Здравствуйте, гость ( Вход | Регистрация )


 18.03.2015 - 15:12 18.03.2015 - 15:12
Сообщение
#1
|
||
|
Группа: Пользователи Сообщений: 24 Регистрация: 11.06.2014 Пользователь №: 26460 |
Добрый день!
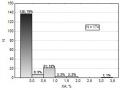
Прошу помочь в понимании следующего вопроса. Распределение значений некоего параметра представлено на рисунке.
Видно, что большинство значений (80%) = 0. Нужно сравнить 2 группы по данному параметру. Вопрос: можно ли применять для сравнения критерий Манна-Уитни, учитывая, что 80% значений признака идентичны, или здесь есть некие проблемы? В сети нашел следующую информацию "...основное (принципиально важное) условие применимости критерия МУ: он применим ТОЛЬКО к мерным данным, т.е. таким, моделью для которых являются НЕПРЕРЫВНЫЕ случайные величины (я предпочитаю называть их "вероятностными переменными"). На практике это означает, что среди анализируемых данных не должно быть совпадающих (повторяющихся ? tied ??связанных?) значений. На практике совпадения почти неизбежны, и если их немного, то их влияние не столь заметно, и есть формулы для соответствующих поправок. Но надо знать, что при наличии совпадений критерий перестает быть свободным от распределения (непараметрическим); он начинает зависеть от неизвестной вероятности совпадений." Товарищи, прокомментируйте пожалуйста! Сообщение отредактировал don - 23.03.2015 - 09:11 |
|
 |
 
|


 |
|
 |
Ответов
|
22.03.2015 - 16:27
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 24 Регистрация: 11.06.2014 Пользователь №: 26460 |
Благодарю за ответ!
На рисунке - распределение частот аберраций в группе облученных лиц. Я решил разбить данную выборку на 2 категории: 1) ниже референтного значения (0,2% в среднем для контрольной группы по результатам исследований) и 2) выше 0,2% и таким образом перейти от непрерывной величины к бинарной |
|
|
|
|
|
|
26.03.2015 - 19:30
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(don @ 22.03.2015 - 18:27)  Я решил разбить данную выборку на 2 категории: 1) ниже референтного значения (0,2% в среднем для контрольной группы по результатам исследований) и 2) выше 0,2% и таким образом перейти от непрерывной величины к бинарной Нормально, логика в этом есть: по результатам такой таблицы можно рассчитать именно относительный риск превышения частоты ХА контрольного уровня. Мне больше нравится относительный риск - вполне понятная мера, для RR также можно рассчитать 95% ДИ - вполне современно будет. Сейчас отношения шансов толкают куда надо и не надо... По поводу мощности не грейтесь: её всегда не хватает в Зазеркалье. А в нашем реальном мире - это уже проведённое исследование, а после драки кулаками не машут: есть именно то, что имеем. Если стоим на фриквентистских позициях - считаем р-значение, на байесовских позициях - байесовский фактор и не ноем. Цитата(don @ 23.03.2015 - 11:10) Имеется 13 SNP локусов, между генотипами которых (с использованием разных генетич. моделей) планируется оценить различие в ХА. Боюсь, что при разделении на количество групп большее чем 2, в таблицах сопряженности будет часто встречаться нулевая частота. Если считать дедовским способами - действительно, могут быть проблемы. Если хотите серьёзную современную статистику - никакого хи-квадрата (он хуже обоснован теоретически G-критерия отношения правдоподобия) и никакого точного метода Фишера (он базируется на гипергеометрическом распределении, а в наших задачах - биномиальное или полиномиальное). Таблицы сопряжённости нужно обсчитывать точным перестановочным критерием (exact permutation test) - никаких проблем с нулевыми ячейками. Специализированная программа - StatXact от Cytel Studio, разработчики других пакетов пользуются их алгоритмами по лицензии. Кстати там же можно обсчитать таблицы с упорядоченными категориями, если там есть Манн - Уитни - можно пользоваться + их руководство полистать, оно качественное. |
|
|
|
|
|
Сообщений в этой теме
 don Критерий Манна-Уитни 18.03.2015 - 15:12
don Критерий Манна-Уитни 18.03.2015 - 15:12 nokh Цитата(don @ 18.03.2015 - 17:12) Доб... 19.03.2015 - 20:59
nokh Цитата(don @ 18.03.2015 - 17:12) Доб... 19.03.2015 - 20:59
 don Цитата(nokh @ 19.03.2015 - 23:59) (1... 23.03.2015 - 09:10 anserovtv Цитата(don @ 22.03.2015 - 16:27) Я р... 23.03.2015 - 08:14 don Цитата(anserovtv @ 23.03.2015 - 11:1... 23.03.2015 - 08:56 anserovtv Да, критерий Фишера или хи-квадрат.
http://vigg.ru... 23.03.2015 - 16:47
don Цитата(nokh @ 19.03.2015 - 23:59) (1... 23.03.2015 - 09:10 anserovtv Цитата(don @ 22.03.2015 - 16:27) Я р... 23.03.2015 - 08:14 don Цитата(anserovtv @ 23.03.2015 - 11:1... 23.03.2015 - 08:56 anserovtv Да, критерий Фишера или хи-квадрат.
http://vigg.ru... 23.03.2015 - 16:47 |