Здравствуйте, гость ( Вход | Регистрация )


 23.11.2017 - 16:13 23.11.2017 - 16:13
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Имеются данные (процентное содержание фракций A, B и C (столбцы 2-4) и общее количество (столбец 1) определенных липидов в плазме), взятые у одного контрольного индивида (1) и полсотни испытуемых (2-48) после воздействия неким агентом. Как правильно статистически обработать эти данные, и какие и чем обоснованные выводы в результате можно сделать?
Прикрепленные файлы
|
 |
 
|



 |
|
 |
Ответов
(1 - 14)
|
23.11.2017 - 19:49
Сообщение
#2
|
||||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
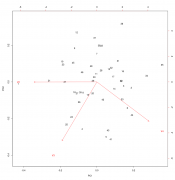
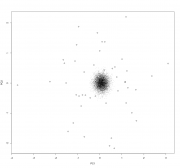
Цитата(Света K @ 23.11.2017 - 16:13)  Имеются данные (процентное содержание фракций A, B и C (столбцы 2-4) и общее количество (столбец 1) определенных липидов в плазме), взятые у одного контрольного индивида (1) и полсотни испытуемых (2-48) после воздействия неким агентом. Как правильно статистически обработать эти данные, и какие и чем обоснованные выводы в результате можно сделать? "Обработать" это жаргон ничего увы конкретного не означающий. 1. Очень странный набор данных. Если у нас есть точка и выборка, то все что мы можем сделать это построить процентили распределения и посмотреть на какой из них попала именно эта точка. mvtnorm: Multivariate Normal and t Distributions https://cran.r-project.org/web/packages/mvt...s/MVT_Rnews.pdf 2. Можно просто посмотреть что там в датасете "глазами" Вот например читаем данные и смотрим на большую часть дисперсии в них. Номера точки соответствуют нумерации в файле Код > df.lipid <-read.csv2("Фракционный состав.csv", header=F) > plot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) > biplot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) Ну и например можно оценить где здесь среднее арифметическое многомерного распределения, и его квантили визуально оценить бутсрепом. Код > butstrep <- do.call(rbind,
replicate(10000, predict(df.lipid.pca, data.frame(t(colMeans((df.lipid[-1,2:4]/df.lipid[-1,1])[sample(1:(48-1), replace=T),])))), simplify=F) ) > plot(df.lipid.pca$x[,1:2]) > points(butstrep[,1:2], pch=".") Сообщение отредактировал p2004r - 23.11.2017 - 19:50
Эскизы прикрепленных изображений
 |
|||
|
|
|

|
|
|
23.11.2017 - 22:43
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 231 Регистрация: 27.04.2016 Пользователь №: 28223 |
Ну у вас и примерчики. То выборки из четырех элментов с необходимостью провести параметрический (!) анализ различия средних. А вот теперь выборка 1+47. Прям экстрим какой-то.
Действительно, с такой выборкой трудно что-то вразумительное предложить. Если бы меня заставили это сделать (под пытками  ), ну возможно я бы психанул и провел кластеризацию, а потом посмотрел, выпадает-ли у меня первый элемент в отдельный кластер (такой себе Anomaly Detection наоборот). По ходу - может что-то интересное в структуре остальной выборки обнаружилось-бы. А больше ничего в голову и не приходит. ), ну возможно я бы психанул и провел кластеризацию, а потом посмотрел, выпадает-ли у меня первый элемент в отдельный кластер (такой себе Anomaly Detection наоборот). По ходу - может что-то интересное в структуре остальной выборки обнаружилось-бы. А больше ничего в голову и не приходит.
Сообщение отредактировал passant - 23.11.2017 - 22:46 |
|
|
|
|
|
|
23.11.2017 - 22:46
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
>p2004r
С обычным PCA здесь засада в виде композиционного характера данных. Где проходит граница допустимой степени "композиционности" не известно. Но традиционно для долей процентов (типа миллиграммы на литр или килограмм) ей пренебрегают и скорее всего обосновано. Но когда речь идёт о % и десятках процентов, композиции будут натягивать ложные корреляции. С 1990-х для многомерного анализа композиционных данных используют статистику Эйчисона, в т.ч. специальные предварительные преобразования "разворачивающие" constrained данные в как бы независимые. Разбирался давно и использовал ещё аддон к экселю "CoDaPack". Сейчас это есть в r, но пока не было подходящей задачи: http://www.stat.boogaart.de/compositions/ https://cran.r-project.org/web/packages/rob...ions/index.html |
|
|
|

|
|
|
24.11.2017 - 01:35
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(nokh @ 23.11.2017 - 22:46) >p2004r С обычным PCA здесь засада в виде композиционного характера данных. Где проходит граница допустимой степени "композиционности" не известно. Но традиционно для долей процентов (типа миллиграммы на литр или килограмм) ей пренебрегают и скорее всего обосновано. Но когда речь идёт о % и десятках процентов, композиции будут натягивать ложные корреляции. С 1990-х для многомерного анализа композиционных данных используют статистику Эйчисона, в т.ч. специальные предварительные преобразования "разворачивающие" constrained данные в как бы независимые. Разбирался давно и использовал ещё аддон к экселю "CoDaPack". Сейчас это есть в r, но пока не было подходящей задачи: http://www.stat.boogaart.de/compositions/ https://cran.r-project.org/web/packages/rob...ions/index.html PCA прекрасно расправляет "смеси" в тернарные трафики, отжимая лишнюю размерность. Здесь просто крайне мал размах варьирования состава, вот и не видно результирующего "треугольника(пирамиды)". |
|
|
|
|
|
|
24.11.2017 - 08:56
Сообщение
#6
|
|||||
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
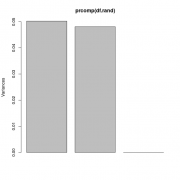
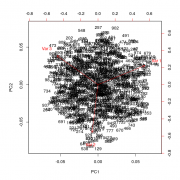
Цитата(nokh @ 23.11.2017 - 22:46) >p2004r С обычным PCA здесь засада в виде композиционного характера данных. Где проходит граница допустимой степени "композиционности" не известно. Но традиционно для долей процентов (типа миллиграммы на литр или килограмм) ей пренебрегают и скорее всего обосновано. Но когда речь идёт о % и десятках процентов, композиции будут натягивать ложные корреляции. С 1990-х для многомерного анализа композиционных данных используют статистику Эйчисона, в т.ч. специальные предварительные преобразования "разворачивающие" constrained данные в как бы независимые. Разбирался давно и использовал ещё аддон к экселю "CoDaPack". Сейчас это есть в r, но пока не было подходящей задачи: http://www.stat.boogaart.de/compositions/ https://cran.r-project.org/web/packages/rob...ions/index.html Вот иллюстрация (именно для больших колебаний состава) Код > df.rand <- t(apply(t(replicate(1000, runif(3))), 1, function(d) d/sum(d))) > str(df.rand) num [1:1000, 1:3] 0.3748 0.4819 0.0077 0.2919 0.42 ... > head(df.rand) [,1] [,2] [,3] [1,] 0.374779178 0.32692176 0.29829906 [2,] 0.481935449 0.02743644 0.49062811 [3,] 0.007700625 0.85640582 0.13589356 [4,] 0.291939338 0.62626290 0.08179776 [5,] 0.420032905 0.42936418 0.15060291 [6,] 0.497522641 0.05128767 0.45118969 > plot(prcomp(df.rand)) > biplot(prcomp(df.rand)) Для многомерных данных все также. Вот вариант для "малых колебаний состава смеси" Код > df.rand <- t(apply(t(replicate(1000, 3+runif(3))), 1, function(d) d/sum(d))) > str(df.rand) num [1:1000, 1:3] 0.327 0.329 0.34 0.335 0.321 ... > head(df.rand) [,1] [,2] [,3] [1,] 0.3271537 0.3089877 0.3638586 [2,] 0.3286260 0.3195480 0.3518260 [3,] 0.3397769 0.3595972 0.3006259 [4,] 0.3351038 0.3093977 0.3554985 [5,] 0.3206596 0.3115080 0.3678324 [6,] 0.3065733 0.3678315 0.3255952 > plot(prcomp(df.rand)) > biplot(prcomp(df.rand))
Эскизы прикрепленных изображений
|
||||
|
|
|


|
|
|
24.11.2017 - 10:30
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(p2004r @ 23.11.2017 - 20:49) 2. Можно просто посмотреть что там в датасете "глазами" Визуально я вижу, что агент слегка уменьшает количество фракции А, очень сильно увеличивает количество фракции С, но не влияет на фракцию В. Общее количество также не меняется. Но вряд ли можно об этом (или о другом возможном выводе) написать без приведения каких-либо подтверждающих статистик или графиков. А здесь нужно именно написать. Цитата(p2004r @ 23.11.2017 - 20:49) Код > df.lipid <-read.csv2("Фракционный состав.csv", header=F) > plot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) > biplot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) Это какая конкретно программа (и версия) и где ее взять? И как туда ввести приведенный код? Цитата(passant @ 23.11.2017 - 23:43) я бы психанул и провел кластеризацию Этого пока мне маловато - можно конкретнее, пожалуйста, какой общедоступной программой и как именно? PS Остальные комменты в процессе... |
|
|
|
|
|
|
24.11.2017 - 11:06
Сообщение
#8
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 24.11.2017 - 10:30) Это какая конкретно программа (и версия) и где ее взять? И как туда ввести приведенный код? https://ru.wikipedia.org/wiki/R_(%D1%8F%D0%...BD%D0%B8%D1%8F) |
|
|
|
|
|
|
24.11.2017 - 11:13
Сообщение
#9
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 24.11.2017 - 10:30) Визуально я вижу, что агент слегка уменьшает количество фракции А, очень сильно увеличивает количество фракции С, но не влияет на фракцию В. Настоящие влияния агента не совсем такие. А соответствуют влиянию агента и ничему больше. В соответствуют влиянию агента, но это влияние слабо + B имеет собственную динамику С соответствует влиянию агента сильнее чем A, но "в противофазе". |
|
|
|
|
|
|
24.11.2017 - 14:38
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 231 Регистрация: 27.04.2016 Пользователь №: 28223 |
Цитата(Света K @ 24.11.2017 - 10:30) Этого пока мне маловато - можно конкретнее, пожалуйста, какой общедоступной программой ? Ответ уже дал уважаемый p2004r - R https://www.r-project.org/ Цитата(Света K @ 24.11.2017 - 10:30) и как именно? Существуют десятки пакетов для R с реализацией различных алгоритмов кластерного анализа: https://www.rdocumentation.org/taskviews#Cluster https://cran.r-project.org/web/views/Cluster.html Выбирайте любой. Или тот, описание к которому легче найти в сети. Сообщение отредактировал passant - 24.11.2017 - 14:41 |
|
|
|
|
|
|
24.11.2017 - 18:45
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 19 Регистрация: 15.12.2011 Пользователь №: 23369 |
Цитата(p2004r @ 23.11.2017 - 20:49) Код > df.lipid <-read.csv2("Фракционный состав.csv", header=F) > plot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) > biplot(prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T)) Да, теперь это работает, спасибо. Однако, чтобы ответ был полезен не только тому, кто отвечает, но и тому, кто задал вопрос, необходимо объяснить, что показано на рисунках (наверно, это рис.1 и 2). Пока что для меня это просто какая-то дисперсия в 3 столбцах и какое-то рассеяние с какими-то векторами v2-v4 по каким-то осям pc1 и pc2. Можете подробно объяснить? Цитата(p2004r @ 23.11.2017 - 20:49) Код > butstrep <- do.call(rbind, replicate(10000, predict(df.lipid.pca, data.frame(t(colMeans((df.lipid[-1,2:4]/df.lipid[-1,1])[sample(1:(48-1), replace=T),])))), simplify=F) ) > plot(df.lipid.pca$x[,1:2]) > points(butstrep[,1:2], pch=".") Это не работает (наверно это рис.3): Ошибка в predict(df.lipid.pca, data.frame(t(colMeans((df.lipid[-1, 2:4]/df.lipid[-1, : объект 'df.lipid.pca' не найден Цитата(passant) Существуют десятки пакетов для R с реализацией различных алгоритмов кластерного анализа Да, по Вашим ссылкам полно пакетов, спасибо. Но внятного объяснения с примером пока не нашлось. Поищу еще на досуге (хотя может такого объяснения и нет). |
|
|
|
|
|
|
24.11.2017 - 21:55
Сообщение
#12
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 24.11.2017 - 18:45) Да, теперь это работает, спасибо. Однако, чтобы ответ был полезен не только тому, кто отвечает, но и тому, кто задал вопрос, необходимо объяснить, что показано на рисунках (наверно, это рис.1 и 2). Пока что для меня это просто какая-то дисперсия в 3 столбцах и какое-то рассеяние с какими-то векторами v2-v4 по каким-то осям pc1 и pc2. Можете подробно объяснить? Это не работает (наверно это рис.3): Ошибка в predict(df.lipid.pca, data.frame(t(colMeans((df.lipid[-1, 2:4]/df.lipid[-1, : объект 'df.lipid.pca' не найден Да, по Вашим ссылкам полно пакетов, спасибо. Но внятного объяснения с примером пока не нашлось. Поищу еще на досуге (хотя может такого объяснения и нет). Да, пропущена строчка сохранения результатов PCA, но сам PCA явно проводиться в первой части приведенного кода. Просто сохраните его. df.lipid.pca <- prcomp(df.lipid[,2:4]/df.lipid[,1], center=T, scale.=T) |
|
|
|
|
|
|
25.11.2017 - 20:14
Сообщение
#13
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(Света K @ 24.11.2017 - 18:45) Да, теперь это работает, спасибо. Однако, чтобы ответ был полезен не только тому, кто отвечает, но и тому, кто задал вопрос, необходимо объяснить, что показано на рисунках (наверно, это рис.1 и 2). Пока что для меня это просто какая-то дисперсия в 3 столбцах и какое-то рассеяние с какими-то векторами v2-v4 по каким-то осям pc1 и pc2. Можете подробно объяснить? Прочитайте что такое тернарный график https://en.wikipedia.org/wiki/Ternary_plot и как работать с данными о составе смесей (или результатов голосований). Собственно тернарный рафик в результате PCA датасета составов смесей и получается всегда. Можно взять пакет R http://www.ggtern.com/ и построить процентили распределения смеси липидов в нем. Сообщение отредактировал p2004r - 25.11.2017 - 20:16 |
|
|
|
|
|
|
25.11.2017 - 22:48
Сообщение
#14
|
|
|
Группа: Пользователи Сообщений: 109 Регистрация: 27.12.2015 Пользователь №: 27815 |
2 p2004r
Добрый вечер. У Вас df.rand1 <- t(apply(t(replicate(1000, runif(3))), 1, function(d) d/sum(d))) df.rand2 <- t(apply(t(replicate(1000, 3+runif(3))), 1, function(d) d/sum(d))) p1 <- prcomp(df.rand1) p2 <- prcomp(df.rand2) Можете показать пример, как "сравнить/обработать" p1 и p2 и заполучить "заветное p<0.05"? |
|
|
|
|
|
|
26.11.2017 - 20:02
Сообщение
#15
|
|
|
Группа: Пользователи Сообщений: 1091 Регистрация: 26.08.2010 Пользователь №: 22699 |
Цитата(comisora @ 25.11.2017 - 22:48) 2 p2004r Добрый вечер. У Вас df.rand1 <- t(apply(t(replicate(1000, runif(3))), 1, function(d) d/sum(d))) df.rand2 <- t(apply(t(replicate(1000, 3+runif(3))), 1, function(d) d/sum(d))) p1 <- prcomp(df.rand1) p2 <- prcomp(df.rand2) Можете показать пример, как "сравнить/обработать" p1 и p2 и заполучить "заветное p<0.05"? У меня не так. У меня сделан predict() по однократно сделанному анализу. Процентили для набора смесей считает пакет из поста (где то целая книжка попадалась как в R работать с данными о процентном составе смесей, сейчас не соображу). |
|
|
|
|
|
 |