Здравствуйте, гость ( Вход | Регистрация )


 21.09.2024 - 15:02 21.09.2024 - 15:02
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 30 Регистрация: 7.12.2012 Пользователь №: 24440 |
Товарищи, подсобите с анализом данных.
3 группы мышей: контроль, больные, леченные. Измерялось пройденное расстояние. Мыши с тяжёлыми двигательными нарушениями, поэтому по сравнению с контролем у них пройденное расстояние отличается на порядок. ANOVA и Tukey апостериорный показывают значимые отличия от контроля. но не между больными и леченными, хотя объективно между ними x2 разница. Интуиция подсказывает, что с такой разницей между средними сравнивать ANOVA некорректно. Но чем тогда и как это объяснить грамотно и какой критерий использовать? Если Стьюдента попарно использовать - выходит норм.
Прикрепленные файлы
|
 |
 
|



 |
|
 |
Ответов
|
24.09.2024 - 03:39
Сообщение
#2
|
||||
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
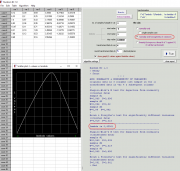
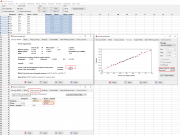
Как уже написал ИНО, требования модели дисперсионного анализа не выполняются: по критерию Левене (или как его по-русски) дисперсии неоднородны, по критерию Шапиро - Уилка остатки распределены ненормально. Прикрепил скриншоты анализа в бесплатном пакете PAST ( https://www.nhm.uio.no/english/research/resources/past/ ), который кстати в ряде моментов умеет больше чем Statistica, хотя сравнивать пакеты сложно, ввиду разных весовых категорий и назначения.
А вот с преобразованиями я бы поработал. Когда нужное преобразование неизвестно исходя из теории, можно использовать степенное преобразование Бокса - Кокса, которое приближает распределение данных к нормальному настолько, насколько позволяют сами данные. Это достигается итерационным подбором параметра лямбда. Преобразование многократно обсуждалось на форуме, но давно это было. Идея здесь такая, что мы можем либо 1) подбирать к нашим данным более подходящую статистическую модель, либо 2) преобразовать наши данные к статистической модели. Чисто философски что лучше 1) или 2) сказать нельзя, поскольку, скажем, если природа данных говорит, что площадь биологического объекта распределена ненормально, а квадратный корень из площади нормально, то естественно работать с квадратным корнем. Или если природа измеряет многие зависящие от скорости процессы скорее логарифмической линейкой, то и нам пользоваться ей естественно (скорость прямой реакции имеет ограничение варьирования слева, т.к. там зона нуля и отрицательных величин, а вправо варьировать можно: получается положительно асимметричное распределение, часто близкое к логнормальному). Для больших любителей непараметрики можно написать, что распространённые ранговые модели может и более универсальны, но не нужно забывать, что там данные тоже преобразуются, причём очень грубо - просто к порядковым местам, рангам. И если мы не видим, как такое преобразование делает статпакет для критерия Манна - Уитни или Краскела - Уоллиса, то это значит просто, что мы не считали критерии вручную и не знаем как работают эти методы. Короче, я за то, чтобы не отказываться от шкалы отношений или интервалов в пользу порядковой шкалы сразу, не попробовав менее грубые преобразования. Апостериорные сравнения по Данн в рамках Краскела - Уоллиса не находят различий между интересующими группами, хотя р близко к 0,10. Проблему можно решить добрав животных, но я против такого, если можно статистикой. Кстати, недавно узнал, что правильно не "по Данну", а по "Данн", т.к. Олив Джин Данн - женщина)) ( https://en.wikipedia.org/wiki/Olive_Jean_Dunn ) и предложила метод в статье "Multiple Comparisons Using Rank Sums" в 1964 г. Если преобразовать сразу весь набор данных, то проблема с распределением остатков уходит, а с неоднородностью дисперсий нет. Поэтому можно использовать вариант п. Бокса - Кокса с одновременной нормализацией распределений и выравниванием дисперсий. Я умею делать такое только в очень старой программке, которую прикрепил. Она неудобная, копировать и вставлять данные из буфера получается только по одной колонке (есть такая опция в Edit), и забирать в буфер аналогично. Но она подобрала такую лямбду, что однородность дисперсий и нормальность остатков выполняются. Теперь имеем право трактовать результаты ANOVA и проводить апостериорные сравнения. Различия между интересующими группами статистически значимы: р=0,019 по Тьюки. Лечение работает, хотя до контроля далеко, эффект "бледный" (comisora). Сообщение отредактировал nokh - 24.09.2024 - 04:10
Эскизы прикрепленных изображений
Прикрепленные файлы
|
|||
|
|
|



|
|
Сообщений в этой теме
 Vitek_22 Сравнение трёх групп с большой разницей средних 21.09.2024 - 15:02
Vitek_22 Сравнение трёх групп с большой разницей средних 21.09.2024 - 15:02 ИНО Большая разница средник помехой быть не может, а т... 22.09.2024 - 11:35 comisora Цитата(Vitek_22 @ 21.09.2024 - 15:02... 22.09.2024 - 22:28
ИНО Большая разница средник помехой быть не может, а т... 22.09.2024 - 11:35 comisora Цитата(Vitek_22 @ 21.09.2024 - 15:02... 22.09.2024 - 22:28
 ИНО Цитата(nokh @ 24.09.2024 - 03:39) Дл... 24.09.2024 - 12:13 Vitek_22 Спасибо за такое развёрнутое объяснение.
Да... пр... 24.09.2024 - 22:23 ИНО Простые преподаватели бессильны сколь-нибудь сущес... 25.09.2024 - 01:11 Игорь Цитата(nokh @ 24.09.2024 - 04:39) Ко... 25.09.2024 - 10:29 ИНО То уже другая программа, там целая куча документов... 25.09.2024 - 16:44 Vitek_22 Цитата(ИНО @ 22.09.2024 - 11:35) Бол... 6.02.2025 - 19:28 nokh Цитата(Vitek_22 @ 6.02.2025 - 21:28)... 9.02.2025 - 09:11 Vitek_22 Цитата(nokh @ 9.02.2025 - 09:11) Как... 9.02.2025 - 22:02 Игорь Цитата(Vitek_22 @ 9.02.2025 - 22:02)... 27.02.2025 - 11:15 ИНО Цитата(Игорь @ 27.02.2025 - 11:15) Г... 2.03.2025 - 18:17 Игорь Цитата(ИНО @ 2.03.2025 - 18:17) По к... 6.03.2025 - 07:34 Vitek_22 Цитата(Игорь @ 27.02.2025 - 11:15) Н... 9.04.2025 - 16:46 ИНО Ну, если даже после консервативнейшей в мире попра... 7.02.2025 - 18:36 ИНО Ну, если ориентироваться в выборе статистических м... 10.02.2025 - 01:00 ИНО Не знаю, что там принято в доказательной медицине ... 7.03.2025 - 19:32
ИНО Цитата(nokh @ 24.09.2024 - 03:39) Дл... 24.09.2024 - 12:13 Vitek_22 Спасибо за такое развёрнутое объяснение.
Да... пр... 24.09.2024 - 22:23 ИНО Простые преподаватели бессильны сколь-нибудь сущес... 25.09.2024 - 01:11 Игорь Цитата(nokh @ 24.09.2024 - 04:39) Ко... 25.09.2024 - 10:29 ИНО То уже другая программа, там целая куча документов... 25.09.2024 - 16:44 Vitek_22 Цитата(ИНО @ 22.09.2024 - 11:35) Бол... 6.02.2025 - 19:28 nokh Цитата(Vitek_22 @ 6.02.2025 - 21:28)... 9.02.2025 - 09:11 Vitek_22 Цитата(nokh @ 9.02.2025 - 09:11) Как... 9.02.2025 - 22:02 Игорь Цитата(Vitek_22 @ 9.02.2025 - 22:02)... 27.02.2025 - 11:15 ИНО Цитата(Игорь @ 27.02.2025 - 11:15) Г... 2.03.2025 - 18:17 Игорь Цитата(ИНО @ 2.03.2025 - 18:17) По к... 6.03.2025 - 07:34 Vitek_22 Цитата(Игорь @ 27.02.2025 - 11:15) Н... 9.04.2025 - 16:46 ИНО Ну, если даже после консервативнейшей в мире попра... 7.02.2025 - 18:36 ИНО Ну, если ориентироваться в выборе статистических м... 10.02.2025 - 01:00 ИНО Не знаю, что там принято в доказательной медицине ... 7.03.2025 - 19:32 |