Здравствуйте, гость ( Вход | Регистрация )


 5.10.2013 - 16:25 5.10.2013 - 16:25
Сообщение
#1
|
||||
|
Группа: Пользователи Сообщений: 1 Регистрация: 5.10.2013 Пользователь №: 25384 |
Помогите разобраться с обработкой данных в STATISTICA. Имеется несколько человек, с каждого снимали данные четыре раза: два раза при задании 1 и два раза при задании 2.
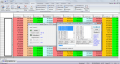
Данные представляют собой значения для нескольких регионов интереса (поля Бродмана и др). Задача: посмотреть контраст ЗАДАНИЕ 1 - ЗАДАНИЕ 2 и контраст ЗАДАНИЕ 2 - ЗАДАНИЕ 1. Имена людей записал в столбец. В строку var я записал такую последовательность: Поле_Бродмана_1_условие11, Поле_Бродмана_1_условие12, Поле_Бродмана_1_условие21, Поле_Бродмана_1_условие22 .... Поле_Бродмана_40_условие11, Поле_Бродмана_40_условие12 ... Где условие 11 значит, что это первое сканирование при задании 1; условие 12 значит, что это второе сканирование при задании 1; условие 21 значит, что это первое сканирование при задании 2; условие 22 значит, что это второе сканирование при задании 2. Скриншот таблицы в экселе.
Вставляю эту таблицу в STATISTICA, жму Repeated measures ANOVA, в Variables выбираю четыре скана для одного региона интереса, в Within effects пишу 4. Скриншот таблицы в статистике.
Жму ок, смотрю график:
1)Если бы различия были значимы, мог бы я интерпретировать данные так: значения при задании 1 больше, чем значения при задании 2? 2)Какие есть способы обнаружить людей, у которых данные сильно отличаются от других, и которых нужно исключить из анализа? 3)Как я могу сделать линейный контраст 1/4+1/4-1/4-1/4? 4)Правильно ли я воспользовался Repeated measures ANOVA, или таблицу нужно составить другим образом? Помогите хотя бы с 4-м вопросом. Спасибо! Сообщение отредактировал Petroholod - 6.10.2013 - 21:40 |
|||
 |
 
|




 |
|
 |
Ответов
|
8.10.2013 - 21:36
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
>anserovtv
Цитата(anserovtv @ 8.10.2013 - 22:37)  Вы все перепутали. В том виде, как представлены данные, у вас не один, а два внутригрупповых фактора (каждый с двумя уровнями) 1 отсрочка( первый этап,второй этап) 2 задание ( первое, второе). Обычно этот фактор является межгрупповым. Если 2 измерения - просто 2 случайные реализации одной процедуры, то фактор 1 можно опустить. В этом случае именно данная пара измерений будет наименьшей ячейкой дисперсионного комплекса, по которой будет рассчитана ошибка. Его имеет смысл выделять в самостоятельный фактор только если есть основания считать, что это не 2 случайных измерения из бесконечного числа возможных, а именно "этап" - фиксированный по плану эксперимента фактор, который можно воспроизвести. Скажем, если измерения сделаны на разных сроках лечения или типа того. С остальным в основном согласен. >Petroholod Ваш дизайн - это не обычные повторные измерения. Если бы вы измеряли каждого только дважды (задание 1 и 2) - то можно было бы сделать как у вас. Но у вас эти измерения продублированы, что для точности измерения интерсующего фактора "Задание" очень хорошо. В вашем случае я бы сделал двухфакторный дисперсионный анализ с случайным фактором "Индивид" (чтобы учесть зависимый характер выборок). Для этого нужно ВСЕ измерния помесить в первый столбец, скажем "Поле_Бродмана", во второй столбец "Индивид" - проставить индивидуальные метки людей от 1 до 22, в третий столбец "Задание" проставить коды 1 или 2. Если вы выложите сюда такой файл, то я смогу показать: как сделать этот анализ в модуле "Общие линейные модели", как задать случайный фактор и как задать контраст для запланированных сравнений. ! Файл либо в xls, либо Statistica не старше 8 версии. В архиве, иначе не подошьётся к сообщению. >anserovtv В SPSS ДА любой сложности в рамках классической General LM намного удобнее задавать через синтаксис (через меню у меня не всё получалось). Описанный выше дизайн можно сделать так: поместить организованный описанным способом файл brodman.sav в корень диска С: и запустить синтаксис: GET FILE='C:\brodman.sav'. DATASET NAME DataSet1 WINDOW=FRONT. UNIANOVA Data BY Ind Var /RANDOM = Ind /METHOD = SSTYPE(3) /INTERCEPT = EXCLUDE /CRITERIA = ALPHA(.05) /DESIGN = Ind Var Ind*Var. Сообщение отредактировал nokh - 8.10.2013 - 21:58 |
|
|
|

|
|
Сообщений в этой теме
 Petroholod Repeated measures ANOVA 5.10.2013 - 16:25
Petroholod Repeated measures ANOVA 5.10.2013 - 16:25 anserovtv Вы все перепутали. В том виде, как представлены да... 8.10.2013 - 19:37 anserovtv А я подумал, что сканирования значимы, иначе их б... 8.10.2013 - 22:21
anserovtv Вы все перепутали. В том виде, как представлены да... 8.10.2013 - 19:37 anserovtv А я подумал, что сканирования значимы, иначе их б... 8.10.2013 - 22:21
 nokh Цитата(anserovtv @ 9.10.2013 - 01:21... 8.10.2013 - 22:31 anserovtv Было бы интересно сравнить результаты ДА данных Pe... 9.10.2013 - 13:26 Vitek_22 Пришлось мне впервые посчитать ANOVA (one-way) в S... 24.11.2013 - 21:02 100$ Цитата(Vitek_22 @ 24.11.2013 - 22:02... 25.11.2013 - 09:31
nokh Цитата(anserovtv @ 9.10.2013 - 01:21... 8.10.2013 - 22:31 anserovtv Было бы интересно сравнить результаты ДА данных Pe... 9.10.2013 - 13:26 Vitek_22 Пришлось мне впервые посчитать ANOVA (one-way) в S... 24.11.2013 - 21:02 100$ Цитата(Vitek_22 @ 24.11.2013 - 22:02... 25.11.2013 - 09:31 |