Здравствуйте, гость ( Вход | Регистрация )

  |

 21.09.2024 - 15:02 21.09.2024 - 15:02
Сообщение
#1
|
|
|
Группа: Пользователи Сообщений: 30 Регистрация: 7.12.2012 Пользователь №: 24440 |
Товарищи, подсобите с анализом данных.
3 группы мышей: контроль, больные, леченные. Измерялось пройденное расстояние. Мыши с тяжёлыми двигательными нарушениями, поэтому по сравнению с контролем у них пройденное расстояние отличается на порядок. ANOVA и Tukey апостериорный показывают значимые отличия от контроля. но не между больными и леченными, хотя объективно между ними x2 разница. Интуиция подсказывает, что с такой разницей между средними сравнивать ANOVA некорректно. Но чем тогда и как это объяснить грамотно и какой критерий использовать? Если Стьюдента попарно использовать - выходит норм.
Прикрепленные файлы
|
 |
 
|



 |
|
|
22.09.2024 - 11:35
Сообщение
#2
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Большая разница средник помехой быть не может, а только лишь наоборот. Но в Вашем случае разница (между второй и третьей группами) не шибко большая и выборки - тоже. Но главная проблема в том, что диаграммы остатков линейной модели говорят о невыполнении всех допущений ДА (ненормальность, гетероскедастичность, "выбросы"). Причем все это настолько выражено, что сомнительно, есть ли вообще какой-то смысл трактовать результаты данного анализа. Какую-нибудь теоретически обоснованную коррекцию модели или трансформацию данных здесь придумать сложно (по крайней мере, мне), так что непараметрика представляется единственным разумным путем. Еще советую подумать: действительно ли необходимы все три сравнения, или хватит двух (между контролем и больными, а также между больными и пролеченными).
|
|
|
|

|
|
|
22.09.2024 - 22:28
Сообщение
#3
|
||
|
Группа: Пользователи Сообщений: 109 Регистрация: 27.12.2015 Пользователь №: 27815 |
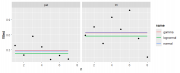
Цитата(Vitek_22 @ 21.09.2024 - 15:02)  Товарищи, подсобите с анализом данных. А почему бы не рассмотреть зависимую переменную как неотрицательную величину, пик которой будет ближе к нулю, а хвосты распределения будут говорить о самых дохлых и самых выносливых мышках? Взял три модели: нормальное распределение, логнормальное и гамма. Результаты в листинге. Отношение между контролем и лечением около 2.0-2.5 (1/0.45 - 1/0.41). Много это или мало - решать Вам, но в сравнении со здоровыми это всё очень бледно смотрится. CODE library(tidyverse) library(gamlss) dat <- readxl::read_excel('YandexDisk/Data1.xlsx') |> mutate(across(where(is.character), ~as.factor(.))) |> as.data.frame() fit1 <- gamlss(value~group, data = dat, family = NO()) fit2 <- gamlss(value~group, data = dat, family = LOGNO2()) fit3 <- gamlss(value~group, data = dat, family = GAF()) df.pred <- data |> mutate( normal = predict(fit1, type = 'response', newdata = dat), lognormal = predict(fit2, type = 'response', newdata = dat), gamma = predict(fit3, type = 'response', newdata = dat) ) perf <- performance::compare_performance(fit1,fit2,fit3) pl <- df.pred |> pivot_longer(cols = c(normal, lognormal, gamma), values_to = 'fitted') |> ggplot() + geom_line(aes(x = n, y = fitted, color = name), linewidth = 1, alpha = 0.75) + geom_point(aes(x = n, y = value)) + facet_grid(name~group) posthoc1 <- pairs(emmeans::emmeans(fit1, ~group)) posthoc2 <- pairs(emmeans::emmeans(fit2, ~group, type = 'response')) posthoc3 <- pairs(emmeans::emmeans(fit3, ~group, type = 'response')) perf Name | Model | AIC (weights) | AICc (weights) | BIC (weights)| Sigma ------------------------------------------------------------------------------ fit1 | gamlss | 58.3 (<.001) | 60.5 (<.001) | 62.9 (<.001) | 1.627 fit2 | gamlss | 42.2 (0.003) | 44.4 (0.006) | 46.8 (0.006) | 1.342 fit3 | gamlss | 30.7 (0.997) | 34.3 (0.994) | 36.4 (0.994) | 1.073 posthoc1 contrast estimate SE df t.ratio p.value hc - pat 7.738 0.374 19 20.695 <.0001 hc - trt 7.362 0.361 19 20.382 <.0001 pat - trt -0.375 0.374 19 -1.004 0.5834 P value adjustment: tukey method for comparing a family of 3 estimates posthoc2 contrast ratio SE df null z.ratio p.value hc / pat 33.680 8.1281 Inf 1 14.573 <.0001 hc / trt 13.782 3.2133 Inf 1 11.252 <.0001 pat / trt 0.409 0.0988 Inf 1 -3.702 0.0006 P value adjustment: tukey method for comparing a family of 3 estimates Tests are performed on the log scale posthoc3 contrast ratio SE df null z.ratio p.value hc / pat 27.87 6.648 Inf 1 13.948 <.0001 hc / trt 12.55 2.025 Inf 1 15.677 <.0001 pat / trt 0.45 0.123 Inf 1 -2.931 0.0095 P value adjustment: tukey method for comparing a family of 3 estimates Tests are performed on the log scale
Эскизы прикрепленных изображений
Прикрепленные файлы
|
|
|
|
|
|
|
|
24.09.2024 - 03:39
Сообщение
#4
|
||||
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
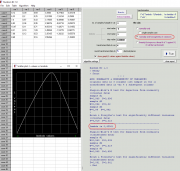
Как уже написал ИНО, требования модели дисперсионного анализа не выполняются: по критерию Левене (или как его по-русски) дисперсии неоднородны, по критерию Шапиро - Уилка остатки распределены ненормально. Прикрепил скриншоты анализа в бесплатном пакете PAST ( https://www.nhm.uio.no/english/research/resources/past/ ), который кстати в ряде моментов умеет больше чем Statistica, хотя сравнивать пакеты сложно, ввиду разных весовых категорий и назначения.
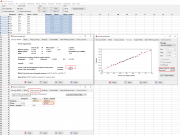
А вот с преобразованиями я бы поработал. Когда нужное преобразование неизвестно исходя из теории, можно использовать степенное преобразование Бокса - Кокса, которое приближает распределение данных к нормальному настолько, насколько позволяют сами данные. Это достигается итерационным подбором параметра лямбда. Преобразование многократно обсуждалось на форуме, но давно это было. Идея здесь такая, что мы можем либо 1) подбирать к нашим данным более подходящую статистическую модель, либо 2) преобразовать наши данные к статистической модели. Чисто философски что лучше 1) или 2) сказать нельзя, поскольку, скажем, если природа данных говорит, что площадь биологического объекта распределена ненормально, а квадратный корень из площади нормально, то естественно работать с квадратным корнем. Или если природа измеряет многие зависящие от скорости процессы скорее логарифмической линейкой, то и нам пользоваться ей естественно (скорость прямой реакции имеет ограничение варьирования слева, т.к. там зона нуля и отрицательных величин, а вправо варьировать можно: получается положительно асимметричное распределение, часто близкое к логнормальному). Для больших любителей непараметрики можно написать, что распространённые ранговые модели может и более универсальны, но не нужно забывать, что там данные тоже преобразуются, причём очень грубо - просто к порядковым местам, рангам. И если мы не видим, как такое преобразование делает статпакет для критерия Манна - Уитни или Краскела - Уоллиса, то это значит просто, что мы не считали критерии вручную и не знаем как работают эти методы. Короче, я за то, чтобы не отказываться от шкалы отношений или интервалов в пользу порядковой шкалы сразу, не попробовав менее грубые преобразования. Апостериорные сравнения по Данн в рамках Краскела - Уоллиса не находят различий между интересующими группами, хотя р близко к 0,10. Проблему можно решить добрав животных, но я против такого, если можно статистикой. Кстати, недавно узнал, что правильно не "по Данну", а по "Данн", т.к. Олив Джин Данн - женщина)) ( https://en.wikipedia.org/wiki/Olive_Jean_Dunn ) и предложила метод в статье "Multiple Comparisons Using Rank Sums" в 1964 г. Если преобразовать сразу весь набор данных, то проблема с распределением остатков уходит, а с неоднородностью дисперсий нет. Поэтому можно использовать вариант п. Бокса - Кокса с одновременной нормализацией распределений и выравниванием дисперсий. Я умею делать такое только в очень старой программке, которую прикрепил. Она неудобная, копировать и вставлять данные из буфера получается только по одной колонке (есть такая опция в Edit), и забирать в буфер аналогично. Но она подобрала такую лямбду, что однородность дисперсий и нормальность остатков выполняются. Теперь имеем право трактовать результаты ANOVA и проводить апостериорные сравнения. Различия между интересующими группами статистически значимы: р=0,019 по Тьюки. Лечение работает, хотя до контроля далеко, эффект "бледный" (comisora). Сообщение отредактировал nokh - 24.09.2024 - 04:10
Эскизы прикрепленных изображений
Прикрепленные файлы
|
|||
|
|
|


|
|
|
24.09.2024 - 12:13
Сообщение
#5
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Цитата(nokh @ 24.09.2024 - 03:39) Для больших любителей непараметрики можно написать, что распространённые ранговые модели может и более универсальны, но не нужно забывать, что там данные тоже преобразуются, причём очень грубо - просто к порядковым местам, рангам. Но заметьте, что при этом и формулировка проверяемой гипотезы значительно изменяется. Отсюда следует, что любое преобразование данных перед применением критерия влечет за собой преобразование гипотез. И если, например, в проверке гипотез о равенстве математических ожиданий квадратных или кубических корней измеряемых величин может иметься глубокий теоретический смысл, то сформулировать гипотезу, проверяемую после преобразования Бокса-Кокса лично я не в силах... |
|
|
|
|
|
|
24.09.2024 - 22:23
Сообщение
#6
|
|
|
Группа: Пользователи Сообщений: 30 Регистрация: 7.12.2012 Пользователь №: 24440 |
Спасибо за такое развёрнутое объяснение.
Да... пришёл к выводу, что надо где-то курсы статистики пройти, ибо просто использую то, что знаю, не особо разбираясь как оно работает... Но так преподавали, ужасно. Если здесь есть преподаватели - меняйте что-то для медиков/биологов. У нас на лекциях и практике по статистике были совершенно оторванные от реальности примеры, какие-то ёжики в лесу, тарелки супа и т.д.)) |
|
|
|
|
|
|
25.09.2024 - 01:11
Сообщение
#7
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Простые преподаватели бессильны сколь-нибудь существенно поменять программу дисциплины, составляемую в министерстве недалекими и безответственными чиновниками.
|
|
|
|
|
|
|
25.09.2024 - 10:29
Сообщение
#8
|
|
 Группа: Пользователи Сообщений: 1162 Регистрация: 10.04.2007 Пользователь №: 4040 |
Цитата(nokh @ 24.09.2024 - 04:39) Когда нужное преобразование неизвестно исходя из теории, можно использовать степенное преобразование Бокса - Кокса, которое приближает распределение данных к нормальному настолько, насколько позволяют сами данные. Ничего, что после преобразования данные, кроме контроля, стали отрицательными?Цитата(ИНО @ 25.09.2024 - 02:11) Простые преподаватели бессильны сколь-нибудь существенно поменять программу дисциплины, составляемую в министерстве недалекими и безответственными чиновниками. Программа составляется преподавателем в соответствии с утвержденными учебными планами, одобряется на заседании кафедры и утверждается проректором по учебной работе.
Сообщение отредактировал Игорь - 25.09.2024 - 11:31  Ebsignasnan prei wissant Deiws ainat! As gijwans! Sta ast stas arwis!
|
|
|
|
|
|
|
25.09.2024 - 16:44
Сообщение
#9
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
То уже другая программа, там целая куча документов с названием "програма", я уж забыл как в точности какой называется - два года не преподаю. Но то, что спускают из министерства, кажись, называется "примерная программа", и там все темы занятий и все вопросы, входящие в курс, перечислены. Преподаватель только лишь разбивает по парам в соответствии с количеством часов, выделенных на предмет в конкретном учебном заведении, а затем наращивает на этот скелет мясо в виде конкретных лекций, методичек по лабораторным и прочего. Что-то выбрасывать или свое добавлять, или даже порядок менять при этом нельзя. А скелет оный бывает таковым, что на голову не оденешь. Например, наши республиканские образовательные министервы, ежегодно тупо рандомно тасовали вопросы по темам, та к что в один из годов оказалось, что оплодотворение нужно проходить на месяц раньше, чем мейоз, а из темы о строении клетки выкинут вопрос о ядре.
Естественно, б. м. ответственные (перед студентами и собственно совестью) преподаватели, на такие выкрутасы министерв забивают и читают то, что надо, а не то, что предписано. Но бывают такие ситуации, что всякими проверками так затрахивают, что во избежания выговора, а то и увольнения преподаватель вынужден потакать болезненным фантазиям министерв и читать в точности предписанную хрень в ущерб интересам студентов. Конечно, многое зависит от региональных властей, хочется надеяться что Москве и Питере, все не так ужасно, как в ДНР. Сообщение отредактировал ИНО - 25.09.2024 - 16:46 |
|
|
|
|
|
|
6.02.2025 - 19:28
Сообщение
#10
|
|
|
Группа: Пользователи Сообщений: 30 Регистрация: 7.12.2012 Пользователь №: 24440 |
Цитата(ИНО @ 22.09.2024 - 11:35) Большая разница средник помехой быть не может, а только лишь наоборот. Товарищи, или Statistica v.12 врёт или большая разница средних при множественном сравнении играет очень большую роль.  разобраться, как так может быть? разобраться, как так может быть?Считаем по тем же исходным данным (1 сообщение): F2,20=247,369502 p=7,88258347E-15. Апостериорный тест Тьюки выдаёт между группой болезнь и болезнь+лечение p=0,62448764. При этом отличие от контроля, само-собой, стат значимое p= 0,000144741021 Теперь сотворим чудо, уменьшим показатели контроля в 10 раз, при этом совершенно не трогаем выборки "болезнь" и "лечение". Что выдаёт таже ANOVA + Тьюки: F2,20=12,0762702 p=0,000363699747, Тьюки даёт между группами "болезнь" и "болезнь+лечение" p=0,00710845035, а вот между лечением и контролем уже нет стат разницы p= 0,353486566 (конечно, потому что мы в 10 раз занизили показатель контроля) Выходит, что большая разница средних между контролем и другими группами искажает результат? Я считаю, абсолютно корректно сравнить группы попарно Стьюдентом и применить поправку бонферрони, тогда между "болезнь" и "болезнь+лечение" p=0,0109303586 и это значимо! <0.016 Получается, что для того, чтобы получить стат.значимость между целевыми группами, надо, чтобы лечение не отличалось от контроля, я не против такого лечения! но в реальности такое часто не достижимо, к примеру, в моём случае это трансгенные мыши, которых в принципе невозможно вылечить (фармой) и поэтому большая разница между контролем и экспериментальными группами - вполне нормальна, особенно в терминальнйо стадии заболевания. И лечение улучшило один из показателей в 2 раза. Сообщение отредактировал Vitek_22 - 6.02.2025 - 19:34 |
|
|
|
|
|
|
7.02.2025 - 18:36
Сообщение
#11
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Ну, если даже после консервативнейшей в мире поправки Бонферрони значимые различия остаются, то нет причин ей не пользоваться. Но к самому тесту, подвергаемому оной поправке, остается вопрос, поскольку, как было показано ранее, для классического Студента допущения не выполняются, да и для Уэлча - не особо.
Данные заново не пересчитывал, извините. Так что врет "Статистика", или не врет, не отвечу. Из всей Вашей задачи запомнил только, что данные там сильно ненормальны и гетероскедастичны, поэтому теоретически обязана врать, не в смысле алгебраических ошибок, а в смысле применимости критерия к данным. |
|
|
|
|
|
|
9.02.2025 - 09:11
Сообщение
#12
|
|
|
Группа: Пользователи Сообщений: 1219 Регистрация: 13.01.2008 Из: Челябинск Пользователь №: 4704 |
Цитата(Vitek_22 @ 6.02.2025 - 21:28) Товарищи, или Statistica v.12 врёт или большая разница средних при множественном сравнении играет очень большую роль. разобраться, как так может быть?Считаем по тем же исходным данным (1 сообщение): F2,20=247,369502 p=7,88258347E-15. Апостериорный тест Тьюки выдаёт между группой болезнь и болезнь+лечение p=0,62448764. При этом отличие от контроля, само-собой, стат значимое p= 0,000144741021 Теперь сотворим чудо, уменьшим показатели контроля в 10 раз, при этом совершенно не трогаем выборки "болезнь" и "лечение". Что выдаёт таже ANOVA + Тьюки: F2,20=12,0762702 p=0,000363699747, Тьюки даёт между группами "болезнь" и "болезнь+лечение" p=0,00710845035, а вот между лечением и контролем уже нет стат разницы p= 0,353486566 (конечно, потому что мы в 10 раз занизили показатель контроля) Выходит, что большая разница средних между контролем и другими группами искажает результат? Я считаю, абсолютно корректно сравнить группы попарно Стьюдентом и применить поправку бонферрони, тогда между "болезнь" и "болезнь+лечение" p=0,0109303586 и это значимо! <0.016 Получается, что для того, чтобы получить стат.значимость между целевыми группами, надо, чтобы лечение не отличалось от контроля, я не против такого лечения! но в реальности такое часто не достижимо, к примеру, в моём случае это трансгенные мыши, которых в принципе невозможно вылечить (фармой) и поэтому большая разница между контролем и экспериментальными группами - вполне нормальна, особенно в терминальнйо стадии заболевания. И лечение улучшило один из показателей в 2 раза. Какой-то беспредел... Человеку написали, что нужно делать, почему и даже в чём. Вам нужно не в статистике разобраться, а научиться принимать помощь - это более универсальная компетенция, ещё много где пригодится. |
|
|
|
|
|
|
9.02.2025 - 22:02
Сообщение
#13
|
|
|
Группа: Пользователи Сообщений: 30 Регистрация: 7.12.2012 Пользователь №: 24440 |
Цитата(nokh @ 9.02.2025 - 09:11) Какой-то беспредел... Человеку написали, что нужно делать, почему и даже в чём. Вам нужно не в статистике разобраться, а научиться принимать помощь - это более универсальная компетенция, ещё много где пригодится. Уважаемый nokh, вы совершенно не понимаете реальность, в которой мы работаем. Это оффтоп, но я поясню Я очень ценю помощь и всё, что здесь изложили - принял к сведению. Поясняю, я не знал, есть ли ста. значимая разница и как это доказать. После вашего поста с преобразвоанием данных и расчётами (я особо не понял что там к чему) я понял, что стат. значимая разница есть и она вполне доказуема. Но! Если в статье биологической я начну писать, что данные "ненормальны и гетероскедастичны" (второе я даже не знаю что такоеи, честно, знать не хочу, - нельзя быть специалистом во всём), потом я эти данные так и так преобразовал... и нашёл стат. значимость - это красная тряпка для рецензента (зачастую, тоже не понимающего ничего в статистике, часто, понимающего даже меньше, чем я), и такая статья не пройдёт. Я же нашёл метод, который знает практически 99% потенциальных рецензентов, которые выдаёт тоже ста. значимость, на урвоне полученной вами. Т.е. я как бы нарушаю, но без последствий. Это разумный компромисс, который позволит мне не иметь 10 вопросов по статистике, на которые я сам не смогу ответить и бесплатно вряд ли кто-то за меня будет с рецензентом спорить! Првиеду вам пример, сравнивал я 3 выборки (норм. распределённые) ANOVA с последующим Тьюки. Рецензент пишет "вы должны обсчитать ваши данные двухфакторной ANOVA"? я отвечаю, что у меня один фактор воздействия, всего 3 выборки, даже если из забить в Statistica и попробовать посчитать двухфакторную ANOVA - выдаст ошибку, потому что не хватает факторов... их просто нет! И что? Реджектнули статью. Кто кому и что доказал? Поэтому в биологических статьях в серьезных журналах я буду считать Манном-Уитни, Стьюдентом, Ановой... общеизветсными тестами, и никаких преобразований данных. Возможно, в медицинских журналах, при проведении клинических испытаний... там всё серьезнее и люди более понимающие в статистике, там это норм. В тех журналах, куда я пишу - такое не примут)) сочтут за манипуляцию с целю выжать статистику и напишут, считайте ANOVA)) Из моей практики, приходит статья из Cell где 2 выборки n=5, посчитаны t-критерием Стьюдента. Не работает этот критерий с такими ультрамалыми выборками, но вы можете найти множество статей с такими данными и обработками, они выходят. Я, как раз набравшись тут ума, сделал им замечание и написал,что надо выбрать другой критерий. Что вы думаете? Они оставили те же самые значения p, но написали, что пересчитали критерием Фишера-Питмана)) Ещё одна статья пришла, считают ANOVA и Тьюки 3 выборки, в одной 3 животных, в двух других по 5)) Две рецензии пришли хорошие, третья была от меня. Журнал решил, что я прав, реджектнул статью, особенно это важно с учётом ответа на рецензию, где авторы тупо скинули 4 статьи где тоже на 3-4 животных посчитано ANOVA и написали, что так общепринято! И дело даже не в 3животных, а в том, что авторы нагло врали, но попались, т.к. в материалах и методах написано, что в группах по 7 животных, а когда они дали значение F-критерия, забыли подправить степени свободы, и по ним то видно, что там не 7 в группах)) С данными, с которых началось это обсуждение, я давно закончил. Мой вопрос в другом, я не понимаю, почему попарное сравнение даёт статистику, а то же самое (выбирается post-hoc Бонферрони) при обсчёте ANOVA - не даёт статистику. Мне кажется, это именно алгебраическая ошибка в программе, но моих знаний не хватает рассчитать вручную и проверить, кто прав... Т.е. это не вопрос "как обсчитывать статистику по этим данные", основной вопрос был закрыт вами давно и я очень благодарен за ответ! Сообщение отредактировал Vitek_22 - 9.02.2025 - 22:08 |
|
|
|
|
|
|
10.02.2025 - 01:00
Сообщение
#14
|
|
|
Группа: Пользователи Сообщений: 290 Регистрация: 1.06.2022 Из: Донецк Пользователь №: 39632 |
Ну, если ориентироваться в выборе статистических методов на уровень знаний 90% рецензентов российских биологических журналов, то ой... Однако рецензента Вы не зря боитесь, посокльку на его вопросы по существу методики ответить, вероятно, не сможете.
А реальность в которой Вы работаете, широко известна: статистике в биологических вузах обучают в рамках "Стьюдент - Вилкокосон", а рамки "Дисперсионный анализ - Критерий Краскела - Уоллиса" - это уже уровень "со звездочкой". А за этими рамками - темный лес, в котором 90% биологов, включая числе рецензентов журналов, не секут ни хрена. И у Вас из этой ситуации есть два альтернативных выхода: 1) активно заниматься самообразованием, что включаемый себя не только расспросы на форуме раз в полгода, но и чтение серьезных объемов литературы, в том числе на нерусских языках, или б) сменить область научных интересов на ту, куда широкое внедрение статистического анализа пока что не дошло, по крайней мере, в России. Например, на флористику или фаунистику. Многие люди по сей день успешно защищают кандидатские и докторские диссертации на одной только инвентаризации биоты заповедных территорий, скрупулезной, но не обремененной математичесикими вычислениями за рамками арифметики уровня 1-го класса начальной школы (тупо подсчитать сколько видов живых организмов целевого таксона найдено на исследованной территории, и сколько из них - впервые). |
|
|
|
|
|
|
27.02.2025 - 11:15
Сообщение
#15
|
|
|
Группа: Пользователи Сообщений: 1162 Регистрация: 10.04.2007 Пользователь №: 4040 |
Цитата(Vitek_22 @ 9.02.2025 - 22:02) данные "ненормальны и гетероскедастичны" (второе я даже не знаю что такоеи, честно, знать не хочу, - нельзя быть специалистом во всём) Гетероскедастичность - неоднородность дисперсии. Ее проверяют перед применением регрессионного анализа. Кстати, не понимаю, зачем используют кальки с иностранных терминов, если есть понятные аналоги. Но дело не в этом, а в том, где взять информацию по данной теме. В теме, посвященной нейронным сетям, я уже кратко отмечал, что выбор литературы крайне ограничен, несмотря на обилие отечественных, иностранных и переводных источников. Поясню, какие требования я выдвигаю к источникам: 1. Понятное описание алгоритма (хотя требование несколько субъективное, но тем не менее). 2. Полный набор расчетных формул (можно без вывода, но со ссылками), позволяющий [при необходимости] запрограммировать алгоритм. 3. Полный тестовый пример, включая исходные данные (!), результаты расчета и выводы. Желательно, чтобы это была монография, а не тезисы конференции, инструкция к программе или рабочие заметки. Привязка к какому-либо языку программирования или программному продукту заставляет усомниться в полезности источника (исключения редки). Лучше, если оригинал будет издан на английском языке зарубежным издательством и будет перевод на русский язык (установить соответствие или найти перевод поможет данный ресурс). Проведя отсев по предлагаемым критериям, устанавливаем, что по гетероскедастичности имеется только один источник - Доугерти "Введение в эконометрику". P.S. Ресурсы Интернета в настоящий момент утратили актуальность и содержат не саму информацию, а направления для дальнейшего поиска, хотя и это бывает проблемой (могут даваться ссылки только на собственные работы авторов публикаций либо на доступные, но неудачные источники). P.P.S. А не нужно быть "специалистом во всём". Например, в диссертации по медико-биологическим наукам применяются научно-клинические (ведение пациентов и т.д.), физиологические, биохимические, радиологические, статистические и другие методы, вплоть до механики и электроники. Не получится быть специалистом во всех дисциплинах. Часть исследований - самостоятельные, часть - в соавторстве, часть - вообще заказные. Это нормально. Сообщение отредактировал Игорь - 1.03.2025 - 09:22 Ebsignasnan prei wissant Deiws ainat! As gijwans! Sta ast stas arwis!
|
|
|
|
|
|
|