Здравствуйте, гость ( Вход | Регистрация )

  |

 23.08.2014 - 08:53 23.08.2014 - 08:53
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Здравствуйте, уважаемые форумчане. Помогите "чайнику" от статистики. Есть результаты анкетирования родителей и учителей по симптоматике расстройства на 1730 детей возраста от 6-11 лет. Распределение признака в моей выборке законам нормального распределения не подчиняется, использую непараметрические критерии. По всем показателям статистически значимы гендерные различия и различия по возрасту. Ранжирую выборку по возрасту и полу, стандартизирую тесты, определяю тестовые нормы для своей выборки (критические перцентили и перцентильные кривые). В соответствии с полученными данными, исходя из значений соответствующих значений перцентилей, формирую "свою" группу детей с расстройством. И теперь в растерянности. Как мне между собой сравнивать полученные группы детей с заболеванием, если они были мной изначально ранжированы по возрасту и полу и для каждой возрастной группы отдельно мальчиков, отдельно девочек была определена своя норма? Извиняюсь, если совсем туплю.
|
 |
 
|


 |
|
|
23.08.2014 - 10:40
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(ТаКуст @ 23.08.2014 - 08:53)  Здравствуйте, уважаемые форумчане. Помогите "чайнику" от статистики. Есть результаты анкетирования родителей и учителей по симптоматике расстройства на 1730 детей возраста от 6-11 лет. Распределение признака в моей выборке законам нормального распределения не подчиняется, использую непараметрические критерии. По всем показателям статистически значимы гендерные различия и различия по возрасту. Ранжирую выборку по возрасту и полу, стандартизирую тесты, определяю тестовые нормы для своей выборки (критические перцентили и перцентильные кривые). В соответствии с полученными данными, исходя из значений соответствующих значений перцентилей, формирую "свою" группу детей с расстройством. И теперь в растерянности. Как мне между собой сравнивать полученные группы детей с заболеванием, если они были мной изначально ранжированы по возрасту и полу и для каждой возрастной группы отдельно мальчиков, отдельно девочек была определена своя норма? Извиняюсь, если совсем туплю. Ну такие "вкусные" данные не грех и в library(bnlearn) загрузить, что бы не порождать гипотез самому.  А вообще у Вас многомерные данные, наблюдение (да и вообще анкета), это означает необходимость применения методов эксплораторного анализа, а не аппарата проверок статгипотез. Если возможно просто выкладывайте таблицу данных в этот тред.  |
|
|
|
|
|
|
23.08.2014 - 11:17
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Столько непонятных слов в одном сообщении... "Чайники" они такие "чайники"... Вникаю в эксплораторный анализ. Спасибо за ответ
|
|
|
|
|
|
|
23.08.2014 - 11:25
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Цитата(p2004r @ 23.08.2014 - 10:40) Ну такие "вкусные" данные не грех и в library(bnlearn) загрузить, что бы не порождать гипотез самому. А вообще у Вас многомерные данные, наблюдение (да и вообще анкета), это означает необходимость применения методов эксплораторного анализа, а не аппарата проверок статгипотез. Если возможно просто выкладывайте таблицу данных в этот тред. в таблице данных пол: 1 - муж 2 - жен, и 3 возрастные группы. |
|
|
|
|
|
|
23.08.2014 - 11:35
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Таблица данных
Сообщение отредактировал ТаКуст - 23.08.2014 - 11:37
Прикрепленные файлы
|
|
|
|

|
|
|
23.08.2014 - 20:20
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(ТаКуст @ 23.08.2014 - 11:35) Таблица данных Первично в анкете было только (кроме пола и возраста) "Балл А(р)", "Балл А(уч)", "Балл Б(р)", "БаллБ(уч)" ? Как эти шкалы выставлялись заполнявшими, или это уже результат обработки вопросов анкеты? |
|
|
|
|
|
|
23.08.2014 - 20:55
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Цитата(p2004r @ 23.08.2014 - 20:20) Первично в анкете было только (кроме пола и возраста) "Балл А(р)", "Балл А(уч)", "Балл Б(р)", "БаллБ(уч)" ? Как эти шкалы выставлялись заполнявшими, или это уже результат обработки вопросов анкеты? Это результаты суммирования баллов ответов по субшкалам. Шкала включала 18 пунктов, соответствующих основным симптомокомплексам расстройства. Выраженность каждого симптома оценивался по 4-балльной системе: 0 - никогда или редко; 1 - иногда; 2 - часто; 3 - очень часто. Результаты оценивались по субшкалам, а также по общему баллу, который представляет собой сумму баллов по выделенным субшкалам. (р) - родительская версия, (уч) - учительская версия |
|
|
|
|
|
|
23.08.2014 - 21:38
Сообщение
#8
|
|||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(ТаКуст @ 23.08.2014 - 20:55) Это результаты суммирования баллов ответов по субшкалам. Шкала включала 18 пунктов, соответствующих основным симптомокомплексам расстройства. Выраженность каждого симптома оценивался по 4-балльной системе: 0 - никогда или редко; 1 - иногда; 2 - часто; 3 - очень часто. Результаты оценивались по субшкалам, а также по общему баллу, который представляет собой сумму баллов по выделенным субшкалам. (р) - родительская версия, (уч) - учительская версия Лучше конечно пройтись непосредственно по субшкалам, поскольку явно есть латентные факторы которые нагружают сразу несколько субшкал. Но вот если попытаться разобраться с агрегированными данными без выдвижения гипотез, так сказать в чистом виде unsupervised. За базовый метод (поскольку точек много и заполнили они пространство состояний такого небольшого числа переменных достаточно полно, и у нас две переменных качественные) применим ввиду простоты и эффективности unsupervised random forest. Результат визуализируем методом многомерного шкалирования. Код # читаем данные конверитрованные в текстовый вид с разделителем ";" data<-read.csv2("data.csv") # загружаем библиотеку с классической реализацией random forest library(randomForest) # берем только "первичные" данные и объявляем измеренными в номинальной шкале пол и возрастные группы data.rf<-data.frame(data[,c(4:5, 7:8)], pol=factor(data[,2]), vozrast=factor(data[,3])) # подгоняем модель rf.unsupervised<-randomForest(data.rf, do.trace=T, ntree=2000) # визуализируем с помощью многомерного шкалирования матрицу расстояний с раскраской по полу MDSplot(rf.unsupervised, data[,2], k=4) # с раскраской по возрастным группам MDSplot(rf.unsupervised, data[,3], k=4) 1) То что подковой изображено на первых двух компонентах, это основное измеряемое качество (его по другому просто "уложить" на плоскость не удается , мешает дисперсия).2) После исключения основной зависимости из данных, в пространстве оставшихся шкал, все "естественные группировки" очевидно видны на графиках. Например по полу есть расщепление --- в области ?больших? баллов оба пола не отличаются, в области малых значений у них существенные различия. Наверное "патология" наступает в момент исчезновения гендерных различий. Можно в принципе уровень "отсечения" вывести. Возраста некоторые явно тяготеют друг к другу. PS Давайте первичные шкалы, компьютеру всё равно сколько переменных в датасете
Эскизы прикрепленных изображений
|
||
|
|
|


|
|
|
23.08.2014 - 22:14
Сообщение
#9
|
|
|
Группа: Пользователи Сообщений: 6 Регистрация: 23.08.2014 Пользователь №: 26611 |
Читая Ваш ответ, чувствую себя дикарем, впервые увидевшим телевизор... У меня нет данных по первичным шкалам, вернее есть, но в виде собственно 1731+1731 анкеты. По данным литературы используется при оценке этих тестов именно суммарный балл, вот я и не заморачиваясь, вносила сразу суммы в таблицу. Спасибо за ответ, попытаюсь разобраться.
|
|
|
|
|
|
|
24.08.2014 - 10:21
Сообщение
#10
|
|||||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
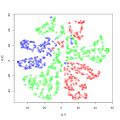
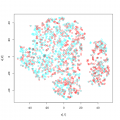
Цитата(ТаКуст @ 23.08.2014 - 22:14) Читая Ваш ответ, чувствую себя дикарем, впервые увидевшим телевизор... У меня нет данных по первичным шкалам, вернее есть, но в виде собственно 1731+1731 анкеты. По данным литературы используется при оценке этих тестов именно суммарный балл, вот я и не заморачиваясь, вносила сразу суммы в таблицу. Спасибо за ответ, попытаюсь разобраться. usup. random forest пытается восстановить обозримую проекцию "глобальной конфигурации" дисперсии в экспериментальных данных, но есть методы которые смотрят только на "локальную окрестность" каждой точки. Например tsna (вот пример использования http://mayer.pro/t-SNE-Samsung ) Можно, хотя это менее интересно поместить в tsna данные random forest из предыдущего поста Код # функция которая отрисовывает промежуточные итерации "упаковки" данных ecb <- function(x,y){ plot(x, col=rainbow(3)[factor(data[,3])]) } # собственно вызов метода для расстояний вычисленных random forest tsne_data_2 <- tsne(1 - rf.unsupervised$proximity, epoch_callback = ecb, perplexity=50) Раскрасив картину "упаковки" расстояний первый раз по полу, а второй по "возрастной группе" мы видим, 1) что в группах по возрасту есть половая диференциация 2) что все группы сливаются вместе в нечто не дифференцируемое (в центр диаграммы). Попробуем посмотреть на первичные данные без информации о поле и возрастной группе. Сразу скажу что пол и возрастная группа никак не коррелировала с наблюдаемыми "естественными группировками". (третья диаграмма) Дважды запустив tsna и отобразив данные с помощью pairs() мы получаем картину наличия устойчивых "локальных" естественных группировок. Код pairs(cbind(tsne_data_1, tsne_data), col=rainbow(5)[kmeans(cbind(tsne_data_1, tsne_data), 5)$cluster]) Четко выделяется минимум одна из групп (файл с кодами групп присоединяю в формате csv, порядок тот же что и в Вашем) Сообщение отредактировал p2004r - 24.08.2014 - 17:32
Эскизы прикрепленных изображений
Прикрепленные файлы
|
||||
|
|
|


|
|
|