Здравствуйте, гость ( Вход | Регистрация )


 22.02.2018 - 15:04 22.02.2018 - 15:04
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Подскажите, как можно решить такую задачу
1. есть данные, в них 20 переменных 2. нужно кластеризовать эти 20 переменных, т.е. выделить классы схожим переменных 3.затем найти людей, которые "кучкуются" у каждого класса переменных. Например мы нашли 4 класса переменных абв, где, ежз, икл. наблюдения 1-30 кучкуются у класса к примеру ежз. |
 |
 
|


 |
|
 |
Ответов
|
23.02.2018 - 14:27
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 76 Регистрация: 27.04.2014 Пользователь №: 26375 |
Добрый день.
Есть 20 переменных(прислала датасет с фиктивными, а то настоящие данные нельзя давать) группировать переменные можно или кластерным анализом или факторным допустим , если мы стали использовать факторный анализ, мы выделил 4 фактора, каждый нагружен тремя переменными. Вопрос то был понять, как наблюдения кучкуются у каждого фактора Я думала выделит факторы, превратить их в регрессионные переменные и по ним сделать кластерный анализ. Я так полагаю nokh это имели ввиду?
Прикрепленные файлы
|
|
|
|

|
|
|
23.02.2018 - 18:30
Сообщение
#3
|
|
|
Группа: Пользователи Сообщений: 902 Регистрация: 23.08.2010 Пользователь №: 22694 |
Цитата(nastushka @ 23.02.2018 - 14:27)  Есть 20 переменных, группировать переменные можно кластерным анализом Можно. Раскочегариваем ф-цию pvclust() из library(pvclust), скармливаем ей датасет, на выходе получаем дендрограмму (см.рис) с оценками AU/BP, видим два кластера признаков, даем им осмысленную интерпретацию, после чего кластеризуем наблюдения для выделенных подмножеств признаков. Действительно, все просто.
Прикрепленные файлы
|
|
|
|
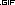
|
|
Сообщений в этой теме
 nastushka Кластерный анализ переменных, с указанием групп 22.02.2018 - 15:04
nastushka Кластерный анализ переменных, с указанием групп 22.02.2018 - 15:04 passant Цитата(nastushka @ 22.02.2018 - 14:0... 22.02.2018 - 15:33 leo_biostat nastushka, !
Весьма неясные Ваши вопросы.
Во... 22.02.2018 - 16:50 100$ Рискну предположить, что имеется 20-мерное признак... 22.02.2018 - 17:52 nokh Цитата(nastushka @ 22.02.2018 - 17:0... 22.02.2018 - 23:07
passant Цитата(nastushka @ 22.02.2018 - 14:0... 22.02.2018 - 15:33 leo_biostat nastushka, !
Весьма неясные Ваши вопросы.
Во... 22.02.2018 - 16:50 100$ Рискну предположить, что имеется 20-мерное признак... 22.02.2018 - 17:52 nokh Цитата(nastushka @ 22.02.2018 - 17:0... 22.02.2018 - 23:07
 p2004r Сейчас есть техники кластеризации когда результат ... 23.02.2018 - 21:18 leo_biostat Цитата(nastushka @ 23.02.2018 - 14:2... 24.02.2018 - 09:07 100$ Цитата(leo_biostat @ 24.02.2018 - 09... 24.02.2018 - 13:07
p2004r Сейчас есть техники кластеризации когда результат ... 23.02.2018 - 21:18 leo_biostat Цитата(nastushka @ 23.02.2018 - 14:2... 24.02.2018 - 09:07 100$ Цитата(leo_biostat @ 24.02.2018 - 09... 24.02.2018 - 13:07 |