Здравствуйте, гость ( Вход | Регистрация )

  |

 26.10.2017 - 11:46 26.10.2017 - 11:46
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Подскажите, пожалуйста, как правильно написать о разнице в приросте побегов если вначале они были 82,4 +- 3,34 см, а после воздействия определенным фактором стали 91,4 +- 4,14 см. Других данных нет. Просто сказать, что длина побегов увеличилась на 9 см (91,4-82,4)? Или нужно еще сложить ошибки и разделить на два и привести эту ошибку? Или как?
|
 |
 
|


 |
|
|
26.10.2017 - 16:54
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Света K @ 26.10.2017 - 13:46)  Подскажите, пожалуйста, как правильно написать о разнице в приросте побегов если вначале они были 82,4 +- 3,34 см, а после воздействия определенным фактором стали 91,4 +- 4,14 см. Других данных нет. Просто сказать, что длина побегов увеличилась на 9 см (91,4-82,4)? Или нужно еще сложить ошибки и разделить на два и привести эту ошибку? Или как? 1. Прирост побегов, как и другие показатели, зависящие от времени, имеет асимметричное распределение. Следовательно, все эти плюс-минус не имеют ничего общего с реальностью: чисто виртуальные показатели. В приличные журналы данные вида "среднее +/- станд. ошибка" не принимают. Уровень проведённой статобработки - низкий, образца максимум 1980-х годов. 2. Если научный руководитель - динозавр, и требует именно древних методов, то рассчитать такую же виртуальную ошибку разности средних можно. Но только, конечно, не усреднением, а по специальной формуле. Для этого понадобятся значения дисперсий s2 в обеих выборках. Их можете рассчитать из значений стандартной ошибки и объёма выборок (формулу найдёте в любом учебнике). Стандартная ошибка разности будет равна se (разности средних)=Корень (s21/n1 + s22/n2) Погуглите на предмет стандартной ошибки разности, чтобы найти что-то для ссылки. 3. Но правильнее рассчитать доверительные интервалы (ДИ) и привести 1) средние с 95% ДИ и 2) разность средних с 95% ДИ. ДИ лучше считать бутстрепом ввиду отличия распределения от нормального. Если есть 2 колонки исходных данных, то в пакете PAST делается за 2-3 клика. Кстати, что значит "Других данных нет", куда делись оригинальные данные? Если у вас нет исходных данных, значит у вас нет данных, т.к. приведённые числа - это не данные, а результат не вполне корректной обработки данных. Сообщение отредактировал nokh - 26.10.2017 - 17:10 |
|
|
|

|
|
|
27.10.2017 - 16:16
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(nokh @ 26.10.2017 - 16:54) нет исходных данных Во-первых спасибо за разъяснения. Во-вторых, данные (исходные) конечно есть, но мне не совсем понятно - есть только две конечные цифры - начальная длина (среднее из 4 измерений) и после действия фактора. Имеется в виду, что никаких промежуточных данных нет. Стоит ли тут при таких данных вообще говорить о каком-то изменении размеров? Кстати, Вы правы, используются методы именно 80-х годов. Но многие считают, что вряд ли подобные методы могут измениться. Сообщение отредактировал Света K - 27.10.2017 - 16:22 |
|
|
|
|
|
|
27.10.2017 - 19:08
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Света K @ 27.10.2017 - 18:16) Во-первых спасибо за разъяснения. Во-вторых, данные (исходные) конечно есть, но мне не совсем понятно - есть только две конечные цифры - начальная длина (среднее из 4 измерений) и после действия фактора. Имеется в виду, что никаких промежуточных данных нет. Стоит ли тут при таких данных вообще говорить о каком-то изменении размеров? Кстати, Вы правы, используются методы именно 80-х годов. Но многие считают, что вряд ли подобные методы могут измениться. Раз у вас есть исходные данные, значит цифр у вас не 2 (начальная и конечная средние), а больше. Вот с этими самыми исходными цифрами (индивидуальными промерами) и нужно работать чтобы рассчитать 95% ДИ прироста и статистическую значимость влияния фактора (ваши динозавры назовут её "достоверностью"), раз был ещё какой-то фактор. Кстати этот фактор всё запутал, опишите свой материал и эксперимент и тогда решим как его грамотно обсчитать и представить (ну это если такое нужно, если не нужно - см. формулу стандартной ошибки разности в предыдущем сообщении). PS. А методы и подходы устаревают. Хи-квадрат Пирсона устарел, точный метод Фишера устарел, классический t-критерий Стьюдента тоже не рекомендуют использовать на практике, точные ДИ Клоппера-Пирсона не точны, двумерного нормального распределения (для корреляции Пирсона) в природе не сыскать и т.д. Многие известные методы получаются в качестве частных решений современных статистических моделей... Посмотрите насколько сильно компьютеры изменили мир с 1980-х: наивно думать что в научной методологии и статистике они ничего не изменили (это я про бутстреп и т.п.). Подходы устаревают морально, т.е. не потому, что были неправильные, а потому что взамен было предложено что-то лучше. Сообщение отредактировал nokh - 27.10.2017 - 19:23 |
|
|
|
|
|
|
31.10.2017 - 10:17
Сообщение
#5
|
|
 Группа: Пользователи Сообщений: 105 Регистрация: 23.11.2016 Пользователь №: 28953 |
Цитата(nokh @ 27.10.2017 - 19:08) Раз у вас есть исходные данные, значит цифр у вас не 2 (начальная и конечная средние), а больше. Вот с этими самыми исходными цифрами (индивидуальными промерами) и нужно работать чтобы рассчитать 95% ДИ прироста и статистическую значимость влияния фактора (ваши динозавры назовут её "достоверностью"), раз был ещё какой-то фактор. Кстати этот фактор всё запутал, опишите свой материал и эксперимент и тогда решим как его грамотно обсчитать и представить (ну это если такое нужно, если не нужно - см. формулу стандартной ошибки разности в предыдущем сообщении). PS. А методы и подходы устаревают. Хи-квадрат Пирсона устарел, точный метод Фишера устарел, классический t-критерий Стьюдента тоже не рекомендуют использовать на практике, точные ДИ Клоппера-Пирсона не точны, двумерного нормального распределения (для корреляции Пирсона) в природе не сыскать и т.д. Многие известные методы получаются в качестве частных решений современных статистических моделей... Посмотрите насколько сильно компьютеры изменили мир с 1980-х: наивно думать что в научной методологии и статистике они ничего не изменили (это я про бутстреп и т.п.). Подходы устаревают морально, т.е. не потому, что были неправильные, а потому что взамен было предложено что-то лучше. Полностью поддерживаю мнение nokh. Действительно, большинство участников форума, задающих свои вопросы и просьбы о помощи по статистике, не описывают достаточно подробно свои базы данных, и цели своих исследований. И часто эти вопросы по достаточно элементарным основным понятиям статистики. Это, естественно, признак недостаточных знаний по статистике. Что вполне нормально, т.к. медиков практически не обучают статистическому анализу. Поскольку для практикующих врачей эти методы не нужны. А нужны они лишь медикам-исследователям, учёным. Поэтому им нужно на форуме не только описывать свои вопросы, но и вкладывать базы данных в приложения. А ещё желательно кроме вопроса вписывать и свой ник в Скайпе. Поскольку специалистам по статистике гораздо проще и продуктивнее просто обговорить с ними их проблемы и оказать им реальную помощь. Считаю, что уровень формулируемых вопросов и просьб отражает не только уровень знаний этих форумчан, но и важность и актуальность для них желаемых результатов анализа. Поэтому для лучшего понимания возможностей и актуальности упоминаемого анализа своих баз данных, им нужно читать книги по статистике и применению разных методов анализа. Для этого рекомендую авторам вопросов активно пользоваться сайтами, с которых можно очень много скачивать книг по статистике. В частности, рекомендую следующие адреса: http://mirknig.su/ http://www.twirpx.com/ http://www.free-book.info/knigi.php?biblioteka=20 https://www.razym.ru/naukaobraz/matem/ http://maintracker.org/forum/viewforum.php?f=2028 http://sernam.ru/ http://bookfi.net/ http://www.newlibrary.ru/genre/nauka/matem...a_verojatnosti/ http://www.read.in.ua/cat/r13/ http://bukvy.net/books/nauka_ucheba/ http://www.alleng.ru/edu/math9.htm http://mexalib.com/?id=20 https://book-fb2.ru/education/ http://avorut.ucoz.ru/load/teorija_verojat...a_statistika/35 http://litvik.ru/2/13/uchebniki_manuals/42...mozhet-byt.html http://eek.diary.ru/p47642323.htm http://www.ph4s.ru/books_mat.html http://lib.chistopol.ru/?sub_id=32 http://www.koob.ru/search/?q=%D1%81%D1%82%...p;cof=FORID%3A9 http://eqworld.ipmnet.ru/ru/library/mathem...probability.htm http://www.math.ru/lib/ http://www.aup.ru/books/i016.htm http://www.zipsites.ru/ http://allreferats.narod.ru/mat.htm http://scintific.narod.ru/literature.htm http://sci-lib.com/full.php http://www.plib.ru/library/subcategory/127.html http://ilib.mccme.ru/ http://www.molbiol.ru/ http://www.booksmed.com/ Желаю успеха в научных исследованиях! |
|
|
|
|
|
|
3.11.2017 - 15:40
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(nokh @ 27.10.2017 - 20:08) опишите свой материал и эксперимент и тогда решим После воздействия неким фактором (А) измерили длину 4 побегов в опыте и контроле. Без действия: 75,2 78,3 88,9 87,0 После: 80,1 90,5 95,9 99,2 Как правильно написать (и вначале посчитать), что их длина увеличилась? Судя по Вашему пункту 2, наверное, так: действие "А" эффективно, в результате длина увеличилась на 9 +- 5,3 см. (корень(44/4+69/4)=5,3) А как по пункту 3? (В наличии только Excel 2003-2007 и калькулятор). Разные PAST недоступны, да и где их брать? Цитата(nokh @ 27.10.2017 - 20:08) Хи-квадрат Пирсона устарел А как же сравнивать принадлежность или нет наблюдаемой выборки некоторому теоретическому рапределению? Цитата(leo_biostat @ 31.10.2017 - 11:17) естественно, признак недостаточных знаний по статистике. Что вполне нормально Вы правы, но так и будет, поскольку обычным людям (т.е. не-статистикам) чаще всего некогда разбираться в деталях стат-анализа, им нужны четкие конкретные алгоритмы, причем с примерами решений и с примерами выводов, а очень часто на конкретные вопросы в лучшем случае дают какие-то ссылки, а в худшем - просто рекомендуют "погуглить". Если хотите изменения ситуации - организовывайте создание _практической_ базы знаний "вопрос-ответ" - с примерами, пояснениями и выводами. Я, конечно, кое-что почитаю из Ваших ссылок (если среди них есть ссылки на конкретные алгоритмы, а не вообще), спасибо, но... См. выше. Сообщение отредактировал Света K - 3.11.2017 - 15:49 |
|
|
|
|
|
|
4.11.2017 - 00:47
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(Света K @ 3.11.2017 - 15:40) Как правильно написать (и вначале посчитать), что их длина увеличилась? Судя по Вашему пункту 2, наверное, так: действие "А" эффективно, в результате длина увеличилась на 9 +- 5,3 см. (корень(44/4+69/4)=5,3) А как по пункту 3? (В наличии только Excel 2003-2007 и калькулятор). Разные PAST недоступны, да и где их брать? Тут все до смешного просто: для получения доверительных интервалов (н-р, 95%-ных) надо стандартную ошибку разности средних умножить либо на соответствующую квантиль распределения Стьюдента (в параметрическом варианте решения задачи), либо на соответствующую квантиль стандартного нормального распределения ( в непараметрической постановке). 95%-ная квантиль для стандартного нормального распределения равна =НОРМСТОБР(,975)=1,959964. Окончательно получим: 9+-1,96*5,3, т.е. 95%-ный ДИ разности средних = [-1.3828;19.5328]. Поскольку ДИ включает 0, делаем вывод, что данная разница средних статистически незначима. Имеющийся объем выборок просто не позволяет ее уловить. Вот и весь алгоритм. Как грится, спасибо за внимание. |
|
|
|
|
|
|
4.11.2017 - 13:10
Сообщение
#8
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 3.11.2017 - 15:40) После воздействия неким фактором (А) измерили длину 4 побегов в опыте и контроле. Без действия: 75,2 78,3 88,9 87,0 После: 80,1 90,5 95,9 99,2 Как правильно написать (и вначале посчитать), что их длина увеличилась? Судя по Вашему пункту 2, наверное, так: действие "А" эффективно, в результате длина увеличилась на 9 +- 5,3 см. (корень(44/4+69/4)=5,3) А как по пункту 3? (В наличии только Excel 2003-2007 и калькулятор). Разные PAST недоступны, да и где их брать? А как же сравнивать принадлежность или нет наблюдаемой выборки некоторому теоретическому рапределению? Вы правы, но так и будет, поскольку обычным людям (т.е. не-статистикам) чаще всего некогда разбираться в деталях стат-анализа, им нужны четкие конкретные алгоритмы, причем с примерами решений и с примерами выводов, а очень часто на конкретные вопросы в лучшем случае дают какие-то ссылки, а в худшем - просто рекомендуют "погуглить". Если хотите изменения ситуации - организовывайте создание _практической_ базы знаний "вопрос-ответ" - с примерами, пояснениями и выводами. Я, конечно, кое-что почитаю из Ваших ссылок (если среди них есть ссылки на конкретные алгоритмы, а не вообще), спасибо, но... См. выше. Расчет очень прост Код > df.data V1 V2 1 75.2 a 2 78.3 a 3 88.9 a 4 87.0 a 5 80.1 b 6 90.5 b 7 95.9 b 8 99.2 b > quantile(replicate(10000, {x <- sample(df.data$V1, replace=T); mean(x[1:4])-mean(x[4:8])}), probs=c(0.025,0.975)) 2.5% 97.5% -9.210125 9.405000 > quantile(replicate(10000, {x <- sample(df.data$V1, replace=T); mean(x[1:4])-mean(x[4:8])}), probs=c(0.05,0.95)) 5% 95% -7.68500 7.79025 > mean(df.data$V1[df.data$V2=="a"])-mean(df.data$V1[df.data$V2=="b"]) [1] -9.075 Разница средних групп не выходит за пределы доверительного интервала для этой разницы посчитанного рандомизацией при уровне когда мы считаем за достоверное событие имеющее вероятность ошибки принятия решения первого рода 5%.. Если выберем достаточным уверенность 9 случаев из 10, то можете считать доказанным влияние. (правда неплохо было бы посмотреть и уровень ошибок второго рода). PS Ученый это не "обычный человек- не статистик", не знать для него математику в объеме необходимом для доказательства гипотез которые он выдвигает о своих данных, равносильно признанию в неумении читать и писать... Ну а что пусть писцы пишут, а заодно и правильные слова с понятиями придумывают.  |
|
|
|
|
|
|
4.11.2017 - 18:03
Сообщение
#9
|
|||
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
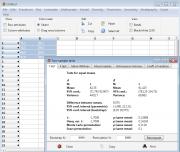
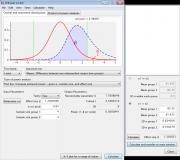
Цитата(Света K @ 3.11.2017 - 17:40) После воздействия неким фактором (А) измерили длину 4 побегов в опыте и контроле. Без действия: 75,2 78,3 88,9 87,0 После: 80,1 90,5 95,9 99,2 Как правильно написать (и вначале посчитать), что их длина увеличилась? Судя по Вашему пункту 2, наверное, так: действие "А" эффективно, в результате длина увеличилась на 9 +- 5,3 см. (корень(44/4+69/4)=5,3) А как по пункту 3? (В наличии только Excel 2003-2007 и калькулятор). Разные PAST недоступны, да и где их брать? 1. Скачать PAST и G*Power https://folk.uio.no/ohammer/past/ http://www.gpower.hhu.de/en.html 2. В PAST набить данные, выделить. Путь: Univariate - Summary statistics. Выписать: средние, станд. отклонения. Для средних (см. строку Mean) получить 95% ДИ бутстрепом (лучше BCa). 3. Univariate - Two-sample tests (F, t, ?). См. 95% ДИ разности. Параметрический по t-распределению содержит ноль и близок к тому, что 100$ рассчитал вам вручную по z-распределению. ДИ бутстрепом не содержит ноля, т.е. в таком варианте различия статистически значимы на 5%-ном уровне (P<0,05). Что тут за бутстреп, какие они бывают и чем отличаются в худшую сторону от процентильного, рассчитанного вам p2004r - см. в мануале и литературе. 4. В G*Power вносим средние и стандартные отклонения. Считаем мощность (power) исследования = 0,3. Ставим себе и научному руководителю двойку за планирование исследования. Относимся к результатам как результатам пилотного исследования и рассчитываем в G*Power необходимые объёмы выборок (Type...: Sample size calculation...) для альфа=0,05 и бета=0,20, т.е. мощности = 0,8 (самостоятельно). PS По поводу "обычных людей". Обычные люди работают на заводах, в офисах, магазинах и т.п. Они не измеряют длину побегов и не тусуются на статистических форумах. Процитирую сам себя (пособие скоро должно выйти): "Я - биолог (я – врач), а не статистик". Такая не всегда верная установка тиражируется в некоторых медицинских, педагогических и даже научных коллективах, а потому встречается не так уж редко. Она справедлива до тех пор, пока человек не приступает к выполнению научной квалификационной работы. Статистический анализ данных является неотъемлемой частью современной научной методологии. Поэтому, если человек работает над школьным научным проектом, дипломной работой бакалавра, магистерской, кандидатской или докторской диссертацией, он должен предъявить соответствующие данному квалификационному уровню умения грамотно получать данные и выделять из них наиболее существенные закономерности с использованием статистических методов. Поэтому, пока Вы занимаетесь научной работой, Вы – статистик. Сообщение отредактировал nokh - 4.11.2017 - 18:30
Эскизы прикрепленных изображений
|
||
|
|
|
|
|
|
7.11.2017 - 15:23
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(100$ @ 4.11.2017 - 01:47) 95%-ная квантиль для стандартного нормального распределения равна =НОРМСТОБР(,975)= Расчет и выводы понятны, спасибо, не ясно только, что за число (,975)? Цитата(p2004r @ 4.11.2017 - 14:10) [code]> df.data V1 V2 Здесь ничего не понятно, кроме того, что это не Excel. Цитата(nokh @ 4.11.2017 - 19:03) 2. В PAST набить данные, выделить. Путь: Univariate - Summary statistics. Выписать: средние, станд. отклонения. Для средних (см. строку Mean) получить 95% ДИ бутстрепом (лучше BCa). Понятно, спасибо, хотя Путь PAST 2.17 и не совсем такой. Правильно так: Statistics - Univariate - галочка Bootstrap (N=9999). Действительно быстро и удобно. Цитата(nokh @ 4.11.2017 - 19:03) 3. Univariate - Two-sample tests (F, t, ?). См. 95% ДИ разности. ... ДИ бутстрепом не содержит ноля, т.е. в таком варианте различия статистически значимы Правильнее так: Statistics - F and T tests (two samples). А вот дальше - различия "статистически значимы" и все снова непонятно. Цитата(nokh @ 4.11.2017 - 19:03) 4. В G*Power вносим средние и стандартные отклонения. Считаем мощность (power) исследования = 0,3. Здесь даже непонятно куда и что вносить... Цитата(nokh @ 4.11.2017 - 19:03) выделять из них наиболее существенные закономерности с использованием статистических методов Ну да, ну да. В идеале. А в реальности - ни согласия по поводу самих методов, ни четких алгоритмов и примеров, ни доступных объяснений. Так, мельком, по ходу, как будто все изначально все знают. Особенно ценны "существенные закономерности" когда одни и те же данные можно интерпретировать и так, и в обратную сторону. Недаром еще Гексли сказал, что математика, статистика как жернова - любую засыпку смелет... Сообщение отредактировал Света K - 7.11.2017 - 15:24 |
|
|
|
|
|
|
7.11.2017 - 16:56
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 109 Регистрация: 27.12.2015 Пользователь №: 27815 |
2Света К
Цитата Расчет и выводы понятны, спасибо, не ясно только, что за число (,975)? Можно начать отседова. Цитата Здесь ничего не понятно, кроме того, что это не Excel. Чтобы понять, читать вот эту книжку. Она для широкого круга. Цитата Здесь даже непонятно куда и что вносить... Мануал к Gpower находится там же, где его можно скачать. Сообщение отредактировал comisora - 7.11.2017 - 16:57 |
|
|
|
|
|
|
7.11.2017 - 20:32
Сообщение
#12
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Света K @ 7.11.2017 - 17:23) Понятно, спасибо, хотя Путь PAST 2.17 и не совсем такой. Правильно так: Statistics - Univariate - галочка Bootstrap (N=9999). Действительно быстро и удобно. ... Ну да, ну да. В идеале. А в реальности - ни согласия по поводу самих методов, ни четких алгоритмов и примеров, ни доступных объяснений. Так, мельком, по ходу, как будто все изначально все знают. Особенно ценны "существенные закономерности" когда одни и те же данные можно интерпретировать и так, и в обратную сторону. Недаром еще Гексли сказал, что математика, статистика как жернова - любую засыпку смелет... У меня указан верный путь, т.е. все написано ПРАВИЛЬНО. А если вы умудрились скачать по моей ссылке древнюю версию вместо 3.16 - это ваши проблемы. У вас снижен порог самокритики: я бы трижды проверил почему люди пишут одно, а уменя получается иначе. Вас же это ни капельки не смутило - типа советуете тут мне неправильно. Плохое качество для науки в сочетании с нежеланием разбираться в деталях. Если не стремиться к идеалам, то ни человеку наука не нужна, ни человек науке. Впрочем как и в любом деле... |
|
|
|
|
|
|
8.11.2017 - 11:56
Сообщение
#13
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(comisora @ 7.11.2017 - 16:56) Мануал к Gpower находится там же Спасибо, есть такой. Цитата(nokh @ 4.11.2017 - 18:03) 4. В G*Power вносим средние и стандартные отклонения. Считаем мощность (power) исследования = 0,3. Данные ввести удалось, а как интерпретировать полученные графики и полученные результаты? Объясните, пожалуйста. Цитата(nokh @ 7.11.2017 - 20:32) ... это ваши проблемы Вот это и есть основная беда: я - прав, все остальные - нет (не о Вас конкретно). А то, что Вы не указали версию, а их на сайте несколько, Вас абсолютно не смутило. То, что у Вас просит помощи человек, к-рый вероятнее всего впервые слышит об этой программе - Вас тоже ни капельки не смутило. "Это ваши проблемы", правы только Вы. Плохое качество для науки в сочетании с нежеланием разбираться в деталях. |
|
|
|
|
|
|
8.11.2017 - 13:14
Сообщение
#14
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 8.11.2017 - 11:56) Спасибо, ... я еще разок вам всем в лицо плюну  Дальше "Света" не читайте. PS Зачем вы господа хорошие кормите очередного тролля? Это же очевидно что такие заявления надо тереть в момент их появления.... ну в крайнем случае давать ссылку на википедию. Тролль (обычно на нашем форуме это недоучившийся птушник программист подавшийся в датасаенс) всегда маскируется под "неосведомленного пользователя", который "чисто по глупости" делает "случайные" провокационные заявления. Часто действует из каких то конкурентных соображений. Цель в любом случае простая --- "нагадить в люфте"ТМ. Поверьте нет больше попаболиТМ для этого же.ребенка если его труды будут просто стерты со страниц форума.  . Это все варианты мотивов такой "беззащитной овечки" достойно обесценивает в 0. . Это все варианты мотивов такой "беззащитной овечки" достойно обесценивает в 0.
|
|
|
|
|
|
|
8.11.2017 - 18:16
Сообщение
#15
|
||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 4.11.2017 - 18:03) 1 PS По поводу "обычных людей". Обычные люди работают на заводах, в офисах, магазинах и т.п. Они не измеряют длину побегов и не тусуются на статистических форумах. Процитирую сам себя (пособие скоро должно выйти): "Я - биолог (я ? врач), а не статистик". Такая не всегда верная установка тиражируется в некоторых медицинских, педагогических и даже научных коллективах, а потому встречается не так уж редко. Она справедлива до тех пор, пока человек не приступает к выполнению научной квалификационной работы. Статистический анализ данных является неотъемлемой частью современной научной методологии. Поэтому, если человек работает над школьным научным проектом, дипломной работой бакалавра, магистерской, кандидатской или докторской диссертацией, он должен предъявить соответствующие данному квалификационному уровню умения грамотно получать данные и выделять из них наиболее существенные закономерности с использованием статистических методов. Поэтому, пока Вы занимаетесь научной работой, Вы ? статистик. Только что увидел вот такое
Эскизы прикрепленных изображений
|
|
|
|
|

|
|
|