Здравствуйте, гость ( Вход | Регистрация )

  |

 11.06.2022 - 15:09 11.06.2022 - 15:09
Сообщение
#16
|
|
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Почитал мануал ПАСТа, относительно "permutation t tes" там сказано:
Цитата The permutation test for equality of means uses the absolute difference in means as test statistic. This is equivalent to using the t statistic. The permutation test is non-parametric with few assumptions, but the two samples are assumed to be equal in distribution if the null hypothesis is true. The number of permutations can be set by the user. The power of the test is limited by the sample size ? significance at the p<0.05 level can only be achieved for n>3 in each sample. То есть никакого t там в реальности нет, а тупо модуль разности средних. Попробовал повторить это на R: Код x<-c(221.60112, 305.217725, 295.251684, 371.3313, 397.452722, 437.212724) R<-9999 absdiff<-abs(mean(x[1:3])-mean(x[4:6])) res<-numeric(R) for (i in 1:R) { perm<-sample(x) permdiff<-abs(mean(perm[1:3])-mean(perm[4:6])) if(permdiff>=absdiff) res [i]<-1 } p<-(sum(res)+1)/(R+1) p Получилось уже знакомое p=0,1 с копейками. Откуда они берут p=0,03, тайна сия велика есть. Сообщение отредактировал ИНО - 11.06.2022 - 15:13 |
 |
 
|


 |
|
|
12.06.2022 - 12:43
Сообщение
#17
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(ИНО @ 11.06.2022 - 15:09)  Получилось уже знакомое p=0,1 с копейками. Откуда они берут p=0,03, тайна сия велика есть. А это разовое значение (в смысле, полученное однократно)? Может быть, при повторе расчетов что-то изменится? Спрашиваю потому, что ваш код из предыдущего поста выдал - при R=9 999 p=.1028 - при R=99 999 p=.01 - при R=999 999 p=.1029 Поскольку в эксперименте генерируется повторная выборка (т.е. выборка с возвращением), то в строке perm<-sample(x) желательно уточнить perm<-sample(x,replace=TRUE). Патамушта предельная ошибка повторной и бесповторной выборок вообще-то различаюцца... Сообщение отредактировал 100$ - 12.06.2022 - 12:43 |
|
|
|

|
|
|
13.06.2022 - 19:29
Сообщение
#18
|
|
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Цитата А это разовое значение (в смысле, полученное однократно)? Может быть, при повторе расчетов что-то изменится? Спрашиваю потому, что ваш код из предыдущего поста выдал Естественно, "копейки" будут меняться, если set.seed() не задавать. По-хорошему положено для этого p еще и ДИ строить, но это уже для перфекционистов, и на вывод не повлияет. А вывод в данном случае ошибочный. Цитата perm<-sample(x) желательно уточнить perm<-sample(x,replace=TRUE). Патамушта предельная ошибка повторной и бесповторной выборок вообще-то различаюцца... При классической рандомизации этого не делают: просто случайным образом делят варианты на две выборки, ничего никуда не возвращая. А при replace=TRUE - это уже какой-то гибрид рандомизации с бутстрепом поучится, даже не знаю, бывает ли такой, и какие под ним теоретические основы. Я вообще, сколько не пытался, в теорию бутсрепа не въехал, в конце-концов плюнул, решил, что работает - да и ладно. Но для интереса попробовал свой код с replace=TRUE: получается сильно правдоподобнее, чем просто рандомизация - p=0,027 с копейками, на Уэлча похоже. Но, что интересно, с ПАСТом все равно не совпадает. |
|
|
|
|
|
|
17.06.2022 - 07:34
Сообщение
#19
|
||
|
Группа: Пользователи Сообщений: 1202 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Vitek_22 @ 25.05.2022 - 14:45) ... Посоветуйте, как всё же обработать эти данные. Вот пример исходных цифр: Выборка 1: 221,60112 305,217725 295,251684 Выборка 2: 371,3313 397,452722 437,212724 Не знаю почему уважаемые участники форума не поддержали идею критерия Стьюдента и даже посоветовали непараметрику. Непараметрика, конечно, хороша: тот же критерий Манна - Уитни имеет асимптотическую эффективность 3/пи или 95,5%. Но она именно асимптотическая, т.е. в реальности никогда не достигается)) А на сверхмалых выборках потеря в мощности будет просто чудовищной. Поэтому если есть основания предполагать нормальность, ну или хотя бы не отрицать её жёстко, эта дополнительная информация даст большой выигрыш и тогда, оперевшись на параметрику можно показать, что средние в группах отличаются: t(4)=3,92; p=0,017. По представленным 6 цифрам жёстко предполагать ненормальность нет: часто биологические показатели распределены не нормально, а асимметрично и скорее логнормально. Но тогда есть шанс увидеть в данных варьирование на порядок-два, здесь же данные очень компактно группируются, преобразование данных не просится... Короче, я бы посчитал критерием Стьюдента пока, а по мере накопления данных возможно что-то бы пришлось подправить. Напомню, что есть формула критерия Стьюдента даже для сравнения одного единственного наблюдения с выборкой. По поводу представления средних. Если исходить из нормальности распределения, до можно дать среднее с классическими 95%-ными доверительными интервалами (95% ДИ) : 274,0 [160,6; 387,5] и 402,0 [319,6; 484,4]. Эти ДИ перекрываются (трансгрессируют), что входит в противоречие с идеей наличия различий. А они скорее всего есть, т.к. разность между средними 128,0 имеет 95% ДИ [37,5; 218,5], т.е. не включает ноль, а значит разность ненулевая. Этот 95%-ный ДИ для разности тоже параметрический и вся ситуация говорит о том, что 95% ДИ для средних перекрываются, т.к. рассчитываются изолировано для каждой группы, а ДИ для разности (как и t-критерий Стьюдента) работают с двумя блоками данных одновременно и происходит выигрыш в мощности, который на сверхмалых выборках оказывается решающим. Можно поиграться и бутстрепом, тогда не будет противоречия ни в ДИ для средних, ни в ДИ для разности: 274,0 [221,6; 305,2] и 402,0 [371,3; 437,2] для процентильного метода, ДИ не перекрываются Разность 128,0 [75,6; 177,8] Всё можно посчитать в PAST https://www.nhm.uio.no/english/research/resources/past/ Сообщение отредактировал nokh - 17.06.2022 - 07:36
Эскизы прикрепленных изображений
|
|
|
|
|

|
|
|
17.06.2022 - 12:13
Сообщение
#20
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата Не знаю почему уважаемые участники форума не поддержали идею критерия Стьюдента Патамушта уважаемые участники в курсе проблемы Беренса - Фишера. Поэтому посчитали критерий Уэлча (Welch, 1938), критерий Пагуровой (Пагурова, 1963) и Стьюдента на рангах. |
|
|
|
|
|
|
17.06.2022 - 13:17
Сообщение
#21
|
||
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Цитата(nokh @ 17.06.2022 - 07:34) Можно поиграться и бутстрепом, тогда не будет противоречия ни в ДИ для средних, ни в ДИ для разности: 274,0 [221,6; 305,2] и 402,0 [371,3; 437,2] для процентильного метода, ДИ не перекрываются Разность 128,0 [75,6; 177,8] Всё можно посчитать в PAST https://www.nhm.uio.no/english/research/resources/past/ О, новый ПАСТ пермутит по-новому! У меня так: При том, ни то, ни другое p, я "вручную" повторить не смог. Кстати я так и не понял, в какое ему место заглянуть, чтобы узнать версию своего. Чем Паст хорош - скорость. На своем древнем компе я так и не дождался 999999 псевдовыборок на чистом R, в ПАСТе же оно почти мгновенно происходит. Чем он плох - х. з., что именно считает. Например, методом научного тыка было доказано, что бутсреп-ДИ для разности средних ПАСТ считает вовсе не методом процентилей, как Вы заявляете, а методом basic - наименее ненадежным из существующих.
Эскизы прикрепленных изображений
|
|
|
|
|
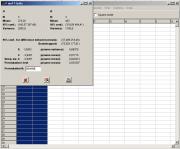
|
|
|
17.06.2022 - 13:26
Сообщение
#22
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(ИНО @ 17.06.2022 - 13:17) ...а методом basic - наименее ненадежным из существующих. А что такое метод basic? |
|
|
|
|
|
|
17.06.2022 - 17:12
Сообщение
#23
|
|
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Хороший вопрос! Документация пакета boot (сверяя с которым, я и пришел к вышеозначенному заключению относительно типа ДИ в PAST) лаконично отвечает на него следующее: "The formulae on which the calculations are based can be found in Chapter 5 of Davison and Hinkley (1997)."
Ну и библиографическая ссылка в конце: Davison, A.C. and Hinkley, D.V. (1997) Bootstrap Methods and Their Application, Chapter 5.Cambridge University Press. У меня такой книжки нету. Но попадались статьи, в которых некий "basic bootstrap CI" нещадно поносили и хвалили BCa. Особо не вникал (учитывая, что, повторяю, саму глубинную идею бутстрепа так и не смог постичь), просто пользовал по возможности BCa. Скажем так, впал в грех слепого следования авторитетам  Немного помоделировал (осбо в это дело не умею, так что, если что не так, тапками не кидайте) Загрузка "бигдаты" ТС (пожалуй, стоит уже в рабочем пространстве сохранить - как ни крути, классический датасет получился, ирисы Фишера отдыхают) :Код x<-c(221.60112, 305.217725, 295.251684) y<-c(371.3313, 397.452722, 437.212724) Генерация 10000 пар выборок из нормальных распределений с похожими параметрами, построение 95% ДИ методом Уэлча и проверка, попадает ли в них истинная разница матожиданий: Код diff<-274-402 res<-rep(0, 10000) for (i in 1:10000) { x_sim<-rnorm(3, mean(x), sd(x)) y_sim<-rnorm(3, mean(y), sd(y)) ci<- t.test(x_sim, y_sim)$conf.int if(diff>ci[1]&diff<ci[2]) res[i]<-1 } #Доля попаданий: sum(res)/10000 Вывод: истинный доверительный уровень на смоделированных данных получился чуть выше номинального, но разница не существенна Теперь возьмем выборки, каждую из смеси двух нормальных распределений с одинаковыми мю но разными сигмами. Страшненькая формула генератора получена методом тыка, так чтобы стандартные отклонения все еще оставались похожими на оригинал. Если умеете генерировать смеси с заданной дисперсией, замените на свою элегантную:) Код diff<-274-402 res<-rep(0, 10000) for (i in 1:10000) { x_sim<-c(rnorm(2, mean(x), sd(x)*1/3), rnorm(1, mean(x), sd(x)*2/3*2.5)) y_sim<-c(rnorm(2, mean(y), sd(y)*1/3), rnorm(1, mean(y), sd(y)*2/3*2.5)) ci<- t.test(x_sim, y_sim)$conf.int if(diff>ci[1]&diff<ci[2]) res[i]<-1 } sum(res)/10000 А здесь уже не все так хорошо: метод Уэлча дает примерно 99% интервал вместо желаемого 95%. И туда уже обычно ноль таки попадает! Справится ли BCa лучше? Код library(confintr) diff<-274-402 res<-rep(0, 1000) for (i in 1:1000) { x_sim<-c(rnorm(2, mean(x), sd(x)*1/3), rnorm(1, mean(x), sd(x)*2/3*2.5)) y_sim<-c(rnorm(2, mean(y), sd(y)*1/3), rnorm(1, mean(y), sd(y)*2/3*2.5)) ci<- ci_mean_diff(x_sim, y_sim, type="boot", boot_type="bca")$interval if(diff>ci[1]&diff<ci[2]) res[i]<-1 } sum(res)/1000 Если дождетесь выдачи, сообщите мне. Я не смог, несмотря на то, что урезал количество симуляций до 1000. Можно, конечно, еще и количество псевдовыборок на каждом шаге урезать (параметр R в ci_mean_diff()), но тогда уж совсем как-то неубедительно получится. Философский вопрос: существует ли в мире более медленный язык программирования чем R? P.S. Таки нашел в Шитиков,Розенберг "Рандомизация и бутстреп:статистический анализ в биологии и экологиис использованием R", что что за бэйзик-интевал такой: это тот же процентильный, но перевернутый относительно среднего. Теоретические основы данной процедуры не понял. Но ,в третий раз повторяю: я и основы бутсрепа вообще плохо понимаю. Но судя по тому, как извращаются с этими интервалами, начиная от переворота в случае бэйзика этого, заканчивая расчетом неких параметров смещения и акселерации в случае BCa, с "восстановлением распределения путем замены одних вариант другими" на самом деле все совсем не так просто, как это иногда преподносят. И интуиция тут работает неважно (моя, по крайней мере). Сообщение отредактировал ИНО - 17.06.2022 - 18:01 |
|
|
|
|
|
|
18.06.2022 - 01:12
Сообщение
#24
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(ИНО @ 17.06.2022 - 17:12) Вывод: истинный доверительный уровень на смоделированных данных получился чуть выше номинального, но разница не существенна При параметре ф-ции t.test(..., var.equal=TRUE) оценка доверительной вероятности составляет 94,88%, при var.equal=FALSE, да, зашкаливает за 96%. Цитата Справится ли BCa лучше?Если дождетесь выдачи, сообщите мне Эт можно. С параметром R=999 в ci_mean_diff() при общем числе повторностей=1000 мой комп ковырялся 3,5 мин. Разумеется, при параметре по умолчанию R=9999 ковырялся бы на порядок дольше. Я бы тоже не дождался. Мой результат LOW______ UP _____ L________ PROB -147.78218 -114.44736 33.33482 0.77600 где L- длина полученного интервала (она загуливает совершенно диким образом), PROB=sum(res)/1000 - оценка доверительной вероятности. Она находится в диапазоне ,765 - ,778. Не хочется превращать мероприятие в форум для программистов, однако для исходных выборок x и y эмпирическая корреляция равна cor(x,y)=.73041, что, конечно, надо учитывать при моделировании системы случайных величин. Конструкция Код x_sim<-rnorm(3, mean(x), sd(x)) y_sim<-rnorm(3, mean(y), sd(y)) смотрится просто неприлично. Сообщение отредактировал 100$ - 18.06.2022 - 01:30 |
|
|
|
|
|
|
18.06.2022 - 01:54
Сообщение
#25
|
|
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Ну что поделать, я не умею толком ни программировать, ни моделировать. Единственное до чего догадался, это если бы мю и сигму один раз затать перед циклом, это б сэкономило несколько секунд. Но то не важно. Львиную долю времени отнимает сi_mean_diff(). Надо поискать, нет ли какого пакета, где бы основную работу по построению бутстреповских ДИ делал бы код си.
У Вас хороший комп. На своем я не дождался и при R=999, покушать успел, вернулся - а воз и ныне там. Но мой комп он очень древний. Однако 999 итераций бутстрепа очень мало для надежной оценки - второй знак после запятой будет играть, если не первый. Так что надо еще пару раз прогнать, чтобы проверить, не превратится ли 0,78 в 0,98. Но ежели нет, то, значит, в данном случае BCa выдает слишком узкий ДИ, а Уэлч (без бутстрепа) - слишком широкий. Причем 0 то входит, то не входит. Если хотите, можете попробовать задать boot_type поочередно "perc", "basic" и "norm" и выбрать, где охват будет ближе к номинальному для данного примера. Насчет корреляции даже мысли не возникло. По условиям задачи это ж типа две случайные независимые выборки, откуда там ей взяться? Может, случайно вышло просто? Или же ТС (а куда он делся?) что-то не договаривает. |
|
|
|
|
|
|
18.06.2022 - 17:49
Сообщение
#26
|
|
|
Группа: Пользователи Сообщений: 95 Регистрация: 27.12.2015 Пользователь №: 27815 |
Добрый день.
Предлагаю рассмотреть на жизнеспособность подход из серии "продуктивных методов анализа". Так как данные количественные, минимальное значение концентрации белка 0, а в качестве максимального возьмём самое больше значение из данных обсуждаемого эксперимента. После трансформации данных к диапазону (0, 1), можно выполнить сравнение двух групп через бета-регрессию. CODE ## Создадим данные a <- c(221.60112, 305.217725, 295.251684) b <- c(371.3313, 397.452722, 437.212724) ab <- c(a, b) n <- length(ab) g <- rep(c('a', 'b'), time = c(length(a), length(b))) ## Трансформация к диапазону (0; 1) vec <- scales::rescale_max(ab, from = c( 1/max(ab)/n, max(ab)+max(ab)/n ) ) ## Бета-регрессия fit <- betareg::betareg(vec~g) emm <- emmeans::emmeans(fit, ~g) ## Средние и ДИ для групп res <- data.frame(emm, row.names = 'g')[c('emmean', 'asymp.LCL', 'asymp.UCL')] cev <- apply(res, 2, function(x) scales::rescale_max(x, to = c( 1/max(ab)/n, max(ab)+max(ab)/n ), from = c(0, 1))) ## Разница средних и ДИ ctr <- data.frame(confint(pairs(emm)))[c('estimate', 'asymp.LCL', 'asymp.UCL')] rtc <- apply(ctr, 2, function(x) scales::rescale_max(x, to = c( 1/max(ab)/n, max(ab)+max(ab)/n ), from = c(0, 1))) ## Расчёт средних в группах set.seed(32167) mean.a <- Hmisc::smean.cl.boot(a, B = 9999) mean.b <- Hmisc::smean.cl.boot(b, B = 9999) means <- rbind(cev, mean.a, mean.b) colnames(means) <- c('mu', 'lwr', 'upr') ## Расчёт разницы средних и ДИ set.seed(32167) ci.bca <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'bca') ci.per <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'perc') ci.nor <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'norm') ci.bas <- confintr::ci_mean_diff(a, b, type = 'bootstrap', boot_type = 'basic') fun_extr <- function(x) { #Для единообразного извлечения estimate <- x[['estimate']] interval <- x[['interval']] result <- c(estimate, interval) return(result) } diffs <- rbind( beta = rtc, bca = fun_extr(ci.bca), perc = fun_extr(ci.per), norm = fun_extr(ci.nor), basic = fun_extr(ci.bas) ) colnames(diffs) <- c('mu', 'lwr', 'upr') ## Выводим результат summary(fit) print(means, digits = 5) print(diffs, digits = 5) > Call: betareg::betareg(formula = vec ~ g) Standardized weighted residuals 2: Min 1Q Median 3Q Max -1.7892 -1.0236 0.2118 0.9816 1.5627 Coefficients (mean model with logit link): Estimate Std. Error z value Pr(>|z|) (Intercept) 0.1480 0.1607 0.921 0.357 gb 1.1632 0.2525 4.606 4.1e-06 *** Phi coefficients (precision model with identity link): Estimate Std. Error z value Pr(>|z|) (phi) 50.91 29.16 1.746 0.0808 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Type of estimator: ML (maximum likelihood) Log-likelihood: 8.148 on 3 Df Pseudo R-squared: 0.7817 Number of iterations: 68 (BFGS) + 2 (Fisher scoring) > mu lwr upr a 273.88 233.94 313.82 b 401.80 369.21 434.40 mean.a 274.02 221.60 305.22 mean.b 402.00 371.33 437.21 > mu lwr upr beta -127.92 -179.45 -76.395 bca -127.98 -191.06 -86.850 perc -127.98 -180.40 -78.143 norm -127.98 -180.30 -74.747 basic -127.98 -177.81 -75.553 Судя по результатам, средние и доверительные интервалы, разница средних, которые получены через бета-модель, аналогичны таковым при вычислении через бутстреп. Теперь попробуем повторить анализ для смеси распределений бета-регрессией, разными вариантами бутстрепа. Форма вывода - как у 100$. CODE ##Дополнительные функции #fix fun_int <- function(x) { int <- x[['interval']] return(int) } fun_res <- function(data, diff) { len <- length(data) res <- vapply(X = 1:n, FUN.VALUE = logical(1), function(i) { cond <- diff>data[[i]][1] & diff<data[[i]][2] return(cond) } ) pr <- sum(res)/len sums <- rowMeans(simplify2array(data)) res <- list(low = sums[1], up = sums[2], l = abs(sums[1]-sums[2]), prob = pr) return(res) } x <- c(221.60112, 305.217725, 295.251684) y <- c(371.3313, 397.452722, 437.212724) mu_x <- mean(x) mu_y <- mean(y) len_x <- length(x) sd_x <- sd(x) sd_y <- sd(y) len_y <- length(y) diff <- mu_x-mu_y len <- len_x+len_y g <- rep(c('x', 'y'), time = c(len_x, len_y)) idx <- c('asymp.LCL', 'asymp.UCL') n <- 1000 res <- vector(mode = 'logical', length = n) set.seed(32167) x_sim <- replicate(n, c( rnorm(round(len_x*2/3), mu_x, sd_x*1/3), rnorm(round(len_x*1/3), mu_x, sd_x*2/3*2.5) ) ) y_sim <- replicate(n, c( rnorm(round(len_x*2/3), mu_y, sd_y*1/3), rnorm(round(len_x*1/3), mu_y, sd_y*2/3*2.5) ) ) xy_sim <- rbind(x_sim, y_sim) vec_sim <- apply(xy_sim, 2, function(i) scales::rescale_max(i, from = c( 1/max(i)/len, max(i)+max(i)/len ) )) ci_beta <- lapply( X = 1:n, FUN = function(i) { fit <- betareg::betareg(vec_sim[,i]~g) ci <- as.numeric(confint(pairs(emmeans::emmeans(fit, ~g)))[idx]) ic <- scales::rescale_max(ci, to = c( 1/max(xy_sim[,i])/len, max(xy_sim[,i])+max(xy_sim[,i])/len ), from = c(0, 1) ) return(ic) }) ci_bca <- lapply( X = 1:n, FUN = function(i) { fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i], type = 'bootstrap', boot_type = 'bca', R = n) ci <- fun_int(fit) return(ci) }) ci_perc <- lapply( X = 1:n, FUN = function(i) { fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i], type = 'bootstrap', boot_type = 'perc', R = n) ci <- fun_int(fit) return(ci) }) ci_norm <- lapply( X = 1:n, FUN = function(i) { fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i], type = 'bootstrap', boot_type = 'norm', R = n) #fix ci <- fun_int(fit) return(ci) }) ci_basic <- lapply( X = 1:n, FUN = function(i) { fit <- confintr::ci_mean_diff(x_sim[,i], y_sim[,i], type = 'bootstrap', boot_type = 'basic', R = n) #fix ci <- fun_int(fit) return(ci) }) vct <- ls(pattern = 'ci_') res_ci <- t(simplify2array(lapply(1:length(vct), function(i) { #do.call(fun_res, list(data = get(vct[i]), diff = get('diff'))) fun_res(data = get(vct[i]), get('diff')) #fix }))) row.names(res_ci) <- vct print(res_ci, digits = 5) # fix low up l prob ci_basic -173.1 -81.769 91.328 0.885 ci_bca -176.03 -81.595 94.435 0.773 ci_beta -172.44 -79.885 92.552 0.866 ci_norm -174 -80.332 93.666 0.876 ci_perc -172.38 -81.104 91.271 0.814 Сообщение отредактировал comisora - 18.06.2022 - 21:58 |
|
|
|
|
|
|
18.06.2022 - 18:17
Сообщение
#27
|
|
|
Группа: Пользователи Сообщений: 204 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
ИМХО бета тут как бы совсем за уши притянута, ограничивать сверху эмпирическим максимумом нонсенс. Однако ж, погляди, работает лучше всех, по крайней мере, на этих синтетических данных.
Код крутой, увы, моя такого не понема. Но все ж бросилось глаза, что названия некоторых бутреповских ДИ и их типы перепутаны местами. |
|
|
|
|
|
|
18.06.2022 - 19:12
Сообщение
#28
|
|
|
Группа: Пользователи Сообщений: 95 Регистрация: 27.12.2015 Пользователь №: 27815 |
2ИНО
Ошибки исправил, результат тоже, спасибо. Поэтому и написал, что это из серии "продуктивных" методов. Предполагаю, что можно использовать другие максимум и минимумы (например, из данных литературы), zero-one-inflated (gamlss.dist::BEINF) и ещё что-нибудь экзотическое. В моём представлении это не сильно хуже допущения о нормальности распределения или использования уже предложенных подходов к анализу в ходе обсуждения. Несомненный плюс столь "достоверного" результата - возможность отчитаться за проделанную работу и обосновать необходимость дальнейшего финансирования, чтобы численность обеих выборок довести до 4  . .Касательно других обсуждаемых методов - в приложении статья про применимость теста Стьюдента, модификации Уэлча и ранговых преобразований. Может быть кого-то заинтересует. Сообщение отредактировал comisora - 18.06.2022 - 19:23
Прикрепленные файлы
 Using_the_Students_t_test_with_extremely_small_sample_sizes.pdf ( 333,44 килобайт )
Кол-во скачиваний: 163
Using_the_Students_t_test_with_extremely_small_sample_sizes.pdf ( 333,44 килобайт )
Кол-во скачиваний: 163 |
|
|
|
|
|
|
18.06.2022 - 21:26
Сообщение
#29
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
>comisora,
а вы можете откомментировать конструкцию do.call? Такого в листингах, по-моему, себе даже p2004r не позволял ) |
|
|
|
|
|
|
18.06.2022 - 23:53
Сообщение
#30
|
|
|
Группа: Пользователи Сообщений: 95 Регистрация: 27.12.2015 Пользователь №: 27815 |
2 100$
Конечно. Это я усложнил код, так как можно было легко вызвать функцию напрямую (отредактировал код, вставил функции, в т.ч. ту, которую вызывал через do.call). do.call применяет функцию однократно к списку, в котором находятся аргументы, что равносильно вызову функции. Функция lapply - это цикл, в ходе которого функция вызывается для каждого элемента списка, просто реализованный в компактом виде. Примеры: CODE ## Сумма do.call(sum, list(c(1, 2, 4, 1, 2), na.rm = TRUE)) #Правильно lapply(c(1, 2, 4, 1, 2), sum) #Неправильно ##Структура операций L <- list(c(1,2,3), c(4,5,6)) L [[1]] [1] 1 2 3 [[2]] [1] 4 5 6 lapply(L, sum) [[1]] [1] 6 [[2]] [1] 15 list( sum(L[[1]]) , sum(L[[2]])) [[1]] [1] 6 [[2]] [1] 15 do.call(sum, L) [1] 21 sum(L[[1]], L[[2]]) [1] 21 ##Передача аргументов в качестве листа args <- list(n = 10, mean = 50, sd = 10) #Т-баллы do.call(rnorm, args) #эквивалентно rnorm(args$n, args$mean, args$sd) replicate(10, rnorm(10)) #В каждом столбце числа разные do.call(replicate, list(10, rnorm(10))) #В каждом столбце числа одинаковые ##Вызов функции по её названию do.call('colnames', list(iris)) ##Комбинация списков rbind(L) #do.call(rbind, list(L)) Reduce('rbind',x = L) #do.call(rbind, L) Работа функции не самая очевидная, но в некоторых случаях её использование было очень кстати. |
|
|
|
|
|
|