Здравствуйте, гость ( Вход | Регистрация )

  |

 12.06.2018 - 08:32 12.06.2018 - 08:32
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 10 Регистрация: 30.04.2018 Пользователь №: 31313 |
 пожалуйста, можно ли из имеющихся данных создать модель для прогнозирования. В прилагаемой таблице представлены переменные пациентов, у которых в последствии развилась контраст индуцированная нефропатия (КИН), соответственно зависимая переменная - КИН (0-не развилась КИН, 1 - развилась). Пытался использовать логистическую регрессию, которая не показала значимого влияния предикторов. Пытался применить Random Forest, в R ничего не получилось. Может проблема в большом количестве пропущенных данных пожалуйста, можно ли из имеющихся данных создать модель для прогнозирования. В прилагаемой таблице представлены переменные пациентов, у которых в последствии развилась контраст индуцированная нефропатия (КИН), соответственно зависимая переменная - КИН (0-не развилась КИН, 1 - развилась). Пытался использовать логистическую регрессию, которая не показала значимого влияния предикторов. Пытался применить Random Forest, в R ничего не получилось. Может проблема в большом количестве пропущенных данных
Прикрепленные файлы
|
 |
 
|



 |
|
|
12.06.2018 - 09:23
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 231 Регистрация: 27.04.2016 Пользователь №: 28223 |
Цитата(Felix77 @ 12.06.2018 - 08:32)  пожалуйста, можно ли из имеющихся данных создать модель для прогнозирования. В прилагаемой таблице представлены переменные пациентов, у которых в последствии развилась контраст индуцированная нефропатия (КИН), соответственно зависимая переменная - КИН (0-не развилась КИН, 1 - развилась). Пытался использовать логистическую регрессию, которая не показала значимого влияния предикторов. Пытался применить Random Forest, в R ничего не получилось. Может проблема в большом количестве пропущенных данных пожалуйста, можно ли из имеющихся данных создать модель для прогнозирования. В прилагаемой таблице представлены переменные пациентов, у которых в последствии развилась контраст индуцированная нефропатия (КИН), соответственно зависимая переменная - КИН (0-не развилась КИН, 1 - развилась). Пытался использовать логистическую регрессию, которая не показала значимого влияния предикторов. Пытался применить Random Forest, в R ничего не получилось. Может проблема в большом количестве пропущенных данныхЯ ничего не понимаю в медицинской стороне вопроса, но первое, что бросилось в глаза - сильная несбалансированность обучающей выборки - примерно 1:9. Возможно, стоить посмотреть в сторону методов, специально предназначенные для таких случаев? Сообщение отредактировал passant - 12.06.2018 - 09:23 |
|
|
|
|
|
|
13.06.2018 - 12:43
Сообщение
#3
|
|||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
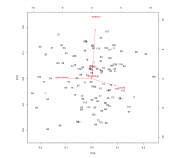
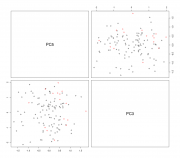
Цитата(Felix77 @ 12.06.2018 - 08:32) пожалуйста, можно ли из имеющихся данных создать модель для прогнозирования. В прилагаемой таблице представлены переменные пациентов, у которых в последствии развилась контраст индуцированная нефропатия (КИН), соответственно зависимая переменная - КИН (0-не развилась КИН, 1 - развилась). Пытался использовать логистическую регрессию, которая не показала значимого влияния предикторов. Пытался применить Random Forest, в R ничего не получилось. Может проблема в большом количестве пропущенных данныхКод df.cin <- data.table::fread("./CIN.csv", dec=",") str(df.cin) df.cin$КИН <- as.factor(df.cin$КИН) df.cin$пол <- as.factor(df.cin$пол) df.cin$поч_функц <- as.factor(df.cin$поч_функц) library(mice) md.pattern(df.cin) library(randomForestSRC) ?rfsrc res.rfsrc <- rfsrc(КИН~., data=na.omit(df.cin[,-1]), case.wt = randomForestSRC:::make.wt(na.omit(df.cin)$КИН), sampsize = randomForestSRC:::make.size(na.omit(df.cin)$КИН), ntree = 5000) res.rfsrc <- rfsrc(КИН~., data=df.cin[,-1], case.wt = randomForestSRC:::make.wt(df.cin$КИН), sampsize = randomForestSRC:::make.size(df.cin$КИН), na.action = "na.impute") res.rfsrc <- rfsrc(КИН~., data=df.cin[,-1], na.action = "na.impute") res.rfsrc randomForestSRC::var.select(res.rfsrc, nrep = 40) > res.rfsrc Sample size: 116 Frequency of class labels: 100, 16 Number of trees: 5000 Forest terminal node size: 1 Average no. of terminal nodes: 8.6332 No. of variables tried at each split: 3 Total no. of variables: 9 Analysis: RF-C Family: class Splitting rule: gini Normalized Brier score: 80.79 Error rate: 0.27, 0.22, 0.56 Confusion matrix: predicted observed 0 1 class.error 0 78 22 0.2200 1 9 7 0.5625 Overall error rate: 26.72% > randomForestSRC::var.select(res.rfsrc, nrep = 40) minimal depth variable selection ... ----------------------------------------------------------- family : class var. selection : Minimal Depth conservativeness : medium x-weighting used? : TRUE dimension : 9 sample size : 116 ntree : 5000 nsplit : 0 mtry : 3 nodesize : 1 refitted forest : FALSE model size : 5 depth threshold : 2.9802 PE (true OOB) : 0.2672 0.22 0.5625 Top variables: depth vimp возраст 2.633 NA тропонин 2.783 NA КФК2 2.944 NA калий 2.950 NA креатинин 2.976 NA ----------------------------------------------------------- > Вполне себе выделяет... Правда что то разумное сказать почему выделяет как то не очень получается... ну возрас большой, калий большой, малый креатинин ??? Но какое то решающее правило не выводиться, да и случайный лес меняет показания постоянно... Код data.cin.pca <- data.frame(КИН=na.omit(df.cin[,-c(1,4,6,8,10)])[,c("КИН")],
prcomp(na.omit(df.cin[,-c(1,3,4,6,8,10)]), center = T, scale. = T)$x) data.cin.pca$КИН <- as.factor(data.cin.pca$КИН) res.pca.rfsrc <- rfsrc(КИН~., data=data.cin.pca, case.wt = randomForestSRC:::make.wt(data.cin.pca$КИН), sampsize = randomForestSRC:::make.size(data.cin.pca$КИН), ntree = 5000) res.pca.rfsrc randomForestSRC::var.select(res.pca.rfsrc, nrep = 40) res.pca <- prcomp(na.omit(df.cin[,-c(1,3,4,6,8,10)]), center = T, scale. = T) biplot(res.pca, choices = c(5,3)) pairs(data.cin.pca[,c(6,4)], col = c("black", "red")[data.cin.pca$КИН]) Сообщение отредактировал p2004r - 13.06.2018 - 12:46
Эскизы прикрепленных изображений
 |
||
|
|
|
|
|
|
13.06.2018 - 14:03
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
А вот интересно, почему при выращивании леса узлы расщепляются по Gini, а при селекции переменных используется Minimal Depth? И почему при таком раскладе метод не смог выдать относительную важность предикторов (vimp=NA)? До такой степени плохой датасет?
А чем обусловлен выбор PCA3 vs. PCA5? В первых двух ГК все совсем плохо? |
|
|
|
|
|
|
13.06.2018 - 15:34
Сообщение
#5
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
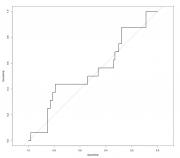
Цитата(100$ @ 13.06.2018 - 14:03) А вот интересно, почему при выращивании леса узлы расщепляются по Gini, а при селекции переменных используется Minimal Depth? И почему при таком раскладе метод не смог выдать относительную важность предикторов (vimp=NA)? До такой степени плохой датасет? А чем обусловлен выбор PCA3 vs. PCA5? В первых двух ГК все совсем плохо? Да просто не включил, в принципе результаты одинаковые всегда по обоим критериям (а время расчета существенно отличается, но тут размер позволяет считать все). Тут модель слишком слаба, скорее даже ничтожна. Код > res.pca.rfsrc Sample size: 118 Frequency of class labels: 102, 16 Number of trees: 5000 Forest terminal node size: 1 Average no. of terminal nodes: 8.3986 No. of variables tried at each split: 3 Total no. of variables: 5 Analysis: RF-C Family: class Splitting rule: gini Normalized Brier score: 85.2 Error rate: 0.32, 0.27, 0.62 Confusion matrix: predicted observed 0 1 class.error 0 74 28 0.2745 1 10 6 0.6250 Overall error rate: 32.2% > randomForestSRC::var.select(res.pca.rfsrc, nrep = 40) minimal depth variable selection ... ----------------------------------------------------------- family : class var. selection : Minimal Depth conservativeness : medium x-weighting used? : TRUE dimension : 5 sample size : 118 ntree : 5000 nsplit : 0 mtry : 3 nodesize : 1 refitted forest : FALSE model size : 2 depth threshold : 2.0305 PE (true OOB) : 0.322 0.2745 0.625 Top variables: depth vimp PC5 1.476 NA PC3 1.833 NA Ну и сама модель (чистого vimp отбора нет в randomForestSRC, только случайный поиск) Код > res.rfsrc <- rfsrc(КИН~., + data=na.omit(df.cin[,-1]), + case.wt = randomForestSRC:::make.wt(na.omit(df.cin)$КИН), + sampsize = randomForestSRC:::make.size(na.omit(df.cin)$КИН), + ntree = 5000, + importance=TRUE) > res.rfsrc Sample size: 116 Frequency of class labels: 100, 16 Number of trees: 5000 Forest terminal node size: 1 Average no. of terminal nodes: 8.6186 No. of variables tried at each split: 3 Total no. of variables: 9 Analysis: RF-C Family: class Splitting rule: gini Normalized Brier score: 80.85 Error rate: 0.28, 0.23, 0.56 Confusion matrix: predicted observed 0 1 class.error 0 77 23 0.2300 1 9 7 0.5625 Overall error rate: 27.59% > randomForestSRC::var.select(res.rfsrc, nrep = 40) minimal depth variable selection ... ----------------------------------------------------------- family : class var. selection : Minimal Depth conservativeness : medium x-weighting used? : TRUE dimension : 9 sample size : 116 ntree : 5000 nsplit : 0 mtry : 3 nodesize : 1 refitted forest : FALSE model size : 5 depth threshold : 2.969 PE (true OOB) : 0.2759 0.23 0.5625 Top variables: depth vimp.all vimp.0 vimp.1 возраст 2.651 0.007 0.016 0.033 тропонин 2.790 0.001 0.006 0.012 КФК2 2.856 0.002 0.008 -0.001 креатинин 2.912 0.002 0.009 -0.001 калий 2.927 0.003 0.008 0.008 ----------------------------------------------------------- > randomForestSRC::var.select(res.rfsrc, nrep = 40, method = "vh.vimp") --------------------- Iteration: 1 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.087 dim: 2 --------------------- Iteration: 2 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 1 --------------------- Iteration: 3 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2609 dim: 1 --------------------- Iteration: 4 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 5 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 6 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.3333 dim: 2 --------------------- Iteration: 7 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1667 dim: 1 --------------------- Iteration: 8 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2083 dim: 2 --------------------- Iteration: 9 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2609 dim: 1 --------------------- Iteration: 10 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 11 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 12 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 13 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.0833 dim: 1 --------------------- Iteration: 14 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 1 --------------------- Iteration: 15 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2174 dim: 2 --------------------- Iteration: 16 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2174 dim: 2 --------------------- Iteration: 17 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2174 dim: 2 --------------------- Iteration: 18 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 1 --------------------- Iteration: 19 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 20 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 21 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2174 dim: 2 --------------------- Iteration: 22 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.375 dim: 1 --------------------- Iteration: 23 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 24 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 25 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.0435 dim: 2 --------------------- Iteration: 26 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.3043 dim: 2 --------------------- Iteration: 27 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 28 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 29 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 30 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.087 dim: 2 --------------------- Iteration: 31 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2083 dim: 2 --------------------- Iteration: 32 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 33 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 --------------------- Iteration: 34 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 35 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1667 dim: 2 --------------------- Iteration: 36 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.25 dim: 1 --------------------- Iteration: 37 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 1 --------------------- Iteration: 38 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.2174 dim: 2 --------------------- Iteration: 39 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1304 dim: 2 --------------------- Iteration: 40 --------------------- selecting variables using Variable Hunting (VIMP) ... PE: 0.1739 dim: 2 fitting forests to final selected variables ... ----------------------------------------------------------- family : class var. selection : Variable Hunting (VIMP) conservativeness : medium dimension : 9 sample size : 116 K-fold : 5 no. reps : 40 nstep : 1 ntree : 500 nsplit : 10 mvars : 2 nodesize : 2 refitted forest : TRUE model size : 1.75 +/- 0.4385 PE (K-fold) : 0.1763 +/- 0.0677 Top variables: rel.freq калий 27.5 тропонин 25.0 ----------------------------------------------------------- > Но собственно качество модели об этом и говорит Код > roc(na.omit(df.cin[,-1])$КИН, predict(res.rfsrc)$predicted.oob[,2]) Call: roc.default(response = na.omit(df.cin[, -1])$КИН, predictor = predict(res.rfsrc)$predicted.oob[, 2]) Data: predict(res.rfsrc)$predicted.oob[, 2] in 100 controls (na.omit(df.cin[, -1])$КИН 0) < 16 cases (na.omit(df.cin[, -1])$КИН 1). Area under the curve: 0.5419
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
13.06.2018 - 16:02
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Понятно.
А у randomForest'a SRC (я даже и не знал о таком, вот уж "век живи ..., а дураком помрешь") есть какие-то очевидные/неочевидные преимущества перед "просто" randomForest? А ROC-кривая и впрямь хороша. Прямо картина маслом. Хоть сейчас в рамку, да на стену. |
|
|
|
|
|
|
13.06.2018 - 19:44
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(100$ @ 13.06.2018 - 16:02) А у randomForest'a SRC (я даже и не знал о таком, вот уж "век живи ..., а дураком помрешь") есть какие-то очевидные/неочевидные преимущества перед "просто" randomForest? Просто {randomForest} это референтная реализация оригинального метода автора прямо по его статье. Например SRC не ограничен в числе уровней факторов в модели. |
|
|
|
|
|
|