Здравствуйте, гость ( Вход | Регистрация )

  |

 6.08.2017 - 14:29 6.08.2017 - 14:29
Сообщение
#46
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 5.08.2017 - 17:10)  p2004r, здравствуйте, решила написать в своем же топике, но теперь тут другой скоринг (Раньше плохой, хороший), а сейчас купит-не купит услугу(id is dep var)  Логистическая регрессия здесь, показала ужасные результаты, почти все нули(те, кто не купили) были правильно к своему классу отнесены, а единицы(те кто купили) также к нулям. Все что смогла сама сделать, это Дискриминантный анализ в SPSS, вроде показал точность 60%, но это ни о чем. Сильная перемешка кейсов. Можете подсказать, как мне модель выровнять? С регрессией что спсс, что статистика также ,как и R показывали такой результат. Тут нужно только через ДА. acc=read.csv("C:/Users/Admin/Desktop/buyning.csv", sep=";",dec=",") getwd() > acc$profitValueList=as.numeric(acc$profitValueList) > acc$revenueValueList=as.numeric(acc$revenueValueList) > acc$courtPracticeList=as.numeric(acc$courtPracticeList) > acc$digestRedList=as.numeric(acc$digestRedList) > acc$digestGreyList=as.numeric(acc$digestGreyList) > acc$digestGreenList=as.numeric(acc$digestGreenList) > acc$linkedEntitiesByCeoNumList=as.numeric(acc$linkedEntitiesByCeoNumList) > acc$linkedEntitiesByFounderNumList=as.numeric(acc$linkedEntitiesByFounderNumList) > acc$linkedEntitiesChildrenNumList=as.numeric(acc$linkedEntitiesChildrenNumList) > acc$capitalList=as.numeric(acc$capitalList) > acc$gosWinnerNumList=as.numeric(acc$gosWinnerNumList) > acc$gosWinnerSumList=as.numeric(acc$gosWinnerSumList) > acc$gosPlacerNumList=as.numeric(acc$gosPlacerNumList) > acc$gosPlacerSumList=as.numeric(acc$gosPlacerSumList) > acc$inspectionsInFutureNumList=as.numeric(acc$inspectionsInFutureNumList) > acc$inspectionsHasViolationsNumList=as.numeric(acc$inspectionsHasViolationsNumList) > acc$inspectionsNoViolationsNumList=as.numeric(acc$inspectionsNoViolationsNumList) > acc$inspectionsHasViolationsFailsList=as.numeric(acc$inspectionsHasViolationsFailsList) > acc$Выручка=as.numeric(acc$Выручка) > acc$Прибыль=as.numeric(acc$Прибыль) > acc$Убыток=as.numeric(acc$Убыток) > acc$Баланс=as.numeric(acc$Баланс) > acc$Директор.Учредитель=as.numeric(acc$Директор.Учредитель) > acc$Директор.отдельно=as.numeric(acc$Директор.отдельно) > acc$Учредитель.отдельно=as.numeric(acc$Учредитель.отдельно) > index <- sample(1:nrow(acc),round(0.75*nrow(acc))) > train <- acc[index,] > test <- acc[-index,] > library("MASS") > fitTrn =lda(id~.,data=train) Error in lda.default(x, grouping, ...) : ошибка была variables 15 16 appear to be constant within groups Как мне хотя бы маломальски точную классификацию получить? Поздравляю, на этот раз "генерация данных" прошла лучше
Эскизы прикрепленных изображений
 |
|
 |
 
|



 |
|
|
6.08.2017 - 14:57
Сообщение
#47
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
у меня AUc=0.55, в R считала, неужели мне никак модель не улучшить?
|
|
|
|
|
|
|
6.08.2017 - 16:39
Сообщение
#48
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 6.08.2017 - 14:57) у меня AUc=0.55, в R считала, неужели мне никак модель не улучшить? Ну вот knn чуть получше себя ведет, может если фичи придумать некие "что то там дифференцирующие вокруг разрешаемого кейза" в данных и станет получше. (это складным ножом верифицировано) Код > table(factor(na.omit(df)$id), FNN::knn.cv(train=prcomp(na.omit(df[, -c(1, 11)]))$x[, 1:9], cl=factor(na.omit(df)$id), k=1)) 0 1 0 3906 469 1 370 106 > table(factor(na.omit(df)$id), FNN::knn.cv(train=prcomp(na.omit(df[, -c(1, 11)]))$x[, 1], cl=factor(na.omit(df)$id), k=1)) 0 1 0 3959 416 1 344 132 "Извлечение фич" это декларируют глубокие сетки, но тут маловато случаев будет. Хотя можно library(keras) (или library(mxnet)) поставить и попробовать. PS можно еще и логарифмировать всё количественное перед pca (оно все "кривое" в плане распределения), может получше тогда свернется размерность Сообщение отредактировал p2004r - 6.08.2017 - 16:58 |
|
|
|
|
|
|
6.08.2017 - 17:53
Сообщение
#49
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Кстати точно, попробую, прологарифмировать.
Подскажите, p2004r, как мне составить уравнение потом. Мне ведь надо не просто принести модель и сказать вот в R есть функция predict, так и предсказывайте программисту нужно сообщить уравнение, чтобы он в CRM для автоматизации запрограммировал. что-то ("mxnet") нет в репозитории. Видимо уже убрали  > install.packages("mxnet") Installing package into ?C:/Users/Admin/Documents/R/win-library/3.3? (as ?lib? is unspecified) Warning in install.packages : package ?mxnet? is not available (for R version 3.3.2) Сообщение отредактировал nastushka - 6.08.2017 - 17:57 |
|
|
|
|
|
|
6.08.2017 - 20:19
Сообщение
#50
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 6.08.2017 - 17:53) Кстати точно, попробую, прологарифмировать. Подскажите, p2004r, как мне составить уравнение потом. Мне ведь надо не просто принести модель и сказать вот в R есть функция predict, так и предсказывайте программисту нужно сообщить уравнение, чтобы он в CRM для автоматизации запрограммировал. что-то ("mxnet") нет в репозитории. Видимо уже убрали > install.packages("mxnet") Installing package into ?C:/Users/Admin/Documents/R/win-library/3.3? (as ?lib? is unspecified) Warning in install.packages : package ?mxnet? is not available (for R version 3.3.2) Для knn "никак", это алгоритм ближайшего соседа и "решение" просто сами данные mxnet https://github.com/apache/incubator-mxnet/t...aster/R-package keras https://rstudio.github.io/keras/ PS если один покупатель делал несколько заказов последовательно и это не отражено в структуре данных, то knn ошибается. Сообщение отредактировал p2004r - 7.08.2017 - 07:34 |
|
|
|
|
|
|
8.08.2017 - 11:45
Сообщение
#51
|
||
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
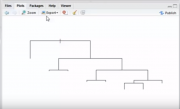
p2004r, подскажите, пожалуйста, а как мне нарисовать графически красиво для программиста, чтобы он уже на базе данных программировал решение. Я проявила сама инициативу хотела через дерево решений нарисовать, но пока не очень хорошо получается.
И вопрос для моего повышения знаний. Если accuracy 90% значит ли это что на других выборках точность правильности определения будет не менее 90% т.е. из 100 наблюдений 90 будут правильно отнесены к своим классам. Или как понять эту цифру.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
8.08.2017 - 19:08
Сообщение
#52
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 8.08.2017 - 11:45) p2004r, подскажите, пожалуйста, а как мне нарисовать графически красиво для программиста, чтобы он уже на базе данных программировал решение. Я проявила сама инициативу хотела через дерево решений нарисовать, но пока не очень хорошо получается. И вопрос для моего повышения знаний. Если accuracy 90% значит ли это что на других выборках точность правильности определения будет не менее 90% т.е. из 100 наблюдений 90 будут правильно отнесены к своим классам. Или как понять эту цифру. почитайте вики сами, там все вполне понятно изложено https://en.wikipedia.org/wiki/Receiver_oper..._characteristic (ну не читать же мне вам это вслух?) а картинку дерева решений рисовать прямо в вигнете есть у library(party) https://cran.r-project.org/web/packages/par...ettes/party.pdf Сообщение отредактировал p2004r - 8.08.2017 - 19:18 |
|
|
|
|
|
|
9.08.2017 - 15:43
Сообщение
#53
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, Ваше мнение, как Вы считаете имеет ли место комбинирование моделей? Т.е.! КNN-очень хорошо отделяет нули от единиц, а вот дискриминантный анализ, после того,как я его дожала, стал отделять единицы от нулей.
Есть ли смысл, сначала использовать КNN, а затем дискриминантный анализ? Т.е. на вход предикторы, на выходе КНН получаем 1, если при этом ДА=1, то итог 1, если ДА =0, то итог=0 Когда на вход предикторы, на выходе КНН получаем 0, если ДА=1, то итог 1, если ДА =0, то итог=0 Корректно ли так будет делать? |
|
|
|
|
|
|
10.08.2017 - 00:16
Сообщение
#54
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 9.08.2017 - 15:43) p2004r, Ваше мнение, как Вы считаете имеет ли место комбинирование моделей? Т.е.! КNN-очень хорошо отделяет нули от единиц, а вот дискриминантный анализ, после того,как я его дожала, стал отделять единицы от нулей. Есть ли смысл, сначала использовать КNN, а затем дискриминантный анализ? Т.е. на вход предикторы, на выходе КНН получаем 1, если при этом ДА=1, то итог 1, если ДА =0, то итог=0 Когда на вход предикторы, на выходе КНН получаем 0, если ДА=1, то итог 1, если ДА =0, то итог=0 Корректно ли так будет делать? Что то посмотрю
|
|
|
|
|
|
|
10.08.2017 - 11:16
Сообщение
#55
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Т.е. вы считаете, что такую верификацию из двух методов лучше не делать?
|
|
|
|
|
|
|
10.08.2017 - 16:50
Сообщение
#56
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 10.08.2017 - 11:16) Т.е. вы считаете, что такую верификацию из двух методов лучше не делать? Вы условия которые написали перечитайте (ну или таблицу исходов какую нарисуйте и сократите "лишнее"). "Складывают" две модели операцией сложения. Например (раз у нас knn при k=1) -1 и 1 это исходы метода1 и -1 и 1 исходы метода2, на выходе имеем с(-2, 0, 2). То есть появилось ещё и "неизвестно". Если есть ещё и "вес" у модели, то "0" удастся избежать. Но есть и нормальный способ обучить ансамбль методов, это взять один из пакетов заточенных именно на такой подход. ensembleR: Ensemble Models in R caretEnsemble: Ensembles of Caret Models classyfire: Robust multivariate classification using highly optimised SVM ensembles |
|
|
|
|
|
|
12.08.2017 - 13:35
Сообщение
#57
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
p2004r, я пробовала работать с тремя этими пакетами, но или у меня руки кривые безнадежно
, или ансамбливое обучение тут не помощник.library("ensembleR") acc1=read.xlsx("C:/Users/Admin/Desktop/buyning.xlsx") index <- sample(1:nrow(acc1),round(0.75*nrow(acc1))) train <- acc1[index,] test <- acc1[-index,] preds <- ensemble(train,test,'id',c('treebag','rpart'),'rpart') Error in train.default(training[, predictors], training[, outcomeName], : Stopping Something is wrong; all the RMSE metric values are missing: RMSE Rsquared Min. : NA Min. : NA 1st Qu.: NA 1st Qu.: NA Median : NA Median : NA Mean :NaN Mean :NaN 3rd Qu.: NA 3rd Qu.: NA Max. : NA Max. : NA NA's :1 NA's :1 ====== library("caretEnsemble") models <- caretList(train,test, methodList=c("glm", "lm")) Error: nrow(x) == n is not TRUE In addition: Warning messages: 1: In trControlCheck(x = trControl, y = target) : trControl$savePredictions not 'all' or 'final'. Setting to 'final' so we can ensemble the models ============== library("classyfire") acco=read.xlsx("C:/Users/admin/Desktop/buyning.xlsx") iClass <- acco[,1] idata <- acco[,-1] ens <- cfBuild(inputData = idata, inputClass = iClass, bootNum = 100, ensNum = 100, parallel = TRUE, cpus = 4, type = "SOCK") а тут такая ошибка Error in .initCheck(inputData, inputClass, bootNum, ensNum, parallel, : Argument "inputData" must contain numeric values. Шах и мат. На что он жалуется то? |
|
|
|
|
|
|
14.08.2017 - 16:27
Сообщение
#58
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nastushka @ 12.08.2017 - 13:35) p2004r, я пробовала работать с тремя этими пакетами, но или у меня руки кривые безнадежно , или ансамбливое обучение тут не помощник.library("ensembleR") acc1=read.xlsx("C:/Users/Admin/Desktop/buyning.xlsx") index <- sample(1:nrow(acc1),round(0.75*nrow(acc1))) train <- acc1[index,] test <- acc1[-index,] preds <- ensemble(train,test,'id',c('treebag','rpart'),'rpart') Error in train.default(training[, predictors], training[, outcomeName], : Stopping Something is wrong; all the RMSE metric values are missing: RMSE Rsquared Min. : NA Min. : NA 1st Qu.: NA 1st Qu.: NA Median : NA Median : NA Mean :NaN Mean :NaN 3rd Qu.: NA 3rd Qu.: NA Max. : NA Max. : NA NA's :1 NA's :1 ====== library("caretEnsemble") models <- caretList(train,test, methodList=c("glm", "lm")) Error: nrow(x) == n is not TRUE In addition: Warning messages: 1: In trControlCheck(x = trControl, y = target) : trControl$savePredictions not 'all' or 'final'. Setting to 'final' so we can ensemble the models ============== library("classyfire") acco=read.xlsx("C:/Users/admin/Desktop/buyning.xlsx") iClass <- acco[,1] idata <- acco[,-1] ens <- cfBuild(inputData = idata, inputClass = iClass, bootNum = 100, ensNum = 100, parallel = TRUE, cpus = 4, type = "SOCK") а тут такая ошибка Error in .initCheck(inputData, inputClass, bootNum, ensNum, parallel, : Argument "inputData" must contain numeric values. Шах и мат. На что он жалуется то? Он же пишет явно на что жалуется  . С таким подходом можно "всю жизнь наверху простоять"ТМ . С таким подходом можно "всю жизнь наверху простоять"ТМ 
|
|
|
|
|
|
|