Здравствуйте, гость ( Вход | Регистрация )


 12.03.2017 - 23:54 12.03.2017 - 23:54
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 12.03.2017 Пользователь №: 29479 |
Уважаемые участники форума, пожалуйста
 разобраться с несколькими неясными моментами с которыми мне пришлось столкнуться в процессе подготовки диссертации и изучения статистики в целом. разобраться с несколькими неясными моментами с которыми мне пришлось столкнуться в процессе подготовки диссертации и изучения статистики в целом.1. При описании количественных данных рекомендуется использовать среднее и стандартное отклонение при нормальном распределении, медиану и интерквартильный размах при ненормальном распределении. Что лучше указывать, если часть данных имеет ненормальное распределение, а часть данных нормальное? Особенно при публикации статьи, где объем ограничен. Логика мне подсказывает, что если больше переменных с ненормальным распределением, то использовать для всех медиану и интерквартильный размах. А если большая часть переменных имеет нормальное распределение, но есть несколько с ненормальным? 2. К примеру в исследовании было 100 пациентов. Исследователь решил разделить выборку на две группы (40 и 60 пациентов) в зависимости от какого-то признака. При сравнении групп различия не были выявлены. Тогда исследователь решил разделить эту же выборку по другому параметру на другие группы (30 и 70 пациентов). Насколько корректно это делать? Ведь таким образом исследователь может поступать неограниченное количество раз. Насколько корректно представлять при публикации такой подход, например в статье? Или существуют какие-то поправки? 3. Чисто практический вопрос по R. Пытаясь нарисовать график в ggplot2, столкнулся с непонятной проблемой. Была у меня таблица, где всего два вектора: гистология (hist) и дата (date), (третий появился позже). # A tibble: 1,580 × 3 hist date histo <8322456> <dbl> <fctr> 1 brest 2000 brest 2 brest 2000 brest 3 brest 2001 brest 4 brest 2001 brest 5 brest 2001 brest 6 brest 2003 brest 7 brest 2003 brest 8 brest 2003 brest 9 brest 2003 brest 10 brest 2003 brest # ... with 1,570 more rows Хотел наглядно показать сколько случаев конкретной опухоли было в конкретный год. Нарисовал соответствующий график с разбивкой на фасеты, т.к. каких-то опухолей было очень много, а какие-то встречаются совсем редко. histology <- list( 'brest'="Молочная железа", 'cerv'="Шейка матки", 'colon'="Толстая кишка", 'lung'="Легкое", 'melanoma'="Кожа", 'prost'="Простата", 'rcc'="Почка", 'uter'="Тело матки", 'metastatic'="Все метастатические") h_labeller <- function(variable,value){ return(histology[value])} ggplot(th, aes(x=th$date)) + geom_bar() + facet_wrap(~ th$hist, ncol=3, labeller=h_labeller, scales="free_y") + xlab("") + ylab("") + scale_x_continuous(breaks=seq(2000, 2015, 3)) Но на последнем этапе изменения порядка фасетов почему-то теряются наблюдения на самом графике. Он становится другой (картинки прикрепил). th$histo = factor(th$hist, levels=c('brest','rcc','lung', 'colon', 'prost', 'uter', 'cerv', 'melanoma', 'metastatic')) ggplot(th, aes(x=th$date)) + geom_bar() + facet_wrap(~ th$histo, ncol=3, scales="free_y") + xlab("") + ylab("") + scale_x_continuous(breaks=seq(2000, 2015, 3)) Пожалуйста, разобраться в этой проблеме. Я подозреваю, что ответ где-то на поверхности, но этот затык мне не получилось решить самому. Как изменить порядок фасетов без изменения вида графиков и потери наблюдений?Уже знаю, что можно сторонними пакетами сделать фасеты из обычных графиков, но данный затык не дает покоя.  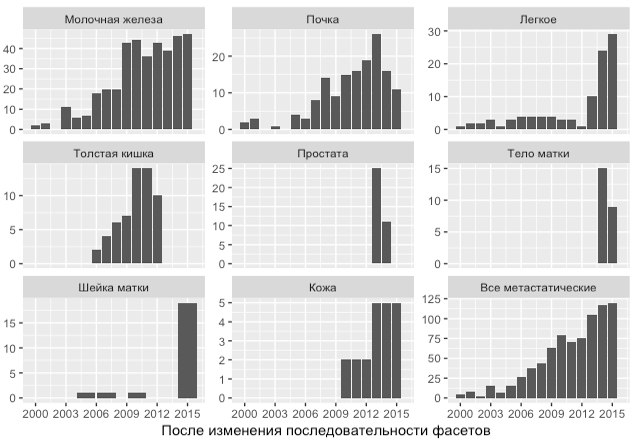
|
 |
 
|


 |
|
 |
Ответов
|
13.03.2017 - 23:05
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(nikita_zab @ 13.03.2017 - 01:54)  1. При описании количественных данных рекомендуется использовать среднее и стандартное отклонение при нормальном распределении, медиану и интерквартильный размах при ненормальном распределении. Что лучше указывать, если часть данных имеет ненормальное распределение, а часть данных нормальное? Особенно при публикации статьи, где объем ограничен. Логика мне подсказывает, что если больше переменных с ненормальным распределением, то использовать для всех медиану и интерквартильный размах. А если большая часть переменных имеет нормальное распределение, но есть несколько с ненормальным? Рекомендаций и "рекомендаций" много - кем это рекомендуется? Я бы сказал, что вопрос выбора показателей для описания данных - больше вопрос традиции в конкретных областях или даже научных школах. Чем плохо стандартное отклонение для ненормального распределения? Только тем, что не несёт геометрической интерпретации. Но геологов, которые к нему привыкли, это не смущает: могут давать его даже для данных у которых хвосты распределений поджимаются только логарифмированием и (!) логарифмированием логарифмов. Полагаю, что если ст. отклонение и медиана с квартилями не представляют специального самостоятельного интереса - ими можно и пожертвовать. Для себя проблему описательной статистики я решил через интервальную оценку среднего: 95%-ные доверительные интервалы действительно рекомендуют + такие работы лучше цитируются, поскольку посредством сопоставления ДИ можно делать выводы о статистической значимости различий собственных данных с опубликованными и/или включать статьи в мета-анализ. ДИ можно рассчитать и для нормально-, и ненормально распределённых данных, и для частот - нужно только найти правильные способы. Цитата(nikita_zab @ 13.03.2017 - 01:54) 2. К примеру в исследовании было 100 пациентов. Исследователь решил разделить выборку на две группы (40 и 60 пациентов) в зависимости от какого-то признака. При сравнении групп различия не были выявлены. Тогда исследователь решил разделить эту же выборку по другому параметру на другие группы (30 и 70 пациентов). Насколько корректно это делать? Ведь таким образом исследователь может поступать неограниченное количество раз. Насколько корректно представлять при публикации такой подход, например в статье? Или существуют какие-то поправки? Тут сложно что-то советовать, т.к. это зависит от контекста. (1) Например, традиционно считается, что и первый и второй показатель неплохо или близко характеризуют одно явление. Ну например шкалы APACHE и SAPS или шкалы Сильвермана и Апгар. При разбиении по одной шкале вы не получаете различий, по другой - получаете. Налицо противоречие, которое можно выгодно преподнести, обсудить, сравнить шкалы специальными методами и т.д. Тогда, конечно, и можно и нужно объединять в одной работе. (2) Если же из контекста видно, что автор ищет хоть какие-то различия и группировки - то налицо огрехи планирования исследования и такие разбиения никак нельзя совмещать в одной статье. Вообще, ситуация, когда данные собираются под одну гипотезу, а она не оправдывается - весьма распространена. Но при грамотном руководителе и качественно собранных данных из них можно вытянуть ещё много чего интересного, вплоть до того, что это интересное может оказаться куда новее и интереснее исходной гипотезы. Но тогда логичнее уже её и презентовать браво, а не посвящать читателя в интимные подробности о том, как хотели одно, а оно не получилось, но зато получилось что-то другое и поэтому не бейте нас пожалуйста... Ещё бывает, что данные обсчитываются при одном разбиении материала, но потом рецензенты или потенциальные оппоненты указывают на огрехи осуществлённой группировки. И человеку приходится полностью пересчитывать работу. А пока он заканчивает обсчёт за рубежом выходит новая классификация, по которой-то оказывается и нужно разбивать материал, иначе возникнут вопросы, и она пересчитывает всё в третий раз (не шучу, знаю такого человека). Но и в этом случае в конечную работу идёт только одна группировка, а то что уже было опубликовано - ну что теперь, типа быльём поросло... Сообщение отредактировал nokh - 13.03.2017 - 23:46 |
|
|
|

|
|
|
14.03.2017 - 12:01
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 12.03.2017 Пользователь №: 29479 |
Цитата(nokh @ 13.03.2017 - 23:05) Рекомендаций и "рекомендаций" много - кем это рекомендуется? Я бы сказал, что вопрос выбора показателей для описания данных - больше вопрос традиции в конкретных областях или даже научных школах. Чем плохо стандартное отклонение для ненормального распределения? Только тем, что не несёт геометрической интерпретации. Но геологов, которые к нему привыкли, это не смущает: могут давать его даже для данных у которых хвосты распределений поджимаются только логарифмированием и (!) логарифмированием логарифмов. Полагаю, что если ст. отклонение и медиана с квартилями не представляют специального самостоятельного интереса - ими можно и пожертвовать. Для себя проблему описательной статистики я решил через интервальную оценку среднего: 95%-ные доверительные интервалы действительно рекомендуют + такие работы лучше цитируются, поскольку посредством сопоставления ДИ можно делать выводы о статистической значимости различий собственных данных с опубликованными и/или включать статьи в мета-анализ. ДИ можно рассчитать и для нормально-, и ненормально распределённых данных, и для частот - нужно только найти правильные способы. Спасибо за ответы! Но чисто с практической стороны, если я составляю таблицу в статье для описания выборки. Будет три столбца, в первом параметр, во втором точечное значение, в третьем интегральное. Какие параметры указывать в качестве точечной оценки? Или заранее можно указать, что при нормальном распределении среднее, при ненормальном медиана? Просто показатели могут сильно различаться. Цитата(nokh @ 13.03.2017 - 23:05) Тут сложно что-то советовать, т.к. это зависит от контекста. (1) Например, традиционно считается, что и первый и второй показатель неплохо или близко характеризуют одно явление. Ну например шкалы APACHE и SAPS или шкалы Сильвермана и Апгар. При разбиении по одной шкале вы не получаете различий, по другой - получаете. Налицо противоречие, которое можно выгодно преподнести, обсудить, сравнить шкалы специальными методами и т.д. Тогда, конечно, и можно и нужно объединять в одной работе. (2) Если же из контекста видно, что автор ищет хоть какие-то различия и группировки - то налицо огрехи планирования исследования и такие разбиения никак нельзя совмещать в одной статье. Вообще, ситуация, когда данные собираются под одну гипотезу, а она не оправдывается - весьма распространена. Но при грамотном руководителе и качественно собранных данных из них можно вытянуть ещё много чего интересного, вплоть до того, что это интересное может оказаться куда новее и интереснее исходной гипотезы. Но тогда логичнее уже её и презентовать браво, а не посвящать читателя в интимные подробности о том, как хотели одно, а оно не получилось, но зато получилось что-то другое и поэтому не бейте нас пожалуйста... Ещё бывает, что данные обсчитываются при одном разбиении материала, но потом рецензенты или потенциальные оппоненты указывают на огрехи осуществлённой группировки. И человеку приходится полностью пересчитывать работу. А пока он заканчивает обсчёт за рубежом выходит новая классификация, по которой-то оказывается и нужно разбивать материал, иначе возникнут вопросы, и она пересчитывает всё в третий раз (не шучу, знаю такого человека). Но и в этом случае в конечную работу идёт только одна группировка, а то что уже было опубликовано - ну что теперь, типа быльём поросло... Был я на одном занятии по статистике. Там разбиралась чья-то диссертация. И как раз в диссертации выборку делили на разные группы постоянно в соответствии с различными признаками. И различия нашли только по одному параметру (10 раз всего разбивали). Преподаватель огласил, что в этом случае полученное значение "p" нужно было умножать на 10. Я потом спрашивал откуда взялось такое, мне было объяснено, что это мол множественные сравнения... Может и правда есть какие-то критерии при таких ситуациях? |
|
|
|
|
|
|
15.03.2017 - 21:50
Сообщение
#4
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(nikita_zab @ 14.03.2017 - 14:01) Спасибо за ответы! Но чисто с практической стороны, если я составляю таблицу в статье для описания выборки. Будет три столбца, в первом параметр, во втором точечное значение, в третьем интегральное. Какие параметры указывать в качестве точечной оценки? Или заранее можно указать, что при нормальном распределении среднее, при ненормальном медиана? Просто показатели могут сильно различаться. Не "интегральное", а интервальное. Приводите то, что обычно приводят в лучших зарубежных статьях в вашей области. Я постепенно прихожу к уменьшению доли порядковой статистики а анализах, но это - путь, который нужно пройти. Как альтернатива медиане и IQR для можно привести (1) среднее с 95% ДИ, вычисленными бутстрепом (2) среднее и 95% ДИ вычисленные по преобразованным данным с ретрансформацией результатов в исходную шкалу (квадратный корень - возведение в квадрат, логарифмирование - потенцирование, преобразование Бокса - Кокса - отратное преобразование...) Смотрел недавно C28-A3c и статьи по референтным интервалам - штука серьёзная, т.к. это проблема нормы и отклонения от неё. Так вот логарифмирование и Бокса-Кокса с последующей ретрансформацией используют широко (наряду с др. техниками). Цитата(nikita_zab @ 14.03.2017 - 14:01) Был я на одном занятии по статистике. Там разбиралась чья-то диссертация. И как раз в диссертации выборку делили на разные группы постоянно в соответствии с различными признаками. И различия нашли только по одному параметру (10 раз всего разбивали). Преподаватель огласил, что в этом случае полученное значение "p" нужно было умножать на 10. Я потом спрашивал откуда взялось такое, мне было объяснено, что это мол множественные сравнения... Может и правда есть какие-то критерии при таких ситуациях? Плохо, что вы были на одном занятии. Про разбиении на группы не понял, но почитайте про поправку Бонферрони и т.п. |
|
|
|
|
|
|
15.03.2017 - 22:26
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 14 Регистрация: 12.03.2017 Пользователь №: 29479 |
Цитата(nokh @ 15.03.2017 - 21:50) Не "интегральное", а интервальное. Приводите то, что обычно приводят в лучших зарубежных статьях в вашей области. Я постепенно прихожу к уменьшению доли порядковой статистики а анализах, но это - путь, который нужно пройти. Как альтернатива медиане и IQR для можно привести (1) среднее с 95% ДИ, вычисленными бутстрепом (2) среднее и 95% ДИ вычисленные по преобразованным данным с ретрансформацией результатов в исходную шкалу (квадратный корень - возведение в квадрат, логарифмирование - потенцирование, преобразование Бокса - Кокса - отратное преобразование...) Смотрел недавно C28-A3c и статьи по референтным интервалам - штука серьёзная, т.к. это проблема нормы и отклонения от неё. Так вот логарифмирование и Бокса-Кокса с последующей ретрансформацией используют широко (наряду с др. техниками). Плохо, что вы были на одном занятии. Про разбиении на группы не понял, но почитайте про поправку Бонферрони и т.п. Про Бонферрони и подобные вещи при множественном сравнении между группами знаю. Был интересен именно описанный случай, но наверное не смогу толком объяснить. В целом в данной теме вы мне помогли немного разобраться в этих вопросах. |
|
|
|
|
|
|
16.03.2017 - 00:40
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(nikita_zab @ 15.03.2017 - 22:26) Про Бонферрони и подобные вещи при множественном сравнении между группами знаю. Был интересен именно описанный случай, но наверное не смогу толком объяснить. Это типичная картинка для отечественных мед. исследований: пациента характеризуют вектором рез-тов рутинных лабораторных исследований, но в многомерную статистику уходить не хотят и ищут различия по каждой координате. Т.е. вместо, н-р, критерия Хотеллинга (многомерного аналога критерия Стьюдента) делают десяток Стьюдентов. Вот и возникает проблема множественных сравнений. |
|
|
|
|
|
Сообщений в этой теме
nikita_zab Несколько вопросов по статистике и R 12.03.2017 - 23:54

 p2004r Цитата(nokh @ 13.03.2017 - 23:05) Ту... 14.03.2017 - 13:24 p2004r Цитата(nikita_zab @ 12.03.2017 - 23... 14.03.2017 - 09:37 nikita_zab Цитата(p2004r @ 14.03.2017 - 09:37) ... 14.03.2017 - 12:02 p2004r Цитата(nikita_zab @ 14.03.2017 - 12... 14.03.2017 - 13:17 nikita_zab Цитата(p2004r @ 14.03.2017 - 13:17) ... 14.03.2017 - 22:06 p2004r А так?
Кодggplot(th, aes(x=date)) ... 15.03.2017 - 12:56 nikita_zab Цитата(p2004r @ 15.03.2017 - 12:56) ... 15.03.2017 - 20:37 p2004r Цитата(nikita_zab @ 15.03.2017 - 20... 16.03.2017 - 11:08
p2004r Цитата(nokh @ 13.03.2017 - 23:05) Ту... 14.03.2017 - 13:24 p2004r Цитата(nikita_zab @ 12.03.2017 - 23... 14.03.2017 - 09:37 nikita_zab Цитата(p2004r @ 14.03.2017 - 09:37) ... 14.03.2017 - 12:02 p2004r Цитата(nikita_zab @ 14.03.2017 - 12... 14.03.2017 - 13:17 nikita_zab Цитата(p2004r @ 14.03.2017 - 13:17) ... 14.03.2017 - 22:06 p2004r А так?
Кодggplot(th, aes(x=date)) ... 15.03.2017 - 12:56 nikita_zab Цитата(p2004r @ 15.03.2017 - 12:56) ... 15.03.2017 - 20:37 p2004r Цитата(nikita_zab @ 15.03.2017 - 20... 16.03.2017 - 11:08 |