15 4.267894e+03 1.167138e+00 2.609896e+03 1. У вас разделены данные по КИН без всяких моделей и сомнений. "Просто глазами" разделяемы. 2. Предикторы мультиколлинеарны более чем допустимо, значит значения коэффициентов модели содержательно интерпретировать нельзя. Но судя по п.1 сильно не уменьшиться. Цитата(Felix77 @ 23.02.2020 - 10:15) А что не так то? Ага |
| Форум: Медицинская статистика · Просмотр сообщения: #25371 · Ответов: 8 · Просмотров: 7225 |
| Отправлено: 23.02.2020 - 10:09 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Felix77 @ 23.02.2020 - 09:37) [attachment=1880:Регрессия.xlsx] Данные здесь Внимательнее данные готовьте, тут шутников и так хоть ртом ешь. |
| Форум: Медицинская статистика · Просмотр сообщения: #25368 · Ответов: 8 · Просмотров: 7225 |
| Отправлено: 23.01.2020 - 17:09 | |
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Зайдите на https://cran.r-project.org/view=Cluster и почитайте подраздел Model-Based Clustering. |
| Форум: Медицинская статистика · Просмотр сообщения: #25177 · Ответов: 13 · Просмотров: 10182 |
 Открытая тема (есть новые ответы) Открытая тема (есть новые ответы) Открытая тема (нет новых ответов) Открытая тема (нет новых ответов) Горячая тема (есть новые ответы) Горячая тема (есть новые ответы) Горячая тема (нет новых ответов) Горячая тема (нет новых ответов) |
 Опрос (есть новые голоса) Опрос (есть новые голоса) Опрос (нет новых голосов) Опрос (нет новых голосов) Закрытая тема Закрытая тема Тема перемещена Тема перемещена |