Здравствуйте, гость ( Вход | Регистрация )


 5.10.2013 - 16:25 5.10.2013 - 16:25
Сообщение
#1
|
||||
|
Группа: Пользователи Сообщений: 1 Регистрация: 5.10.2013 Пользователь №: 25384 |
Помогите разобраться с обработкой данных в STATISTICA. Имеется несколько человек, с каждого снимали данные четыре раза: два раза при задании 1 и два раза при задании 2.
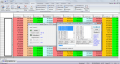
Данные представляют собой значения для нескольких регионов интереса (поля Бродмана и др). Задача: посмотреть контраст ЗАДАНИЕ 1 - ЗАДАНИЕ 2 и контраст ЗАДАНИЕ 2 - ЗАДАНИЕ 1. Имена людей записал в столбец. В строку var я записал такую последовательность: Поле_Бродмана_1_условие11, Поле_Бродмана_1_условие12, Поле_Бродмана_1_условие21, Поле_Бродмана_1_условие22 .... Поле_Бродмана_40_условие11, Поле_Бродмана_40_условие12 ... Где условие 11 значит, что это первое сканирование при задании 1; условие 12 значит, что это второе сканирование при задании 1; условие 21 значит, что это первое сканирование при задании 2; условие 22 значит, что это второе сканирование при задании 2. Скриншот таблицы в экселе.
Вставляю эту таблицу в STATISTICA, жму Repeated measures ANOVA, в Variables выбираю четыре скана для одного региона интереса, в Within effects пишу 4. Скриншот таблицы в статистике.
Жму ок, смотрю график:
1)Если бы различия были значимы, мог бы я интерпретировать данные так: значения при задании 1 больше, чем значения при задании 2? 2)Какие есть способы обнаружить людей, у которых данные сильно отличаются от других, и которых нужно исключить из анализа? 3)Как я могу сделать линейный контраст 1/4+1/4-1/4-1/4? 4)Правильно ли я воспользовался Repeated measures ANOVA, или таблицу нужно составить другим образом? Помогите хотя бы с 4-м вопросом. Спасибо! Сообщение отредактировал Petroholod - 6.10.2013 - 21:40 |
|||
 |
 
|




 |
|
 |
Ответов
|
9.10.2013 - 13:26
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 219 Регистрация: 4.06.2013 Из: Тверь Пользователь №: 24927 |
Было бы интересно сравнить результаты ДА данных Petroholod в обоих пакетах: STATISTICA и SPSS.
nokh По вашему командному файлу - не смог разобраться в /спецификациях/ переменных / выдает ошибку/. Если этот командный файл немного исправить, то его можно запускать из открытого файла с данными. Видимо, в этот командный файл нужно добавить и графику? По книге - у меня такой формат не читается, если можно пришлите скан или сами данные с комментариями. Я понимаю, вроде бы, с чем у вас могут быть проблемы в многомерном случае - нужно правильно задавать имена переменных. Например: плотность генерируется из переменных: плотность1, плотность2, плотность3 и т.д. Переменную плотность нужно задавать в самом начале. В SPSS имеются подсказки. Существует альтернатива ДА в SEM. Я понял . в чем состоит ее основное преимущество: можно оценивать общие, прямые и косвенные эффекты!!! Было бы интересно понять, как соотносятся Смешанные линейные модели и SEM. Сообщение отредактировал anserovtv - 10.10.2013 - 06:52 |
|
|
|

|
|
Сообщений в этой теме
 Petroholod Repeated measures ANOVA 5.10.2013 - 16:25
Petroholod Repeated measures ANOVA 5.10.2013 - 16:25 anserovtv Вы все перепутали. В том виде, как представлены да... 8.10.2013 - 19:37 nokh >anserovtv
Цитата(anserovtv @ 8.10.2013 ... 8.10.2013 - 21:36 anserovtv А я подумал, что сканирования значимы, иначе их б... 8.10.2013 - 22:21
anserovtv Вы все перепутали. В том виде, как представлены да... 8.10.2013 - 19:37 nokh >anserovtv
Цитата(anserovtv @ 8.10.2013 ... 8.10.2013 - 21:36 anserovtv А я подумал, что сканирования значимы, иначе их б... 8.10.2013 - 22:21
 nokh Цитата(anserovtv @ 9.10.2013 - 01:21... 8.10.2013 - 22:31 Vitek_22 Пришлось мне впервые посчитать ANOVA (one-way) в S... 24.11.2013 - 21:02 100$ Цитата(Vitek_22 @ 24.11.2013 - 22:02... 25.11.2013 - 09:31
nokh Цитата(anserovtv @ 9.10.2013 - 01:21... 8.10.2013 - 22:31 Vitek_22 Пришлось мне впервые посчитать ANOVA (one-way) в S... 24.11.2013 - 21:02 100$ Цитата(Vitek_22 @ 24.11.2013 - 22:02... 25.11.2013 - 09:31 |